Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Entscheidungstheorie
Entscheidungstheorie

2
Erkenntnisziele der Entscheidungstheorie
Erkenntnisziele der Entscheidungstheorie Definitionen: a) logische Analyse rationalen und intendiert rationalen Verhaltens (normative Theorie und deskriptive Theorie) b) Empirische Analyse intendiert rationalen Verhaltens (deskriptive Theorie)
 logische Analyse rationalen und intendiert rationalen Verhaltens (normative Theorie und deskriptive Theorie) b) Empirische Analyse intendiert rationalen Verhaltens (deskriptive Theorie)")
3
Entscheidungstheorie
Logische Analyse - Rationales Verhalten (normative Theorie) - intendiert rationales Verhalten (Logische Untersuchungen über Abweichungen des intendiert rationalen Verhaltens vom rationalem Verhalten. (Verhaltenstheoretische Ansätze) Empirische Analyse Experimente und Untersuchungen über tatsächliches Verhalten von Entscheidungs- trägern und Auswertung dieser Ergebnisse. Deskriptive Theorie
 - intendiert rationales Verhalten (Logische Untersuchungen über Abweichungen des intendiert rationalen Verhaltens vom rationalem Verhalten. (Verhaltenstheoretische Ansätze) Empirische Analyse. Experimente und Untersuchungen über tatsächliches Verhalten von Entscheidungs- trägern und Auswertung dieser Ergebnisse. Deskriptive Theorie.")
4
Modell des Entscheidungsprozesses
Objektsystem: Entscheidungsfeld Umweltgesetze Vermittlung subjektiven Situationsbildes Informationen Handlungen Informationssystem Entscheidungslogik Zielsystem Subjektsystem

5
Definition einer normativen Entscheidungstheorie
Analyse von Entscheidungen bei subjektiver Formalrationalität (Rationalitätsbegriff bestimmt die Variationen) a) Unterscheidungskriterium: Entscheidungsinhalte - Formale Rationalität: widerspruchsfreies Zielsystem Zielsystemkonformes Verhalten - Substantielle Rationalität (anerkanntes Ent- scheidungsverhalten in Individuengruppen)
 a) Unterscheidungskriterium: Entscheidungsinhalte. - Formale Rationalität: widerspruchsfreies Zielsystem. Zielsystemkonformes Verhalten. - Substantielle Rationalität (anerkanntes Ent- scheidungsverhalten in Individuengruppen)")
6
b) Unterscheidungskriterium:
Faktische Entscheidungsprämissen - objektive Rationalität: Subjektives Situationsbild entspricht objektiven Umständen - Subjektive Rationalität: subjektives Bild ist Ausgangspunkt der Betrachtungen

7
Deskriptive Entscheidungstheorie
a) Explikative Aufgabe: Definition und Begriffsbildung im betrachteten Bereich b) explanatorische Aufgabe: Erklärung der Entscheidungsergebnisse Elemente explanatorischer Aussagen: 1) Explanadum: Menge beschriebener und empirisch gewonnener Begriffe in dem zu erklärenden Sachverhalt 2) Explanans: a) Gesetz zur Erklärung des Sachverhaltes b) Anfangsbedingungen zur Ermittlung der Gesetzesaussagen im vorliegenden Fall
 Explikative Aufgabe: Definition und Begriffsbildung im betrachteten Bereich. b) explanatorische Aufgabe: Erklärung der Entscheidungsergebnisse. Elemente explanatorischer Aussagen: 1) Explanadum: Menge beschriebener und empirisch gewonnener Begriffe in dem zu erklärenden Sachverhalt. 2) Explanans: a) Gesetz zur Erklärung des Sachverhaltes. b) Anfangsbedingungen zur Ermittlung der Gesetzesaussagen im vorliegenden Fall.")
8
Beispiel: Erklärung steigender Unternehmensgewinne
Explanandum: Aussagen über Begriffe Umsatz, Gewinn, Investitionen u.a.m. Explanans: (statische und) kausale Abhängigkeit zwischen Umsatz, Gewinn, Investition u.a.m. Hierher: Versuch der Erklärung unternehmerischer Entscheidungen mit verhaltenswissenschaftlichen Analysen der kognitiven Prozesse der teilnehmenden Individuen. Stand: Versuch der Lösung der explikativen Aufgabe Geschlossenes Verhaltensmodell der Unternehmung: March, Cyert, Behavioral Theory of the Firm, 1963
 kausale Abhängigkeit zwischen Umsatz, Gewinn, Investition u.a.m. Hierher: Versuch der Erklärung unternehmerischer Entscheidungen mit verhaltenswissenschaftlichen Analysen der kognitiven Prozesse der teilnehmenden Individuen. Stand: Versuch der Lösung der explikativen Aufgabe. Geschlossenes Verhaltensmodell der Unternehmung: March, Cyert, Behavioral Theory of the Firm,")
9
Heuristisches Modell: Entscheidungsprozess: MODELL von R.M. Cyert u. J.G. March

10
Nein Ja Ja Nein

11
Problemlösungsstufen (betriebliche)
1) Zielbestimmung 2) Suche und Analyse von Alternativen im Hinblick auf die Konsequenzen in Handlungszielbeitragseinheiten 3) Auswahl einer Alternative und Festlegung der Aktionen 4) Sollvorgabe 5) Realisation 6) Soll-Ist-Vergleich
 Zielbestimmung. 2) Suche und Analyse von Alternativen im Hinblick auf die Konsequenzen in Handlungszielbeitragseinheiten. 3) Auswahl einer Alternative und Festlegung der Aktionen. 4) Sollvorgabe. 5) Realisation. 6) Soll-Ist-Vergleich.")
12
1) 2) Planungsstufen 3) Eigentliche Entscheidung 4) 5) Organisation (funktionale Begriffsversion) 6) Kontrolle
 Kontrolle.")
13
Zugehörige Informationsprozesse Informationsbedarfsermittlung
Planungsphasenteilprozesse 1), 2), 3) 1) Problemformulierung 2) Handlungszielbestimmung 3) Alternativenplanung a) Handlungsalternativensuche b) Umweltkonstellationsfestlegung 4) Datenpräzisierungsprozess 5) Planungsrechnung 6) Entscheidung i.e.S. 7) Sollvorgabe Zugehörige Informationsprozesse Informationsbedarfsermittlung Informationszielsetzung Such- und Orientierungsprozesse Informationsprüfungs-, Aufbereitungs- und Abstimmungsprozess, Informationsverarbeitungskalkül-wahl Informationsgewichtung und Informationsbewertung (Kriterium) Informationsweitergabe und Informationsspeicherung
, 2), 3) 1) Problemformulierung. 2) Handlungszielbestimmung. 3) Alternativenplanung. a) Handlungsalternativensuche. b) Umweltkonstellationsfestlegung. 4) Datenpräzisierungsprozess. 5) Planungsrechnung. 6) Entscheidung i.e.S. 7) Sollvorgabe. Zugehörige Informationsprozesse. Informationsbedarfsermittlung. Informationszielsetzung. Such- und Orientierungsprozesse. Informationsprüfungs-, Aufbereitungs- und Abstimmungsprozess, Informationsverarbeitungskalkül-wahl. Informationsgewichtung und. Informationsbewertung (Kriterium) Informationsweitergabe und. Informationsspeicherung.")
14
Entscheidungsbeispiel Numerisches Beispiel
Einem Taxiunternehmer mit 1 PKW werde sehr günstig ein PKW vom Typ Mercedes 240D angeboten. Dieser Unternehmer überlegt, ob er diesen PKW erwerben soll. Problem: Wird dieser PKW ausgelastet sein, und welche Kosten verursacht diese Vergrößerung? Der Unternehmer steht vor folgenden Alternativen:

15
a) PKW anschaffen und Tagesbetrieb
b) PKW anschaffen und Tag- und Nachtbetrieb (reiner Nachtbetrieb scheide als ungünstiger als Tagesbetrieb aus) c) PKW nicht anschaffen Weiter sei dem Unternehmer bekannt, dass eine Gesetzesvorlage der Revision der Abschreibung für Firmen-PKW u.U. durchgesetzt werde, wodurch seine Tagesauslastung um 30 % erhöht würde.
 PKW anschaffen und Tag- und Nachtbetrieb (reiner Nachtbetrieb scheide als ungünstiger als Tagesbetrieb aus) c) PKW nicht anschaffen. Weiter sei dem Unternehmer bekannt, dass eine Gesetzesvorlage der Revision der Abschreibung für Firmen-PKW u.U. durchgesetzt werde, wodurch seine Tagesauslastung um 30 % erhöht würde.")
16
Es seien ihm folgende Zahlen bekannt:
derzeitige durchschnittliche monatliche Aus- lastung (Tagesbetrieb): 5000 km Fixkosten p.a.: € ,-- Variable Kosten je km: € 0,40 Durchschnittlicher Erlös p.a.: € ,--
: 5000 km. Fixkosten p.a.: € ,-- Variable Kosten je km: € 0,40. Durchschnittlicher Erlös p.a.: € ,--")
17
Würde er den 2. PKW anschaffen, so erhöhen sich seine Fixkosten um € 9
Würde er den 2. PKW anschaffen, so erhöhen sich seine Fixkosten um € 9.000,-- und seine variablen Kosten betragen (Diesel!) € 0,35 je km für diesen PKW. Die Nachtauslastung betrage ca. 40 % der Tagesauslastung. Die variablen Kosten betragen bei einer Nachtschicht € 0,60 je km. Die Fixkosten erhöhen sich bei einer Nachtschicht um € 3.000,--p.a. Die Tagesauslastung entspricht jener des existierenden PKW´s. (Die Erlöse f(x) seien eine lineare Funktion der gefahrenen km f(x) = 0,8 * x). Ein Nachtbetrieb mit dem bereits vorhandenen PKW ist nicht möglich!
 € 0,35 je km für diesen PKW. Die Nachtauslastung betrage ca. 40 % der Tagesauslastung. Die variablen Kosten betragen bei einer Nachtschicht € 0,60 je km. Die Fixkosten erhöhen sich bei einer Nachtschicht um € 3.000,--p.a. Die Tagesauslastung entspricht jener des existierenden PKW´s. (Die Erlöse f(x) seien eine lineare Funktion der gefahrenen km. f(x) = 0,8 * x). Ein Nachtbetrieb mit dem bereits vorhandenen PKW ist nicht möglich!")
19
Modellbegriff und Entscheidungsmodelle
Modell: Abbildung einer Realität unter Reduktion der Anzahl der einfließenden Größen unter Beibehaltung der Struktur der Realität. also: a) Modell ist realitätsvereinfachend b) Modell soll strukturgleich bzw. strukturähnlich sein. Man bildet aggregierte Größen, die unter spezieller Aufgabenstellung in Beziehung gesetzt werden und ein realitätstreues Verhalten zeigen sollen:
 Modell ist realitätsvereinfachend. b) Modell soll strukturgleich bzw. strukturähnlich sein. Man bildet aggregierte Größen, die unter spezieller Aufgabenstellung in Beziehung gesetzt werden und ein realitätstreues Verhalten zeigen sollen:")
20
Def. Bamberg/Coenenberg:
„Modell ist eine zweckorientierte relationstreue Abbildung der Realität“ Zweckorientierung: Bestimmt Aggregation und Struktur des Modells Bsp: Investitionsmodell (Ziel: Maximierung des Differenzgewinns) Interessierende Größen: Kosten- und ertragswirksame Größen (Cash Flow) ZB wird Umweltverschmutzung durch ein Aggregat im gesetzlich zulässigen Rahmen ausgeklammert!
 Interessierende Größen: Kosten- und ertragswirksame Größen (Cash Flow) ZB wird Umweltverschmutzung durch ein Aggregat im gesetzlich zulässigen Rahmen ausgeklammert!")
21
Unterteilung des Modellbegriffs nach dem
Zweck der Modellbildung: a) Beschreibungsmodelle (Zielbeschreibung, Aktionsbeschreibung) b) Erklärungsmodelle bzw. Prognosemodelle (Konsequenzenanalyse; Zweck-Mittel- Analyse) c) Entscheidungsmodelle (Aktionen und Umweltkonstellationen bestimmen die Konsequenzen; Ziele bestimmen über die Konsequenzen die Aktionswahl)
 Beschreibungsmodelle (Zielbeschreibung, Aktionsbeschreibung) b) Erklärungsmodelle bzw. Prognosemodelle (Konsequenzenanalyse; Zweck-Mittel- Analyse) c) Entscheidungsmodelle (Aktionen und Umweltkonstellationen bestimmen die Konsequenzen; Ziele bestimmen über die Konsequenzen die Aktionswahl)")
22
Grundbegriffe der Entscheidungstheorie
Entscheidungssubjekt (Individ. Entscheidungen) Entscheidungsträger Entscheidungsgremium: a) einheitliche Präferenzen (Team) b) indiv. abweichende Präferenzen
 Entscheidungsträger. Entscheidungsgremium: a) einheitliche Präferenzen. (Team) b) indiv. abweichende. Präferenzen.")
23
Grundbegriffe der Entscheidungstheorie
Entscheidungsfeld: A x Z A.....Aktionenraum (Menge der Handlungs- alternativen) Z.....Zustandsraum (Menge der Zustände der Umwelt, die die Konsequenzen der Aktionen beeinflussen, vom Entschei- dungträger selbst jedoch unabhängig sind!)
 Z.....Zustandsraum (Menge der Zustände. der Umwelt, die die Konsequenzen der. Aktionen beeinflussen, vom Entschei- dungträger selbst jedoch unabhängig. sind!)")
24
Grundbegriffe der Entscheidungstheorie
Mögliche Mächtigkeit von A und Z: endlich (rechenbar, „kaum“ rechenbar) abzählbar unendlich überabzählbar unendlich Aufstellungsprinzip für A: Prinzip der vollkommenen Alternativenstellung
 abzählbar unendlich. überabzählbar unendlich. Aufstellungsprinzip für A: Prinzip der vollkommenen Alternativenstellung.")
25
Information und Zustand
Informationssystem: Menge von Nachrichten yj (j=1,2,...,k) über mögliche Zustände zi Z (i= 1, 2, ...,n) und eine Struktur. Struktur eines Informationssystems: Wahrscheinlichkeiten wij (w (yj | zi); ( wij = 1)) k j
 über mögliche Zustände zi Z (i= 1, 2, ...,n) und eine Struktur. Struktur eines Informationssystems: Wahrscheinlichkeiten wij (w (yj | zi); ( wij = 1)) k. j.")
26
Überführung: w (yj | zi) in w (zj | yi)
Bayes´sches Theorem Bsp: Eine Sendung von 3 Stk eines Gutes sei angekommen. Es soll beurteilt werden, ob die Sendung zurückzuweisen ist. Informationssystem: Zufallsstichprobe von Umfang 1

27
Mögliche Zustände der Umwelt:
z0 = 0 Stück fehlerhaft z1 = 1 Stück fehlerhaft z2 = 2 Stück fehlerhaft z3 = 3 Stück fehlerhaft Menge der Nachrichten des Informationssystems: l1 „Ziehen einer Zufallsstichprobe von Umfang 1“: yj = Nachricht: „j Stück fehlerhaft“ (j = 0,1) Struktur des Informationssystems durch wij = w (yj | zi)
 Struktur des Informationssystems durch wij = w (yj | zi)")
28
gegeben: w (yj | zi) = i i j j 3 1
 = i 3-i j 1-j 3 1")
29
Rückschluss auf w(zi) mittels Bayes´schen Theorems:
a) Struktur des Bayes´schen Theorems 1) yj (j = 1, 2, ...,k) sind disjunkte Ereignisse 2) w (yj | zi) ist bekannt 3) A-priori-Wahrscheinlichkeiten w(zi) (i= 1, 2, .....,n) sind bekannt oder ermittelbar (subjektiv)
 Struktur des Bayes´schen Theorems. 1) yj (j = 1, 2, ...,k) sind disjunkte Ereignisse. 2) w (yj | zi) ist bekannt. 3) A-priori-Wahrscheinlichkeiten. w(zi) (i= 1, 2, .....,n) sind bekannt oder. ermittelbar (subjektiv)")
30
W(yj|zi) w (zi) W(AB) W(B) Wegen W(A|B) = gilt:
W (yj|zi) W (zi) = W (yj zi) also wegen: W(yj | zi) = 1 und disjunkten zi gilt: {i} W (yj) = W (yj | zi) W (zi) Also gilt: Bayes´sches Theorem: W (zi|yj) = ƒ(z|y) = W(yj|zi) w (zi) W(yj | zi) W(zi) {i} ƒ(y|z) ƒ(z) ƒ(y|z) ƒ(z) {z}
 W (zi) = W (yj zi) also wegen: W(yj | zi) = 1 und disjunkten zi gilt: {i} W (yj) = W (yj | zi) W (zi) Also gilt: Bayes´sches Theorem: W (zi|yj) = ƒ(z|y) = W(yj|zi) w (zi) W(yj | zi) W(zi) {i} ƒ(y|z) ƒ(z) ƒ(y|z) ƒ(z) {z}")
31
Darstellung eines Informationssystems:
(wij= w(yj | zi))
)")
32
1) Vollkommenes Informationssystem
 Vollkommenes Informationssystem")
33
2) Unvollkommenes Informationssystem a) k < n und w (yj | zi) = 1 oder 0 (partielle oder vollkommene Ungewissheit Sonderfall: Vollkommene Ungewissheit y1 z1 1 z2 1 zn 1

34
b) k < n , k = n oder k > n und w (yj | zi) [0,1] Bsp (k = n)
Risiko-situation ( = 1)
![b) k < n , k = n oder k > n und w (yj | zi) [0,1] Bsp (k = n)](http://slideplayer.org/slide/11848645/66/images/34/b%29+k+%3C+n+%2C+k+%3D+n+oder+k+%3E+n+und+w+%28yj+%7C+zi%29+%EF%83%8E+%5B0%2C1%5D+Bsp+%28k+%3D+n%29.jpg "Risiko-situation. ( = 1)")
35
Entscheidungsmatrix Die Ermittlung der Entscheidungsmatrix besteht in der Ermittlung der Funktionswerte x der Abbildung φ: φ : A x Z X A = Aktionsmenge Z= Menge der Zustände X = Menge der Handlungskonsequenzen (φ kann ein- oder mehrdeutig sein)
")
36
Darstellung eines Informationssystems:

37
a) φ ist eindeutig Für jedes Paar (ai, zj) gibt es genau ein xij X Bsp: Z sei der Anteil der fehlerhaften „Buchungen“ in der Prüfung der Buchführung einer AG A bestehe in der Erteilung (a1), der Verweigerung (a2) oder der eingeschränkten Erteilung (a3) des Bestätigungsvermerkes bei der Pflichtprüfung.
, der Verweigerung (a2) oder der eingeschränkten Erteilung (a3) des Bestätigungsvermerkes bei der Pflichtprüfung.")
38
b) φ ist mehrdeutig Risiko: Aktion: Werbepolitische Maßnahme Konsequenz: Umsatzveränderungen Zustände nur vereinfacht erfassbar, daher stochastische Beschreibung bei reduzierter Zustandsmenge Ungewissheit: Aktion: Errichtung eines Kernkraftwerkes Konsequenz: Umweltveränderungen hierdurch Stochastische bzw. unbekannte Zusammen- hänge der Aktionen mit den Zuständen der Umwelt.

39
Entscheidungssituationen

40
Zielsetzung des Entscheidungsproblems: Wahl der „besten“ Handlungsalternative Beispiel: Entscheidung unter Sicherheit Konsequenzen

41
Erforderlich daher: a) Präferenzen auf der Menge der Konsequenzen derart, dass ein ordinaler Nutzenindex ableitbar ist; (bis auf streng monotone Transformationen invariant). b) Da u.a. Unsicherheit bei Entscheidungen eingeht, muss es möglich sein, „Erwartungswerte“ zu bilden; daher: Forderung nach der Existenz einer Nutzen-funktion, die „erwartungstreu“ und bis auf positive lineare Transformationen eindeutig ist.
 Präferenzen auf der Menge der Konsequenzen derart, dass ein ordinaler Nutzenindex ableitbar ist; (bis auf streng monotone Transformationen invariant). b) Da u.a. Unsicherheit bei Entscheidungen eingeht, muss es möglich sein, „Erwartungswerte zu bilden; daher: Forderung nach der Existenz einer Nutzen-funktion, die „erwartungstreu und bis auf positive lineare Transformationen eindeutig ist.")
42
Eigenschaften von Relationen (X = {a, b, c, d})
1. Reflexivität: Es gilt für alle x X : xRx R 2. Irreflexivität: Es gilt für alle x X : aus xRy R folgt x y. Folge: keine Schleifen

43
3. Symmetrie: Gilt xRy R so gilt yRx R
a b c d 4. Asymmetrie: Gilt xRy R so gilt nicht yRx R a b (ist R asymmetrisch, so ist c d R irreflexiv)
")
44
5. Antisymmetrie: Gilt xRy R und yRx R, so folgt x=y. Bem
5. Antisymmetrie: Gilt xRy R und yRx R, so folgt x=y. Bem.: wie Asymmetrie, nur Schleifen erlaubt. 6. Transitivität: Gilt xRy R und yRz R so gilt xRz R Bsp: a b c d

45
7. Intransitivität: Gilt xRy R und yRz R, so gilt nicht xRz R (x y z)
Bsp: a b c d 8. Negative Transitivität: Gilt xRy R und yRz R, so gilt auch xRz R Bsp: a b c d

46
9. Zusammenhang: Für alle x, y X gilt xRy R oder (exklusiv) yRx R oder beides Bsp:
10. Schwacher Zusammenhang Für alle x,y X mit x y gilt xRy R oder (exklusiv) yRx R Bsp:
 yRx R. Bsp:")
48
Schwache Präferenzrelation auf der Menge der Konsequenzen
~ Sprich: für xi, xj X heißt xi xj xi werde xj nicht vorgezogen! Bemerkung: xi xj muss nicht heißen xj ist besser als xi; z.B. wenn man es nicht beurteilen kann Satz: Jede schwache Präferenzrelation auf X induziert eine Indifferenzrelation auf X. Bildung: x~y genau dann, wenn x y und y x. ~ ~ ~ ~

49
Beispiel: Taxiunternehmen untersucht ein Erweiterungsinvestitionsproblem bei Sicherheit. Es gelte:
x1 = Kauf eines Opel-Rekord 2100 D x2 = Kauf eines Mercedes 300 D x3= Kauf eines Alfa Romeo 2000 x4 = Kauf eines Mercedes 240 D x5 = Kauf eines Peugeot 504 D Durch gezielte Befragung sind folgende Präferenzen festgestellt worden (X = {x1, x2, x3, x4, x5}):
:")
50
x3 x3 x5 x4 x1 x1 x1 x2 x2 x2 x2 x4 x4 x4 x1 x5 x5 x5 x4 x2 x3 x1 x5 x1 x3 x2 x3 x5 x3 x4 x5 x2 x1 x4 ~ ~ a priori Annahme: Reflexivität ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ Ermitteln Sie die Äquivalenz-klassen der induzierten Äqui-valenzrelation! ~ ~ ~

51
Lösung: x3 x1 x5 x2 x4 Äquivalenzklassen (xi < xj und xj < xi): ~ ~ [x3] ~ = {x3} Quotientenmenge [x1] ~ = {x1, x5} [x2] ~ = {x2, x4}
![Lösung: x3. x1 x5. x2 x4. Äquivalenzklassen (xi < xj und xj < xi): ~ ~ [x3] ~ = {x3} Quotientenmenge [x1] ~ = {x1, x5}](http://slideplayer.org/slide/11848645/66/images/51/L%C3%B6sung%3A+x3.+x1+x5.+x2+x4.+%C3%84quivalenzklassen+%28xi+%3C+xj+und+xj+%3C+xi%29%3A+%7E+%7E+%5Bx3%5D+%7E+%3D+%7Bx3%7D+Quotientenmenge+%5Bx1%5D+%7E+%3D+%7Bx1%2C+x5%7D.jpg "[x2] ~ = {x2, x4}")
52
Äquivalenzrelation Eigenschaften: Reflexiv, symmetrisch, transitiv
Bsp: X = {1, 2, ..., 10} Es gelte xRy R wenn x, y X und x sowie y bei Division durch 3 denselben Rest aufweisen. Graphische Form von R

53
Definition: Definition:
Sei ~ eine Äquivalenzrelation in X und es gelte x X, die Teilmenge [x] ~: {xi X und xi ~x} heißt Äquivalenzklasse von x unter der Äquivalenzrelation „~“. Definition: Die Menge X /~ : = {[x]~ | x X } heißt Quotientenmenge von X bezüglich ~. Bemerkung: Zwischen X und X / ~ ist immer eine Abbildung µ definiert: µ: X X /~ mit µ(x) = [x]~
 = [x]~")
54
Strenge Präferenzrelation:
Eigenschaften: Asymmetrie, Transitivität, negative Transitivität, Trichotomie: für xi, xj X gilt: xi xj, xj xi oder xj ~ xi Satz: Die Relation auf X induziert eine strenge Präferenzrelation Bildung: xi xj genau dann, wenn xi xj und nicht xj xi gilt.

55
Strikte lineare Ordnung: ´
Eigenschaften: Irreflexiv, asymmetrisch, transitiv, schwach zusammenhängend Bemerkung: Bekanntestes Beispiel einer derartigen Relation ist die Relation < im R1. Satz: Eine schwache Präferenzrelation auf X induziert eine strikte lineare Ordnung in X/~.

56
Ordinaler Nutzenindex
Definition: Sei X eine Menge von Konsequenzen, auf denen eine schwache Präferenzrelation erklärt wird. Sei f eine Abbildung f : X R1 derart, dass für alle xi, xj X für die xi xj gilt, auch f(xi) f(xj) gilt. f ist eine monotone und ordnungsrelationstreue Abbildung von X in der R1 bezüglich und heißt ORDINALER NUTZENINDEX. ~ -
 f(xj) gilt. f ist eine monotone und ordnungsrelationstreue Abbildung von X in der R1 bezüglich und heißt ORDINALER NUTZENINDEX. ~ -")
57
Zum Problem der Konstruktion des ordinalen Nutzenindex (|X| sei endlich)
1) Man bilde die Quotientenmenge X / ~ 2) Finde Abbildung u u: X/~ R1 mit der Eigenschaft: u (qi) < u (q2) genau dann, wenn qi ´qj Für endliche Quotientenmengen: 1) Man zähle X/~ ab: q1, q2, ..., qm. 2) Man sortiere X/~ durch ein bekanntes Verfahren in O(m log2 m) Schritten und erhält: qi1 `qi2 ´... ´qim - - - -
 Man bilde die Quotientenmenge X / ~ 2) Finde Abbildung u. u: X/~ R1 mit der Eigenschaft: u (qi) < u (q2) genau dann, wenn qi ´qj. Für endliche Quotientenmengen: 1) Man zähle X/~ ab: q1, q2, ..., qm. 2) Man sortiere X/~ durch ein bekanntes Verfahren in O(m log2 m) Schritten und erhält: qi1 `qi2 ´... ´qim")
58
- - X R1 - X/~ - 3) Wir ermitteln u indem wir die Abbildung verwenden:
u (qik ) = k Satz: Ein ordinaler Nutzenindex ist nur bis auf streng monotone Transformationen eindeutig. Tatsächlich gilt: - X R1 X/~ - u = u ° - u
 = k. Satz: Ein ordinaler Nutzenindex ist nur bis auf streng monotone Transformationen eindeutig. Tatsächlich gilt: - X R1. X/~ - u = u ° - u.")
59
Definition: Sei ~ eine Äquivalenzrelation in X und es gelte x X, die Teilmenge [x] ~: {xi X und xi ~x} heißt Äquivalenzrelation der Relation ~. Definition: Die Menge X/~ : = {[x]~ | x X } heißt Quotientenmenge von X bezüglich ~. Bemerkung: Zwischen X und X / ~ ist immer eine Abbildung µ definiert: µ: X X /~ mit µ(x) = [x]~
 = [x]~")
60
Definition: Wahrscheinlichkeitsmaß W auf Menge ist eine reelle Funkton, die auf allen Teilmengen von definiert ist, und folgende Eigenschaften aufweist: a) W(A) 0 b) W () = 1 c) W(AB) = W(A) + W(B) wenn AB = 0 d) Es gibt eine endliche Menge H , sodaß W(H) =1
 W(A) 0. b) W () = 1. c) W(AB) = W(A) + W(B) wenn AB = 0. d) Es gibt eine endliche Menge H , sodaß W(H) =1.")
61
Wir betrachten mit W die Menge der einfachen Wahrscheinlichkeitsmaße
Es gelte: H = {w1, w2, w3, ...wh} (gem. Definition) Wir können dann auch schreiben für P W w1 w wh P = w1 w2 ... wh P kann als eine Lotterie interpretiert werden mit den Ausgängen wi (i= 1, 2, ..., h) h mit wi = 1 i=1
 Wir können dann auch schreiben für P W. w1 w wh. P = w1 w2 ... wh. P kann als eine Lotterie interpretiert werden mit den Ausgängen wi (i= 1, 2, ..., h) h. mit wi = 1. i=1.")
62
Zusammensetzung von Lotterien
Es seien 1, 2, . . ., k reelle Zahlen mit und i 0 (i= 1, 2, ..., k) und Pi {(A)} (i= 1, 2, ..., k) seien einfache Wahrscheinlichkeitsmaße aus W. Dann sei P{(A)} = 1 x Pi {(A)} das Wahrscheinlichkeitsmaß der zusammengesetzten Lotterie. (αi und die Wahrscheinlichkeiten müssen von unabhängigen Mechanismen verursacht werden!) k i=1 i = 1 k i=1
 und. Pi {(A)} (i= 1, 2, ..., k) seien einfache Wahrscheinlichkeitsmaße aus W. Dann sei P{(A)} = 1 x Pi {(A)} das Wahrscheinlichkeitsmaß der zusammengesetzten Lotterie. (αi und die Wahrscheinlichkeiten müssen von unabhängigen Mechanismen verursacht werden!) k. i=1. i = 1. k. i=1. ")
63
d.h. Pi wird mit Wahrscheinlichkeit 1 geliefert (i = 1, 2, ..., k)
Eine Interpretation der Linearkombination der Wahrscheinlichkeitsmaße ist der Begriff der zusammengesetzten Lotterie d.h. Pi wird mit Wahrscheinlichkeit 1 geliefert (i = 1, 2, ..., k) Einbettung der Menge in W: a) wi = für wi gehört zu W b) wir können daher jede Lotterie P W folgendermaßen schreiben: P = p1w1 + p2w pkwk Bemerkung: Es gelte = {wi = |wi } Offenbar gilt: = * W wi 1 wi 1 ~
 Einbettung der Menge in W: a) wi = für wi gehört zu W. b) wir können daher jede Lotterie P W folgendermaßen schreiben: P = p1w1 + p2w pkwk. Bemerkung: Es gelte = {wi = |wi } Offenbar gilt: = * W. wi. 1. wi. 1. ~")
64
Unter den Voraussetzungen des N-M-Axiomensystems kann man eine Nutzenfunktion
u: W R1 konstruieren, die effizienter verwendbar ist als ein ordinaler Nutzenindex!

65
V.Neumann - Morgenstern
AXIOMENSYSTEM von V.Neumann - Morgenstern N1. Auf der Menge der Lotterien W existiert eine schwache Präferenzrelation „ „, es sei „„ die zur Relation „ „ gehörige strikte Präferenz. N2. Es seien P, Q, R Lotterien und 0 < <1, dann gilt P Q P + (1- )R Q + (1- )R N3. P,Q,R seien Lotterien und PQR, dann gibt es Zahlen , mit 0 < < 1 und 0 < < 1 , so daß gilt: P + (1- )R Q P + (1- ) R. ~ ~
R Q + (1- )R. N3. P,Q,R seien Lotterien und PQR, dann gibt es Zahlen , mit 0 < < 1 und 0 < < 1 , so daß gilt: P + (1- )R Q P + (1- ) R. ~ ~")
66
A) Ordnungstreue (Monotonie): P Q U(P) U(Q) B) Linearität:
Erwartungsnutzen Definition: Eine Funktion U:W R1 heißt Erwartungsnutzen, wenn sie folgende Eigenschaften erfüllt: A) Ordnungstreue (Monotonie): P Q U(P) U(Q) B) Linearität: U(1P1+ 2P KPK) = 1U(P1) + 2U(P2)+...+ KU(PK) C) Eindeutigkeit bis auf positiv-lineare Transformationen: seien u,v zwei Funktionen, welche A) und B) erfüllen, dann gilt: U(P) = AV (P) + B mit A >0
 Ordnungstreue (Monotonie): P Q U(P) U(Q) B) Linearität: U(1P1+ 2P KPK) = 1U(P1) + 2U(P2)+...+ KU(PK) C) Eindeutigkeit bis auf positiv-lineare Transformationen: seien u,v zwei Funktionen, welche A) und B) erfüllen, dann gilt: U(P) = AV (P) + B mit A >0.")
67
Hauptsatz der kardinalen Nutzentheorie
Auf einer Menge von Lotterien W, welche 1. die Axiome von v.Neumann - Morgenstern erfüllen und 2. in der es mindestens ein paar P, Q mit P Q gibt existiert ein Erwartungsnutzen: Beweisidee: Setze u (P) = 0 und u (Q) = 1 A) Für PRQ kann man aus Axiomen folgern: Es gibt ein eindeutiges ( (0,1)), so dass R~ P+(1-)Q gilt. Hieraus: u(R) = 1- (R heißt Sicherheitsäquivalent von P+(1- )Q analog: RPQ und PQR
 = 0 und u (Q) = 1. A) Für PRQ kann man aus Axiomen folgern: Es gibt ein eindeutiges ( (0,1)), so dass. R~ P+(1-)Q gilt. Hieraus: u(R) = 1- (R heißt Sicherheitsäquivalent von P+(1- )Q. analog: RPQ und PQR.")
68
X ist meist eine Menge von monetären Konsequenzen (homogenes Gut).
Bernoulli-Prinzip: X ist meist eine Menge von monetären Konsequenzen (homogenes Gut). uo: R1R1 mit uo (x) = u([ ]) (oft einfach u(x)) Ergebnis des Hauptsatzes: u(P) = E(u(x)) für P W Beispiel: x1 x2 P = p 1-p Zwei Zufallsvariable: u(x) (Nutzen u(xi) mit Wahrscheinl. pi) x (Geldbetrag xi mit Wahrscheinl. pi) Nach Hauptsatz gilt: u(P) = p u(x1) + (1-p) u(x2) (=E(u(x))) Meist gilt zudem u(P) E(x) außer wenn u(x) linear. x 1
. uo: R1R1 mit uo (x) = u([ ]) (oft einfach u(x)) Ergebnis des Hauptsatzes: u(P) = E(u(x)) für P W. Beispiel: x1 x2. P = p 1-p. Zwei Zufallsvariable: u(x) (Nutzen u(xi) mit Wahrscheinl. pi) x (Geldbetrag xi mit Wahrscheinl. pi) Nach Hauptsatz gilt: u(P) = p u(x1) + (1-p) u(x2) (=E(u(x))) Meist gilt zudem u(P) E(x) außer wenn u(x) linear. x. 1.")
69
Nutzenfunktion: Problem des Sicherheitsäquivalents:
Finde einen Wert ξ derart, dass z.B. (Zweipunktverteilung) gilt: u(ξ) = u(P) = p(u(x1)) + (1-p)u(x2) (P W)
 gilt: u(ξ) = u(P) = p(u(x1)) + (1-p)u(x2) (P W)")
70
Bsp: konvexe Nutzenfunktion (Risikofreudigkeit)
u(x) = x²/10 : Fixpunkte u(x)= x : x = 0 x = 10 u(x2) u(x2)-u(x1) Also: ξ > E(x) ξ = 15, u(x1) x 5 10=x =E(X) =x2
 = x²/10 : Fixpunkte u(x)= x : x = 0. x = 10. u(x2) u(x2)-u(x1) Also: ξ > E(x) ξ = 15, u(x1) x. 5 10=x1 15=E(X) 20=x2.")
71
Experimentelle Ermittlung von ξ:
Man ermittle ξ, so daß A1 ~ A2; d.h. ξ ξ ~ x1 x2 p p p p ,also U{ξ} = p u(ξ) + (1-p) u(ξ) = p u (x1) + (1-p) u(x2) also =P u(ξ) = E (u(X)) ½ ½
 + (1-p) u(ξ) = p u (x1) + (1-p) u(x2) also =P u(ξ) = E (u(X)) ½ ½.")
72
Bsp.: p= 0,5; Bekannte Nutzenfunktion:
E(x) = 10 * 0, * 0,5 = 15 P = E(U(x)) = 40 * 0, * 0,5 = 25 = u(ξ) ξ = 25 x 10 15,8 (=u-1(u(ξ))) E(U(X)) = 25 ξ > E(X) Risikofreude (U-1(U(E(X)))) = E(X) ξ > E(X) Risikofreude ξ < E(X) Risikoaversion
 = 10 * 0, * 0,5 = 15. P = E(U(x)) = 40 * 0, * 0,5 = 25 = u(ξ) ξ = 25 x 10 15,8 (=u-1(u(ξ))) E(U(X)) = 25. ξ > E(X) Risikofreude (U-1(U(E(X)))) = E(X) ξ > E(X) Risikofreude. ξ < E(X) Risikoaversion.")
73
u(x2)-u(x1) Also: ξ < E(x)
Risikoaversion (u (x) ist konkav) u (x2) 1-p p u(x2)-u(x1) Also: ξ < E(x) u (x1) x1 ξ E(x) x2
 ist konkav) u (x2) 1-p. p. u(x2)-u(x1) Also: ξ < E(x) u (x1) x1 ξ E(x) x2.")
74
Nutzenkurve nach Friedmann & Savage (The Utility Analysis Of Choices And Risks; Journal Of Political Economy, pp , 1948 Erklärt z. B. Glücksspiel-teilnahme Erforderlich aus St. Petersburg Paradoxon Erklärt z. B. warum bei beliebiger Gewinnerhöhung bei Glücksspielen die Teilnehmerzahl nicht beliebig erhöht werden kann! Erklärt z. B. Ab-schlüsse von Ver-sicherungsverträgen

75
(Krelle)
")
76
Beispiele aus der Nutzentheorie 1) Wir betrachten 2 Lotterien: R= S=
Welche Präferenzen haben Sie? Zu komplex? Wenn ja: 1) Anerkennen Sie Axiome 1-3; wenn ja: 2) Können Sie Ihre Präferenzen für folgende 2 Lotterien angeben: P= Q= 0,02 0,32 0,66 0,1 0,42 0,48 0, ,9 0,5 0,5
 Anerkennen Sie Axiome 1-3; wenn ja: 2) Können Sie Ihre Präferenzen für folgende. 2 Lotterien angeben: P= Q= ,02 0,32 0, ,1 0,42 0, ,1 0, ,5 0,5.")
77
Wenn ja, so kann man mittels
Vermöge der Zusammensetzung R = 0,2 P + 0,8 T S = 0,2 Q + 0,8 T und Axiom 2 die Präferenz für R und S ableiten! 0,4 0,6

78
Gegeben: 2 Paare von Lotterien (Angaben in Mio.€) a) b) P= R= Q= S=
Beispiel aus der Nutzentheorie zur Aufdeckung von Inkonsistenzen aus F.Ferschl, Nutzen- und Entscheidungstheorie, Opladen) Gegeben: 2 Paare von Lotterien (Angaben in Mio.€) a) b) P= R= Q= S= Häufig wird nun folgende Präferenz bekanntgegeben: (A) P Q und (B) S R Man kann zeigen, dass es keine Nutzenfunktion u gibt, die dieses Verhalten erklären kann: 0 5 25 0,01 0,9 0,09 0, ,09 5 1 0, ,1
 Gegeben: 2 Paare von Lotterien (Angaben in Mio.€) a) b) P= R= Q= S= Häufig wird nun folgende Präferenz bekanntgegeben: (A) P Q und (B) S R. Man kann zeigen, dass es keine Nutzenfunktion u gibt, die dieses Verhalten erklären kann: ,01 0,9 0, ,91 0, ,9 0,1.")
79
Zu A) u(P) = 0,01 u(0) + 0,9 u(5) + 0,09 u(25) u(Q) = u(5) aus P Q folgt u(P) < u(Q) oder 0,01 u(0) + 0,09 u(25) 0,1 u(5) Zu B) 0,91 u(0) + 0,09 u(25) = u(R) 0,9 u(0) + 0,1 u(5) = u(S) also wegen S R folgt: 0,1 u(5) 0,09 u(25) + 0,01 u(0) |Widerspruch
 0,91 u(0) + 0,09 u(25) = u(R) 0,9 u(0) + 0,1 u(5) = u(S) also wegen S R folgt: 0,1 u(5) 0,09 u(25) + 0,01 u(0) |Widerspruch.")
80
Grund des Widerspruchs: Axiom 2 T= V= ; es gilt P= 0,1 T + 0,9 Q
Q= 0,1 Q + 0,9 Q 1) gilt P Q folgt (Axiom 2) T Q Es gilt aber: R= 0,1 T + 0,9 V S = 0,1 Q + 0,9 V 2) Aus T Q folgt (Axiom 2) R S 3) Widerspruch zur Aussage der Versuchsperson! 0, ,9 1
 gilt P Q folgt (Axiom 2) T Q. Es gilt aber: R= 0,1 T + 0,9 V. S = 0,1 Q + 0,9 V. 2) Aus T Q folgt (Axiom 2) R S. 3) Widerspruch zur Aussage der Versuchsperson! ,1 0,9. 1.")
81
Gegeben seien 2 Paare von Lotterien: a) P= b) R= a) Q= b) S=
Es werde von einem Entscheidungsträger folgende Präferenz bekanntgegeben: P Q und S R Untersuchen Sie mit Hilfe der Zusammensetzungen P= 0,1 T + 0,9 Q, R= 0,1 T + 0,9 V und S = 0,1 Q + 0,9 V wobei gelte: T= , V= diese Angaben auf die Möglichkeit einer Ableitung eines Erwartungsnutzens ausgehend von dem Neumann-Morgenstern´schen Axiomensystem. 0, ,09 0 1 5 0,01 0,9 0,09 0, ,1 1 0, ,9 1

82
Risikoaversion und Risikoaversionsmasse
Kard. Nutzenfunktion ist unter gewissen rationalen Voraussetzungen aus Präferenzrelation bildbar. Bsp.: a b 1- Wahrscheinlichkeit Risikoprämie: Maximum an Wohlstand, den ein Individuum aufgeben würde, um Risiko zu vermeiden.

83
Markowitz´sche Prämie: E(W) - ξ (von W abhängig)
Bsp.: Es gelten U(W) = ln (W) (logarithm. Nutzenfunktion) a b Lotterie: = 0,8 0, , ,2 0,8 0,2 U (E (W)) = ln 0,8 5 + ln 0,2 30 = 2,3 E (U (W)) = 0,8 ln 5 + 0,2 ln 30 = 1,97 Markowitz‘sche Risikoprämie: ,17 = 2,83 = E (W) - ξ p = 0,8 und 1 - p = 0,2
 = ln (W) (logarithm. Nutzenfunktion) 5 30 a b. Lotterie: = 0,8 0,2 0,8 0,2. 0,8. 0,2. U (E (W)) = ln 0,8 5 + ln 0,2 30 = 2,3. E (U (W)) = 0,8 ln 5 + 0,2 ln 30 = 1,97. Markowitz‘sche Risikoprämie: ,17 = 2,83 = E (W) - ξ. p = 0,8 und 1 - p = 0,2.")
84
Wir nehmen nun an, dass die Individuen risikoavers sind.
Das Markowits´sche Risikoaversionsmaß ist die Risikoprämie U-1(U (E(W))) - U-1(E(U(W))) = E (w) - ξ Dieses Maß ist jedoch von der Höhe von W und der Verteilung abhängig.
)) - U-1(E(U(W))) = E (w) - ξ. Dieses Maß ist jedoch von der Höhe von W und der Verteilung abhängig.")
85
Pratt - Arrow´sches Risikoaversionsmaß
sei eine Zufallsvariable mit E() = 0 Ausgangspunkt: Was ist die Risikoprämie p (W, ) für das Spiel, bei dem das Individuum W + ( zufällig) erhält? Es gilt für die Risikoprämie p, dass folgende Gleichung erfüllt wird: E(U(W+ ) = U(W+E()- p(W, ))
 = 0. Ausgangspunkt: Was ist die Risikoprämie p (W, ) für das Spiel, bei dem das Individuum W + ( zufällig) erhält Es gilt für die Risikoprämie p, dass folgende Gleichung erfüllt wird: E(U(W+ ) = U(W+E()- p(W, ))")
86
Taylor Reihe: f(x) = f(a) + f´(a) (x-a) + f´´(a) f(n) (a) Beide Seiten Taylor approximiert: Links: E(U(W+)) = E(U(W) + U´(W) + ½ 2 U´´ (W) und Ausdrücke von O(3) = U(W) + ½ 2 U´´ (W) + ... (x-a)2 2! (x-a)n n!
) = E(U(W) + U´(W) + ½ 2 U´´ (W) und Ausdrücke von O(3) = U(W) + ½ 2 U´´ (W) (x-a)2. 2! (x-a)n. n!")
87
U(W + E() - π (W,Z)) = U(W- π ) =
Recht: U(W + E() - π (W,Z)) = U(W- π ) = U(W) - π U´(W) + Ausdrücke kleinerer Ordnung Also: U(W) - π U´(W) = U(W) + 1/2 ² U´´(W) nach π aufgelöst: π = ½ ² = ARA nach Pratt/Arrow U´´(W) U´(W) U´´(W) U´(W) - Z immer positiv (Skalenveränderung)
 - π (W,Z)) = U(W- π ) = U(W) - π U´(W) + Ausdrücke kleinerer Ordnung. Also: U(W) - π U´(W) = U(W) + 1/2 ² U´´(W) nach π aufgelöst: π = ½ ² = - ARA nach Pratt/Arrow. U´´(W) U´(W) U´´(W) U´(W) - Z. immer positiv. (Skalenveränderung)")
88
ARA ist das absolute Risikoavesionsmaß,
da es von der Höhe von W abhängig ist. Wir wollen daher noch ein von der Höhe von W unabhängiges Risikoaversionsmaß RRA: RRA: - W U´´(W) U´ (W)
 U´ (W)")
89
Empirische Untersuchung zur Risikoaversion
Beispiel: Häufig verwendete Nutzenfunktion: quadratische Nutzenfunktion Für W < a/2b gilt: U (W) = aW - bW2 Es gilt: U'(W) = a - 2bW U''(W) = -2b
 = aW - bW2. Es gilt: U (W) = a - 2bW. U (W) = -2b.")
90
Also ARA = > 0 2b d(ARA) a-2bW dW RRA = > 0 2b d(RRA)
(a/W)-2b dW ergo: nicht konstant!
-2b dW. ergo: nicht konstant!")
91
-2W-3 Konstantes RRA wird erfüllt durch: ARA = - = < 0
U(W) = W-1; U´(W) = W-2 > 0; U´´(W) = -2W-3 < 0 ARA = = < 0 RRA = W = 2 = 0 Diese Funktion stimmt mit empirischen Ergebnissen von Friend + Blum, The demand for Risky Assets, Am. Ec.Re., 1975 p überein. -2W-3 W-2 2 W d(ARA) dW 2 W d(RRA) dW
 = W-1; U´(W) = W-2 > 0; U´´(W) = -2W-3 < 0. ARA = - = < 0. RRA = W = 2 = 0. Diese Funktion stimmt mit empirischen Ergebnissen von Friend + Blum, The demand for Risky Assets, Am. Ec.Re., 1975 p überein. -2W-3. W W. d(ARA) dW. 2. W. d(RRA) dW.")
92
Stochastische Dominanz
Bsp: Umweltkonstellationen seien geordnet nach dem Nutzen und es gelte Z~R1 (bzw. geordnet nach Geldeinheiten). Es gelte nun für eine Aktion x und y milden Wahrscheinlichkeitsverteilungen F und G: (1) Fx (W) Gy (W) für alle W (W=„Wohlstand“) und (2) Fx (Wi) < Gy (Wi) für mindestens einige W;
. Es gelte nun für eine Aktion x und y milden Wahrscheinlichkeitsverteilungen F und G: (1) Fx (W) Gy (W) für alle W (W=„Wohlstand ) und. (2) Fx (Wi) < Gy (Wi) für mindestens einige W;")
93
Beispiel:

94
Definition: Sind die Bedingungen (1) und (2) erfüllt für zwei Alternativen (Aktionen) x und y, so spricht man von stochastischer Dominanz 1. Ordnung von Fx über Gy oder einfach von x über y-für nicht abnehmende Nutzenfunktionen! Bemerkung: Offenbar ist das Gegenteil wahr für alle abnehmenden Nutzenfunktionen, d.h. y dominiert x.
 und (2) erfüllt für zwei Alternativen (Aktionen) x und y, so spricht man von stochastischer Dominanz 1. Ordnung von Fx über Gy oder einfach von x über y-für nicht abnehmende Nutzenfunktionen! Bemerkung: Offenbar ist das Gegenteil wahr für alle abnehmenden Nutzenfunktionen, d.h. y dominiert x.")
95
Stochastische Dominanz 2. Ordnung
Voraussetzung: a) Nutzenfunktion ist nicht abnehmend b) Nutzenfunktion ist streng konkav (d.h. im abnehmenden Maße zunehmend!)
 Nutzenfunktion ist nicht abnehmend. b) Nutzenfunktion ist streng konkav (d.h. im abnehmenden Maße zunehmend!)")
96
Beispiel solcher Nutzenfunktion:
Bemerkung: D.h. wir setzen Risikoaversion voraus.

97
(Gy(W) - Fx(W)) dW > 0 für alle W,
Definition: Eine Alternative (Aktion) x heiße stochastisch dominant 2er Ordnung über Alternative y, wenn für alle risikoaversen Entscheider gilt: (Gy(W) - Fx(W)) dW > 0 für alle W, und Gy(Wi) Fx (Wi) für einige Wi Wi -
 x heiße stochastisch dominant 2er Ordnung über Alternative y, wenn für alle risikoaversen Entscheider gilt: (Gy(W) - Fx(W)) dW > 0 für alle W, und Gy(Wi) Fx (Wi) für einige Wi. Wi. - ")
98
Beispiel: f (G(w) - F(w)) d W Differenz ux = uy
 - F(w)) d W Differenz ux = uy")
100
Bemerkung: Die Aussage bezieht sich also auf die Fläche unter der kumulativen Verteilungsfunktion! Entspricht der Intuition: Varianz wird berücksichtigt = Risiko Bemerkung zum Beispiel: Bei der linearen Nutzenfunktion wären die Alternativen x und y bei (Rumpf-) Normalverteilung äquivalent! Stochastische Dominanz kann also für alle risikoaversen Entscheider verwendet werden um Alternativen zu eliminieren!
 Normalverteilung äquivalent! Stochastische Dominanz kann also für alle risikoaversen Entscheider verwendet werden um Alternativen zu eliminieren!")
101
Mittelwert und Varianz als Auswahlkriterien Gehen wir von einer zweiparametrigen Klasse von Wahrscheinlichkeitsverteilungen aus und betrachten hiervon nur die Normalverteilung! Man kann dann zeigen, dass (μ,σ) als Kriterium für Dominanz genügt Beispiel: μ σ

102
Man kann auch zeigen, dass diese Möglichkeit für andere 2- parametrige Verteilungen nicht vorausgesetzt werden kann ((μ,σ)- Paradoxon). (Im übrigen Schneeweiß H., Entscheidungskriterien bei Risiko, Springer Verlag)
.")
103
Entscheidungen unter Sicherheit A) Modelle mit einer Zielsetzung: Ziel: Nutzenmaximierung Tatsächlich: Vereinfachte Realsituation z a1 u1 a2 u2 . . an un

104
B) Modelle mit mehreren Zielsetzungen:. Ziele. k1. k2. kv Aktionen a1
B) Modelle mit mehreren Zielsetzungen: Ziele k1 k kv Aktionen a1 u11 u u1v - Konsequenzenteilnutzen a2 u21 u u2v am um1 um2 umv Probleme: Nutzenunabhängikeit der Teilnutzen Zieltypologisierung nach Zielverhalten: α) Indifferente Ziele β) Komplementäre Ziele γ) Konkurrierende Ziele
 Modelle mit mehreren Zielsetzungen: Ziele k1 k kv Aktionen a1 u11 u u1v - Konsequenzenteilnutzen a2 u21 u u2v am um1 um2 umv Probleme: Nutzenunabhängikeit der Teilnutzen Zieltypologisierung nach Zielverhalten: α) Indifferente Ziele β) Komplementäre Ziele γ) Konkurrierende Ziele.")
105
Auswahlschritte: α) Elimination ineffizienter Aktionen β) Auswahl aus den effizienten Aktionen Definition der Effizienz: Eine Aktion heißt effizient, wenn es α) keine Aktion aq A gibt, mit uqp > uip für alle p = 1, 2, ..., v und β) uqp > uip für mindestens ein p {1, 2, ..., v} gilt.
 Elimination ineffizienter Aktionen β) Auswahl aus den effizienten Aktionen Definition der Effizienz: Eine Aktion heißt effizient, wenn es α) keine Aktion aq A gibt, mit uqp > uip für alle p = 1, 2, ..., v und β) uqp > uip für mindestens ein p {1, 2, ..., v} gilt.")
106
Beispiel:. Ziele. k1. k2. k3 Aktionen a1. 3. 7. 2
Beispiel: Ziele k1 k2 k3 Aktionen a Nicht dominierte Aktionen a (effizient) a z. B. a4 dominiert a1. a a Dies gilt ebenso für mehrere Umweltsituationen! (Allgemein und schwächer als die stochastische Dominanz!)
 a z. B. a4 dominiert a1. a a Dies gilt ebenso für mehrere Umweltsituationen! (Allgemein und schwächer als die stochastische Dominanz!)")
107
Beispiele zu Verknüpfungsregeln der Teilnutzen bei Entscheidung bei mehrfacher Zielsetzung A) Zielgewichtung: Bewertung Φ (ai) = Σ qi uij Beispiel: k1 k2 k3 Φ (ai) a ,1 a ,2 a , k1 : k2 : k3 = 1 : 2 : 7 Gewichte: 0,1; 0,2; 0,7
 a ,1 a ,2 a ,3 k1 : k2 : k3 = 1 : 2 : 7 Gewichte: 0,1; 0,2; 0,7.")
108
B) Zielunterdrückung Spezialfall der Zielgewichtung; Gewichtungsvektor = 0,0, ... 0,1, 0,... z. B. nach schlechten Jahren: Gewinnmaximierung.

109
C) Aktionenauswahl nach lexikographischer Ordnung Voraussetzung: Schwache Präferenzordnung auf den Zielen (Ziele in gleichen Restklassen werden zusammengelegt); Folge: strenge lineare Ordnung auf den Restklassen: ki1 > ki2 > ... > kiv; nach sortieren (stabil) Auswahl Bsp.: k2 > k1 > k3 Bewertung: k1 k2 k3 a a2 a sortieren a1 a a3 a a Präferenz(-annahme): a2 > a1 > a3 > a4
 Auswahl Bsp.: k2 > k1 > k3 Bewertung: k1 k2 k3 a a2 a sortieren a1 a a3 a a4 Präferenz(-annahme): a2 > a1 > a3 > a4.")
110
D) Maximierung des minimalen Zielerreichungsgrades N
D) Maximierung des minimalen Zielerreichungsgrades N. Körth Bewertung: Φ(ai) = min (maxuipuhp) {p} {h} Beispiel: k1 k2 k3 uip Min.d max uhp Zeile a /9 7/8 2/8 2/ a /9 6/8 1 1/ a /8 6/8 2/ a /9 1 3/8 3/8+ Opt. Alternative Grad: 0,375 a /9 6/8 1/2 3/9
 Maximierung des minimalen Zielerreichungsgrades N. Körth Bewertung: Φ(ai) = min (maxuipuhp) {p} {h} Beispiel: k1 k2 k3 uip Min.d. max uhp Zeile a /9 7/8 2/8 2/8 a /9 6/8 1 1/9 a /8 6/8 2/8 a /9 1 3/8 3/8+ Opt. Alternative Grad: 0,375 a /9 6/8 1/2 3/9.")
111
E) Goal-Programming-Ansatz (Charnes, Cooper) Gesamtziel:
E) Goal-Programming-Ansatz (Charnes, Cooper) Gesamtziel: Minimierung der absoluten Abweichungen von den gesetzten Zielen! Bewertungsfunktion: Φ(ai) = Σ |uip - ûp| p ûp = für Ziel kp gesetztes Niveau
 Goal-Programming-Ansatz (Charnes, Cooper) Gesamtziel: Minimierung der absoluten Abweichungen von den gesetzten Zielen! Bewertungsfunktion: Φ(ai) = Σ |uip - ûp| p ûp = für Ziel kp gesetztes Niveau.")
112
Beispiel:. k1 k2 k3. I) Zielvorgabe:. k1 k2 k3 Φ a1. 3 7 2. û1 = 3
Beispiel: k1 k2 k3 I) Zielvorgabe: k1 k2 k3 Φ a û1 = Gleich a û2 = gewichtet: a û3 = Abweichung a (uip-ûp) a II) Zielvorgabe: k1 k k Φ û1 = (Spezialfall: û2 = Zielgewichtung) û3 = Zielplus - Zielminus gleiches Gewicht! (Vgl. Bamberg, Coenenberg, Betriebswirtschaftliche Entscheidungslehre, Vahlen.)
 Zielvorgabe: k1 k2 k3 Φ a û1 = Gleich a û2 = gewichtet: a û3 = Abweichung a (uip-ûp) a II) Zielvorgabe: k1 k2 k3 Φ û1 = (Spezialfall: û2 = Zielgewichtung) û3 = Zielplus - Zielminus gleiches Gewicht! (Vgl. Bamberg, Coenenberg, Betriebswirtschaftliche Entscheidungslehre, Vahlen.)")
113
Beispiel mit überabzählbaren Aktionenmengen (Problem: Bamberg, Coenenberg, Entscheidungslehre, S. 53) Produktionsbeschränkungsgleichungen bei Erzeugung zweier Produkte: x + 3y < y < x < x,y > Gewicht Fall 1) û1 = Gewinnmaximierungsniveau = , Zielfunktion: u1 (x,y) = 7x + 5y û2 = Umsatzmaximierungsniveau = , Zielfunktion: u2 (x,y) = 11x + 49y Summe der gewichteten Abweichungen ist zu minimieren: Zielfunktion: 0,4 (α1+ + α1-) + 0,6(α2+ + α2-) Min.
 Produktionsbeschränkungsgleichungen bei Erzeugung zweier Produkte: x + 3y < 160 y < 40 x < 100 x,y > 0 Gewicht Fall 1) û1 = Gewinnmaximierungsniveau = 800 0,4 Zielfunktion: u1 (x,y) = 7x + 5y û2 = Umsatzmaximierungsniveau = ,6 Zielfunktion: u2 (x,y) = 11x + 49y Summe der gewichteten Abweichungen ist zu minimieren: Zielfunktion: 0,4 (α1+ + α1-) + 0,6(α2+ + α2-) Min..")
114
Zusätzliche Gleichungen: 7x + 5y - α1+ + α1- = 800
Zusätzliche Gleichungen: x + 5y - α1+ + α1- = 800 (= erzielbares Gewinnmaximum) 11x + 49y - α2+ + α2- = 2400 (Ziel: Umsatzniveau) Ergebnis: α1- = 8, x = y = 18, Freikapazität y = 21, Lösung des Beispiels nach Körth-Ansatz (Vgl. Bamberg/Coenenberg, Loc. Cit., S. 53) x = 85 Gewinn: y = 25 Umsatz: Zielerreichungsrad: 0,9
 11x + 49y - α2+ + α2- = 2400 (Ziel: Umsatzniveau) Ergebnis: α1- = 8,1633 x = 100 y = 18,367 Freikapazität y = 21,633 Lösung des Beispiels nach Körth-Ansatz (Vgl. Bamberg/Coenenberg, Loc. Cit., S. 53) x = 85 Gewinn: 720 y = 25 Umsatz: 2160 Zielerreichungsrad: 0,9.")
115
Körth-Ansatz Optimale Lösungen Gewinnmax. Umsatzmax. x1+ = 100
Körth-Ansatz Optimale Lösungen Gewinnmax. Umsatzmax. x1+ = x2+ = 40 y1+ = y2+ = 40 u1 (x1+, y1+) = 800 u2 (x2+, y2+) = u2 (x1+, y1+) = u2 (x2+, y2+) = Wir wollen möglichst viele Prozente vom Gewinnmax. (=800) und Umsatzmax. (=2400) erzielen!
 = 800 u2 (x2+, y2+) = 2400 u2 (x1+, y1+) = 2080 u2 (x2+, y2+) = 480 Wir wollen möglichst viele Prozente vom Gewinnmax. (=800) und Umsatzmax. (=2400) erzielen!")
116
Also: w Max 7x + 5y > 800 w. Körth - Tafel: 11x + 49y > 2400 w
Also: w Max 7x + 5y > 800 w Körth - Tafel: 11x + 49y > 2400 w Gewinnmax. Umsatzmax. x y < y < x,y > = Max = Max. Lösung: x = 85 Gesucht: Zeile des max. Minimums y = 25 in Anteilen. u1 (x+, y+) = Gefunden = 0,9 ! u2 (x+, y+) = w = 0,9
 = 720 Gefunden = 0,9 ! u2 (x+, y+) = 2160 w = 0,9.")
117
B) Zielunterdrückung Wir wählen bei r Zielen einen speziellen Gewichtungsvektor (0, 0, ...0, 1, 0,...0) und entscheiden nach diesem Ziel. Beispiel: Nach ertragsschlechten Jahren: Gewinnmaximierung In obigem Beispiel: Ziel 1 a3 Ziel 2 a4 Ziel 3 a2

118
C) Auswahl nach lexikographischer Ordnung
Die Ziele werden nach der Priorität der Zeitscheidenden in eine Ordnung gebracht: ki1 > ki2 > ki3 ... > kip und die Aktionen nach den Zielen kip, kip-1, ..., ki1 in dieser Reihenfolge sortiert (stabiles Sortieren!) Beispiel: k1 k2 k3 a a a a Es gelte: k2 > k1 > k3 I) II) III) a2 a1 a3 a4
 Beispiel: k1 k2 k3. a a a a Es gelte: k2 > k1 > k3. I) II) III) a a a a4.")
119
D) Maximierung des minimalen Zielerreichungsgrades nach Körth uip
Φ (ai) = min ( ) max uhp {p} {h} Ziele k1 k2 k3 Min. d. Aktionen Zeile a /8 7/8 2/8 2/8 a * 1/9 6/8 1 1/9 a3 9* /8 6/8 2/8 a4 5 8* 3 5/9 1 3/8 3/8* a /9 6/8 1/2 2/9 Opt. Alternative! W = 0,375 uip max uhp {h}
 = min ( ) max uhp. {p} {h} Ziele k1 k2 k3 Min. d. Aktionen Zeile. a /8 7/8 2/8 2/8. a * 1/9 6/8 1 1/9. a3 9* /8 6/8 2/8. a4 5 8* 3 5/9 1 3/8 3/8* a /9 6/8 1/2 2/9. Opt. Alternative! W = 0,375. uip. max uhp. {h}")
120
Gewichtungs-Beispiel:
Ermitteln Sie den optimalen Preis zur Realisierung der Ziele: Gewinnmaximierung : Gewicht : ,6 Umsatzmaximierung : Gewicht : 2 0,4 Preisabsatzfunktion: x(p) = 60 - p Kostenfunktion: x p = 37,5 Gewinnmax: p (x(p)) - k max Umsatzmax: p . x (p) max p = 30 Lösung: 0,6 (75p - p ) + 0,4 (60p - p2) u = 575,25 P opt = 34,5
 = 60 - p. Kostenfunktion: x. p = 37,5. Gewinnmax: p (x(p)) - k max. Umsatzmax: p . x (p) max. p = 30. Lösung: 0,6 (75p - p ) + 0,4 (60p - p2) u = 575,25. P opt = 34,5.")
121
Gewichtungs-Beispiel:
3 Produktunternehmen Aktion: Wahl eines Produktionsplanes: (x, y, z) Deckungsbeiträge: Produkt A: 10 Mögl. Absatz: 100 Produkt B: Mögl. Absatz: 80 Produkt C: 8 Mögl. Absatz: 90
 Deckungsbeiträge: Produkt A: 10 Mögl. Absatz: 100. Produkt B: 12 Mögl. Absatz: 80. Produkt C: 8 Mögl. Absatz: 90.")
122
Es werden 3 selbst hergestellte Vorprodukte benötigt, die beschränkt sind:
VP PR Vorproduktionskapazitätsgrenzen A B C Ziele: 1) Gewinnmaximierung: u1 (x, y, z) = 10x + 12y + 8z 2) Umsatzmaximierung A: u2 (x, y, z) = x Gewichtung: Gewinn von 1,5 € ~ Absatz von 1 Stück A. Ermitteln Sie den optimalen Produktionsplan.
 Gewinnmaximierung: u1 (x, y, z) = 10x + 12y + 8z. 2) Umsatzmaximierung A: u2 (x, y, z) = x. Gewichtung: Gewinn von 1,5 € ~ Absatz von 1 Stück A. Ermitteln Sie den optimalen Produktionsplan.")
123
Lösung: Zielfunktion: 0,4 (10x + 12y + 8z) + 0,6x
x < x + 9y + 7z < 780 y < x + 8y + 8z < 900 z < x + y + z < 600 x, y, z > 0 Resultat: Zielfunktion: 528,38 x : 58,185 y: 56,325 z: 371,25

124
Ablauf einer Nutzwertanalyse bei der Anlagenauswahl
Ableitung der Zielhierarchie: Hauptgruppen Untergruppen

125
Tabelle der qualitativ be-werteten oder beschriebenen Konsequenzen der Alternativen je Zielkriterium
Bewertung der Kriterien mit Gewichten {gi / i = 1, 2, ... n} und der Konsequenzen mit dem Nutzen innerhalb des Zielkriteriums

126
Tabellen von entscheidungsträger-bezogenen einzelkriterien-verwerteten Alternativenbewertungen
Aggregation von mehreren Präferenzordnungen auf eine gemeinsame Präferenzordnung durch eine Entscheidungsregel Nutzwert-Tabelle der Alternativen

127
Die Vorgehensweise bei Nutzwertmodellen besteht aus folgenden Stufen:
1. Bestimmung der situationsrelevanten Ziele, bzw. Zielkriterien 2. Beschreibung der zielrelevanten Konsequenzen 3. Bewertung der Konsequenzen mit dem eindimensionalen Nutzen, d.h. Ermittlung des Konsequenzennutzens und Gewichtung der Zielkriterien. 4. Eventuelle Aggregation der Teilnutzen zu einem Gesamtnutzen bzw. zu einer Einzelbewertung der Alternativen. 5. Vergleich der Alternativen und Ermittlung der optimalen Alternative.

128
Die wesentlichen Probleme der Nutzwertanalyse liegen in
- der Auffindung der relevanten Zielkriterien, - der Bewertung der Kriterien mit den Gewichten und - der Wahl einer geeigneten Regel zur Aggregation der einzelnen Präferenzordnungen. Die Festlegung der Aggregationsregel und der Kriteriengewichte muss vor der Bewertung der in Frage kommenden Alternativen erfolgen.

129
Qualitative and Quantitative Comparison of two database systems A and B
0 = Not available 1 = very poor, or very difficult 2 = poor or difficult 3 = average, acceptable 4 = good or easy 5 = very good or very easy

130
2. Other criteria in order of importance

133
Betriebswirtschaftliche Entscheidungsmodelle unter Gewissheit
Finanzmathematische Modelle der Investitionsrechnung Lineare und nicht-lineare Programmierungs- modelle Ganzzahlige Optimierung Dynamische Optimierung Lagerhaltung Netzplantechnik u.a.m. Entscheidungsmatrix z a1 u1 Entscheidungs- a2 u2 aufgabe: . . finde max. ui {i} an un (und wähle ai)
")
134
Bemerkung: A) Sind meist bei realen Problemen nur mehr mit Computer durchführbar. B) Obwohl in den meisten Fällen Algorithmen existieren, die in endlicher Zeit eine optimale Lösung finden, finden manche dieser Algorithmen eine Lösung in „vernünftiger“ Zeit. C) Vor Einsatz eines Algorithmus ist der Berechnungsaufwand festzustellen. Meist gibt es mehrere Algorithmen zur Lösung der Auswahlaufgabe, deren Berechnungsaufwand von der „Datenaugenblicklichkeit“ des tatsächlichen Berechnungsproblems abhängt.
 Obwohl in den meisten Fällen Algorithmen existieren, die in endlicher Zeit eine optimale Lösung finden, finden manche dieser Algorithmen eine Lösung in „vernünftiger Zeit. C) Vor Einsatz eines Algorithmus ist der Berechnungsaufwand festzustellen. Meist gibt es mehrere Algorithmen zur Lösung der Auswahlaufgabe, deren Berechnungsaufwand von der „Datenaugenblicklichkeit des tatsächlichen Berechnungsproblems abhängt.")
135
Einführungsbeispiel:
Aufgabe: Sortiere eine endliche Menge von Aktionen nach ihrem Nutzen. Lösung: Es gibt viele Algorithmen zur Lösung. Einer hiervon lautet (U (I) ist eine Tabelle mit m Schlüsseleinträgen): Abschnitt Algorithmus A DO J = 2 TO m BY 1; I J - 1; Searchkey: = U (J); B DO WHILE ((Searchkey < U (I) Λ (I > 0)); C U (I + 1) U (I); I I - 1; D END; U (I + 1) Searchkey; END;
 ist eine Tabelle mit m Schlüsseleinträgen): Abschnitt Algorithmus. A DO J = 2 TO m BY 1; I J - 1; Searchkey: = U (J); B DO WHILE ((Searchkey < U (I) Λ (I > 0)); C U (I + 1) U (I); I I - 1; D END; U (I + 1) Searchkey; END;")
136
Algorithmusindividuelle
Datenaugen- Jede Anordnungs- ungünstigste günstigste augenblick- permutation ist Anordnungs- Anordnungs lichkeiten gleich wahrschein- Permutation Permutation lich Abschnitte A m m - 1 m - 1 m2 - m m2 - m B ~ + m-1~0(m2) ~ ~ 0(m2) m - 1 m2 - m m2 - m C ~ ~ 0 D m m - 1 m - 1
 ~ ~ 0(m2) m m2 - m m2 - m. C ~ ~ 0. D m - 1 m - 1 m - 1.")
137
„Random-Access-Machine“-Modell (RAM Modell)
(1-Akk. ohne Befehlsmodifikation!) x x xn Eingabe Pro- r (Akkumulator) Befehls- gramm r1 register r2 Speicher y1 y Ausgabe
 x1 x xn Eingabe. Pro- r0 (Akkumulator) Befehls- gramm r1. register r2. Speicher. y1 y Ausgabe.")
138
Operationen: Zeitbedarf der Operationen ca.
LOAD STORE ADD Operandenadresse 15 SUB (implizierter MULT Operand: Inhalt 30 DIV des Akkumulators) 80 READ lesen (1 Bandfeld ) WRITE schreiben JUMP JGTZERO Befehlsadresse 25 JZERO HALT (physisches Ende)
 80. READ lesen. (1 Bandfeld ) WRITE schreiben. JUMP 15. JGTZERO Befehlsadresse 25. JZERO 25. HALT - (physisches Ende)")
139
Programm im RAM-Code K2 DC 2 KM DC „M“ (wird zu Beginn geladen) K-1 DC 1 U(1) DC - U(2) DC - zu sortierender Bereich . . . U(M) DC - J DC Speicherreservierung I DC für Arbeitsvariable SK DC 0 Speicherbedarf des Algorithmus
 DC - J DC 0 Speicherreservierung. I DC 0 für Arbeitsvariable. SK DC 0. Speicherbedarf des Algorithmus.")
140
Fortran-Programm Subroutine B (U, M) Integer U (1), SK DO 6 J = 2,M A
I = J - 1 SK = U (J) 1 IF (SK - U (I)) 2, 5, 5 B 2 U (I+1) = U (I) I = I C IF (I) 6, 5, 1 5 U (I + 1) = SK 6 Continue D Return END Gesamtzeitbedarf ca.: m2 m + 20 4 Bei gleichwahrscheinlichen Anordnungspermutationen
 1 IF (SK - U (I)) 2, 5, 5 B. 2 U (I+1) = U (I) I = I - 1 C. IF (I) 6, 5, 1. 5 U (I + 1) = SK. 6 Continue D. Return. END. Gesamtzeitbedarf ca.: m m Bei gleichwahrscheinlichen. Anordnungspermutationen.")
141
„Einstiegsteil“ Ausführungshäufigkeit
Zeit LOAD K2 1 STORE J 1 AFN LOAD J SUB K - 1 45 STORE J A LOAD U (J) STORE SK BRANCH LOAD SK 75 SUB U (I) B JZERO CHANGE JGTZERO CHANGE
 STORE SK. BRANCH LOAD SK. 75 SUB U (I) B. JZERO CHANGE. JGTZERO CHANGE.")
142
LOAD U (I) STORE U (I + 1) LOAD I 115 SUB K - 1 C STORE I JGTZERO BRANCH JZERO CHANGE JUMP LOOP 20 CHANGE LOAD SK D LOOP LOAD J ADD K - 1 STORE J 110 LOAD M A SUB J JGTZERO ANF JZERO ANF RETURN END 1

143
Andere Algorithmen: Quicksort: Beispiel: Elemente < 7 2 < Ende 1. Phase Elemente > 7 „Erwartete Anzahl von Phasen: ~ 1,41 log n Vergleiche je Phase: < n Erwartete Anzahl der Vergleiche: 0 (n log n)
")
144
Ungünstigster Fall: 9 1 8 8 n - 1 Elemente je Block 4 4 3 3 2 2 1 9 Ende 1. Phase Erforderliche Anzahl von Vergleichen: n2 - n ~ ; d. h. 0 (n2) Operationen 2
 Operationen. 2.")
145
(Speicherbedarf von Algorithmen) Einige Begriffe:
Theorie der Komplexität: befasst sich mit Grundfragen des Laufzeitverhaltens von Algorithmen (Speicherbedarf von Algorithmen) Einige Begriffe: Komplexität: Größe zur Beurteilung der Güte eines Algorithmus zur Lösung eines Problems. Wird als Funktion f des Arguments Problemgrößen angegeben: f (n) Problemgröße: Positive Zahl, die eine Eigenschaft einer konkreten Datensituation einer Problemstellung misst; Beispiel: Anzahl der Kanten in einem graphentheoretischen Problem. Anzahl der zu sortierenden Elemente in einem Sortierproblem. Größe der Matrix in einem LP-Problem. Größe der Matrix in einem Inversionsproblem. Exakt: Länge des Eingabewortes bei Turing-Maschine (die Problem löst!)
 Einige Begriffe: Komplexität: Größe zur Beurteilung der Güte eines Algorithmus zur Lösung eines Problems. Wird als Funktion f des Arguments Problemgrößen angegeben: f (n) Problemgröße: Positive Zahl, die eine Eigenschaft einer konkreten Datensituation einer Problemstellung misst; Beispiel: Anzahl der Kanten in einem graphentheoretischen Problem. Anzahl der zu sortierenden Elemente in einem Sortierproblem. Größe der Matrix in einem LP-Problem. Größe der Matrix in einem Inversionsproblem. Exakt: Länge des Eingabewortes bei Turing-Maschine (die Problem löst!)")
146
Zwei Verhaltensmerkmale werden berücksichtigt:
Komplexität Zeitkomplexität: T (N) Speicherkomplexität: S (N) Ausführungszeit als Speicherbedarf bei Ausführung Funktion von N als Funktion von N
 Speicherkomplexität: S (N) Ausführungszeit als Speicherbedarf bei Ausführung. Funktion von N als Funktion von N.")
147
Zwei Komplexitätsmaßstäbe bei der Messung von Komplexität
1. Logarithmisches Komplexitätskriterium (Beruht auf der Anzahl der erforderlichen Operationen per Bit bzw. auf dem Bit-Speicherumfang) Grundannahme: Zeitkomplexität einer Operation mit N ist eine lineare Funktion von log (N). Ebenso gilt diese Annahme für die Speicherkomplexität. 2. Uniformes Komplexitätskriterium Jede Operation erfordert 1 Zeiteinheit Jede Zahl kann in einer Speicherstelle gespeichert werden.
 Grundannahme: Zeitkomplexität einer Operation mit N ist eine lineare Funktion von log (N). Ebenso gilt diese Annahme für die Speicherkomplexität. 2. Uniformes Komplexitätskriterium. Jede Operation erfordert 1 Zeiteinheit. Jede Zahl kann in einer Speicherstelle gespeichert werden.")
148
Beispiel: Berechnung der Funktion nn
Programm (AHO, HOPCROFT, ULLMANN) BEGIN Anzahl der Durchführungen READ r 1; IF r 1 < 0 THEN WRITE 0 ELSE BEGIN r 2 r 1; 1 r 3 r 1 - 1; WHILE r 3 > 0 DO; r 2 r 2 * r 1; n - 1 r 3 r 3 - 1; END; WRITE r 2;
 BEGIN Anzahl der Durchführungen. READ r 1; IF r 1 < 0 THEN WRITE 0. ELSE. BEGIN. r 2 r 1; 1. r 3 r 1 - 1; WHILE r 3 > 0 DO; r 2 r 2 * r 1; n - 1. r 3 r 3 - 1; END; WRITE r 2;")
149
Komplexität des Programmes Uniformes Logarithm. Kriterium Kriterium
Zeitkompl. 0 (n) 0 (n2logn) Speicherkompl. 0 (1) 0 (nlogn) ~n Multiplikation 1 Speicherstelle f.d. Resultat n - 1 Σ log (ni) + log n = i=1 Σ (i + 1) log n = 0 (n2logn) log nn Anwendung: Zweckmäßigkeitsfrage. Größere Bedeutung: log. Kriterium.
 0 (n2logn) Speicherkompl. 0 (1) 0 (nlogn) ~n Multiplikation 1 Speicherstelle. f.d. Resultat. n - 1. Σ log (ni) + log n = i=1. Σ (i + 1) log n = 0 (n2logn) log nn. Anwendung: Zweckmäßigkeitsfrage. Größere Bedeutung: log. Kriterium.")
150
Mehrband-Turingmaschine
Endliche Kontrollsteuerung K-Band

151
Mehrband-Turingmaschine ist ein 7-Tupel: (Q, T, I, δ, b, q0, qf)
1) Q = Menge von internen Zuständen 2) T = Menge von Bandsymbolen 3) I = Menge von Input-Symbolen (I < T) 4) b T - I ist das Leerzeichen 5) q0 = ist der Anfangszustand 6) qf = ist der Endzustand 7) δ = Nächster-Zug-Funktion; bildet Teilmenge Q x Tk in Q x (T x {L, R, S}k ab. D. h. es bildet ein Tupel aus (q, a1, a2, ..., ak) (ai Tiq Q) in (q‘, (a‘1, d1), (a‘2, d2), ..., (a‘k, dk)) (dj {L, R, S}) ab.
 Q = Menge von internen Zuständen. 2) T = Menge von Bandsymbolen. 3) I = Menge von Input-Symbolen (I < T) 4) b T - I ist das Leerzeichen. 5) q0 = ist der Anfangszustand. 6) qf = ist der Endzustand. 7) δ = Nächster-Zug-Funktion; bildet Teilmenge. Q x Tk in Q x (T x {L, R, S}k ab. D. h. es bildet ein Tupel aus. (q, a1, a2, ..., ak) (ai Tiq Q) in. (q‘, (a‘1, d1), (a‘2, d2), ..., (a‘k, dk)) (dj {L, R, S}) ab.")
152
Arbeitsweise: Die Maschine befindet sich im Zustand q und liest a1 am 1. Band, a2 am 2. Band usw. Sie geht dann in den Zustand q‘, schreibt a‘1 am 1. Band und bewegt den S/L-Kopf gemäß d1; sie schreibt a2 am 2. Band und bewegt den S/L-Kopf gemäß d2 usw. Beispiel: 2-Band-TM die Palindrom auf Band 1 erkennt (nach Aho, Hopcroft, Ullman, „The Design“ ...)
")
153
Vorgangsweise: 1) q0 Anfangszustand Band b b Band 2 b b 2) Maschine schreibt spezielles Symbol X auf Band 2 und kopiert das Wort von Band 1 auf Band 2 q1 b b X b b
 Maschine schreibt spezielles Symbol X auf Band 2 und kopiert das Wort von Band 1 auf Band 2. q b b . . X b b.")
154
3). Die Turingmaschine setzt Lesekopf von Band 2 zurück auf
3) Die Turingmaschine setzt Lesekopf von Band 2 zurück auf X und vergleicht Band 1 mit Band 2 zeichenweise: q2 b b X b
 Die Turingmaschine setzt Lesekopf von Band 2 zurück auf X und vergleicht Band 1 mit Band 2 zeichenweise: q b b. X b.")
155
Definition der Maschine:

156
Beispiel: a1 a2 a3 = 0 1 0; qf = q5 (q , q0) l- (q1 010; xq1) l- (0q1 10, x0q1) l- (01q10, x01q1) l- (010q1, x010q1) l- (010q2, x01q20) l- (010q2, x0q210) l- (010q2, xq2010) l- (010q2, q2x010) l- (01q30, xq3010) l- (01q40, x0q410) l- (0q310, x0q310) l- (0q410, x01q40) l- (q3010, x01q30) l- (q4010, x010q4) l- (q5010, x010q5)
 l- (010q2, x01q20) l- (010q2, x0q210) l- (010q2, xq2010) l- (010q2, q2x010) l- (01q30, xq3010) l- (01q40, x0q410) l- (0q310, x0q310) l- (0q410, x01q40) l- (q3010, x01q30) l- (q4010, x010q4) l- (q5010, x010q5)")
157
Turingmaschine gestattet 2 Interpretationsmöglichkeiten:
A) Sprach-Akzeptor B) Berechnungsautomat zur Berechnung der Funktion f
 Sprach-Akzeptor. B) Berechnungsautomat zur Berechnung der Funktion f.")
158
Sätze zu RAM-Modell und Turing-Maschine
Satz: Ist L eine Sprache, die von einem RAM-Programm in der Zeitkomplexität f (n) verstanden wird, so wird sie von einer Turing- Maschine in einer Zeit verstanden, die in polynomialer Beziehung zu f (n) steht. f1 (n) und f2 (n) stehen zueinander in polynomialer Beziehung, wenn es zwei Polynome p1 (n), p2 (n) gibt, so dass: p2 (f1 (n)) > f2 (n) und p1 (f2 (n)) > f1 (n) gilt! (ohne Division und Multiplikation sogar CTM = 0 (f (n)2)) Beispiel: f1 (n) = 2n3 und f2 (n) = n6 stehen in polynomialer Beziehung zueinander, da für (n6 =) f2 (n) < (2n3)2(= 4n6) p2 (x) = x2 (2n3 =) f1 (n) < 2n6 p1 (x) = 2x
 verstanden wird, so wird sie von einer Turing- Maschine in einer Zeit verstanden, die in polynomialer Beziehung zu f (n) steht. f1 (n) und f2 (n) stehen zueinander in polynomialer Beziehung, wenn es zwei Polynome p1 (n), p2 (n) gibt, so dass: p2 (f1 (n)) > f2 (n) und p1 (f2 (n)) > f1 (n) gilt! (ohne Division und Multiplikation sogar CTM = 0 (f (n)2)) Beispiel: f1 (n) = 2n3 und f2 (n) = n6 stehen in polynomialer Beziehung zueinander, da für. (n6 =) f2 (n) < (2n3)2(= 4n6) p2 (x) = x2. (2n3 =) f1 (n) < 2n6 p1 (x) = 2x.")
159
Nicht-deterministische Turing-Maschine
Definition: der Unterschied einer nicht-deterministischen TM zu einer deterministischen TM liegt in der Abbildung δ: δ : QxTk + (Qx (Tx {L, R, S})k) d. h. δ bildet in Teilmengen ab und ist daher mehrwertig!
k) d. h. δ bildet in Teilmengen ab und ist daher mehrwertig!")
160
Beispiel: Man ändere obiges Palindrombeispiel derart, dass gilt:
Reaktionen: Band 1 Band 2 Band 1 Band 2 Zustand und Übergang q0 0 b 0,S x,R q1 1,S x,R q1 1 b 1,S x,R q1 0,S x,R q0 b,S x,R q1 b b b,S b,S q0 1,S 1,L q1 (q0, 1, b) Führen u.U. nicht (1,S; x,R; q1) (0,S; x,R; q0) (b,S; x,R; q1) nicht zu Akzept! ========== Sinnvoll - führt zu Akzept
 Führen u.U. nicht. (1,S; x,R; q1) (0,S; x,R; q0) (b,S; x,R; q1) nicht zu Akzept! ========== Sinnvoll - führt. zu Akzept.")
161
D. h. es genügt bei einer NDTM die Möglichkeit, bei richtiger Wahl eine Sprache akzeptieren zu können! Definition: Die Zeitkomplexität einer NDTM M ist T (n), wenn für jeden akzeptierten Input-String der Länge n eine Folge von Zügen, die zur Annahme in höchstens T (n) Zügen führt, existiert! Die Speicherkomplexität einer NDTM ist S (n), wenn es eine Zugfolge gibt, so dass nach höchstens S (n) unterschiedlichen Inputlesungen auf verschiedenen Feldern am Band das Eingabewort akzeptiert werden kann.
, wenn für jeden akzeptierten Input-String der Länge n eine Folge von Zügen, die zur Annahme in höchstens T (n) Zügen führt, existiert! Die Speicherkomplexität einer NDTM ist S (n), wenn es eine Zugfolge gibt, so dass nach höchstens S (n) unterschiedlichen Inputlesungen auf verschiedenen Feldern am Band das Eingabewort akzeptiert werden kann.")
162
Die Problemklassen P und NP
Definition: a) Wir bezeichnen die Menge aller Probleme (Sprachen), die von einer det.TM in polynomialer Zeit gelöst (akzeptiert) werden können, als Probleme in P. b) Wir bezeichnen die Menge aller Probleme (Sprachen), die nur von einer nicht-deterministischen TM in polynomialer Zeit gelöst (akzeptiert) werden können als Problem in NP.
 Wir bezeichnen die Menge aller Probleme (Sprachen), die von einer det.TM in polynomialer Zeit gelöst (akzeptiert) werden können, als Probleme in P. b) Wir bezeichnen die Menge aller Probleme (Sprachen), die nur von einer nicht-deterministischen TM in polynomialer Zeit gelöst (akzeptiert) werden können als Problem in NP.")
163
Satz:. Eine nicht-deterministische TM lässt sich von einer DTM in
Satz: Eine nicht-deterministische TM lässt sich von einer DTM in 0DTM(cT(n)) simulieren, wenn die Zeitkomplexität auf den NDTM T(n) war (milde Beschränkungen sind erforderlich). Satz: Eine nicht-deterministische TM lässt sich von einer DTM in der Speicherkomplexität 0DTM(S(n2) simulieren, wenn S (n) die Speicherkomplexiät auf der NDTM war (milde Beschränkungen ähnlich zu oben!).
) simulieren, wenn die Zeitkomplexität auf den. NDTM T(n) war (milde Beschränkungen sind erforderlich). Satz: Eine nicht-deterministische TM lässt sich von einer DTM in der Speicherkomplexität 0DTM(S(n2) simulieren, wenn S (n) die Speicherkomplexiät auf der NDTM war (milde Beschränkungen ähnlich zu oben!).")
164
Korollar: A) Algorithmen, die von NDTM in polynomialer Zeit T(n) ausgeführt werden können, können von DTM in der Zeit 0(cT(n)) - also in exponentieller Zeit - ausgeführt werden. B) Der Speicherbedarf S (n) bleibt bei der Simulation im polynomialen Bereich, wenn er zuvor polynomial war. Definition: Ist ein Problem p NP und können Probleme pi (i = 1, 2, ...) derart umgeformt werden, dass die Probleme pi nach Umformung mit dem Lösungsalgorithmus von p gelöst werden können, so heißen p, pi(i = 1, 2, ....) NP- vollständig! Bemerkung: Es gibt Probleme in NP die nicht NP-vollständig sind!
 Algorithmen, die von NDTM in polynomialer Zeit T(n) ausgeführt werden können, können von DTM in der Zeit 0(cT(n)) - also in exponentieller Zeit - ausgeführt werden. B) Der Speicherbedarf S (n) bleibt bei der Simulation im polynomialen Bereich, wenn er zuvor polynomial war. Definition: Ist ein Problem p NP und können Probleme. pi (i = 1, 2, ...) derart umgeformt werden, dass die Probleme pi nach Umformung mit dem Lösungsalgorithmus von p gelöst werden können, so heißen p, pi(i = 1, 2, ....) NP- vollständig! Bemerkung: Es gibt Probleme in NP die nicht NP-vollständig sind!")
165
co NP Problem der zusammen- P
Problemklassen: I) Nur Zeitkomplexität Beweisbar unlösbare Probleme: Halteprobleme von TM Beweisbar NP-schwere Probleme Ja-nein-Probleme, NP-vollständige deren Komplementärprobleme Probleme in NP sind!! NP co NP Problem der zusammen- gesetzten Zahlen P
 Nur Zeitkomplexität. Beweisbar unlösbare Probleme: Halteprobleme von TM. Beweisbar NP-schwere Probleme. Ja-nein-Probleme, NP-vollständige. deren Komplementärprobleme Probleme. in NP sind!! NP. co NP Problem der zusammen- gesetzten Zahlen. P.")
166
NP-Zeit P-Zeit II) Zeit- und Speicherkomplexität
Nicht-endlicher Speicher Nicht-polynomiale Speicherkomplexität Polynomiale Speicherkomplexität NP-Zeit P-Zeit

167
Probleme in P: Matrixmultiplikation 0 (n2.71) - 0 (n3) mult. Sortierprobleme (0 (nlogn) - 0 (n3)) Auffinden des nächsten Paares (0 (n2) - 0 (n)) Minimal Spannender Baum (Minimalgerüst) Eulerscher Graph (0 (cn) - 0 (n))
 - 0 (n)) Minimal Spannender Baum (Minimalgerüst) Eulerscher Graph (0 (cn) - 0 (n))")
168
NP-vollständige Probleme:
Probleme in NP: NP-vollständige Probleme: Dynamische Programmierung Ganzzahlige Programmierung Travelling-Salesman-Probleme Cluster-Probleme Hamiltonscher Kreis Einige Scheduling-Algorithmen Knapsack-Problem Quadratisches Zuordnungsproblem SET-Covering-Problem Probleme in NP und nicht NP-vollständig Das Problem, ob eine Zahl p eine Primzahl ist.

169
1012 1011 1010 109 108 107 106 105 104 103 102 101 100 nn ni 2n n3 + n2 + n + 1 n2 + n + 1 n + 1 n

170
Approximative Algorithmen: I = Problemdaten
Opt (I) = Optimallösungswert A (I) = Wert der Zielfunktion bei approximativer Lösung 1) Approximation der Optimallösung durch Approximation im Zielfunktionswert: Opt (I) - A (I) Maximierungsproblem: minimiere (= s) Opt (I) (Minimierungsproblem analog!) Es ist also Konvergenz im Zielfunktionswert erwünscht, d.h. lim s T (n) S (n)
 = Optimallösungswert. A (I) = Wert der Zielfunktion bei. approximativer Lösung. 1) Approximation der Optimallösung durch Approximation im Zielfunktionswert: Opt (I) - A (I) Maximierungsproblem: minimiere (= s) Opt (I) (Minimierungsproblem analog!) Es ist also Konvergenz im Zielfunktionswert erwünscht, d.h. lim s 0. T (n) S (n)")
171
2). Approximation der Optimallösung durch Auffinden der optimalen
2) Approximation der Optimallösung durch Auffinden der optimalen Lösung mit einer gewissen Wahrscheinlichkeit: Maximiere: W (A (I) = opt (I)) Es ist also Konvergenz in der Wahrscheinlichkeit erwünscht, d.h. lim W (A (I) = opt (I)) T (n) S (n) 3) Mischform aus 1) und 2) Maximiere W (s 0) für jeden Wert des Paares (T (n), S (n))
 Approximation der Optimallösung durch Auffinden der optimalen Lösung mit einer gewissen Wahrscheinlichkeit: Maximiere: W (A (I) = opt (I)) Es ist also Konvergenz in der Wahrscheinlichkeit erwünscht, d.h. lim W (A (I) = opt (I)) 1. T (n) S (n) 3) Mischform aus 1) und 2) Maximiere W (s 0) für jeden Wert des Paares (T (n), S (n))")
172
Approximative Algorithmen vom 1. Typ
A) s-approximative Verfahren opt (I) - A (I) Offenbar gilt: 0 < (= s) < 1. opt (I) Definition: Unter einem s-approximativen Verfahren versteht man ein Verfahren mit der Eigenschaft, dass für jeden Input I des Problems gilt: < s Definition: Eine Schranke heißt eng, wenn zu jedem ε > 0 ein I derart existiert, dass + ε > s
 s-approximative Verfahren. opt (I) - A (I) Offenbar gilt: 0 < (= s) < 1. opt (I) Definition: Unter einem s-approximativen Verfahren versteht man ein Verfahren mit der Eigenschaft, dass für jeden Input I des Problems gilt: < s. Definition: Eine Schranke heißt eng, wenn zu jedem ε > 0 ein I derart existiert, dass. + ε > s.")
173
Beispiel Rucksackproblem:
n Maximiere z = Σ ci xi unter der Nebenbedingung: i = 1 Σ ai xi < b; (xi > 0 und ganzzahlig) Es gelte b, ai, ci > 0 und ai < b.
 Es gelte b, ai, ci > 0 und ai < b.")
174
Heuristischer Algorithmus A:
Es gelte c1/ a1 > c2/ a2 > > cn/ an V A ALG X (N, B: Globale Var.) [1] I S 0 [2] LOOP: I I + 1 [3] X [I] L (B - S) : A [I] [4] S S + A [I] X [I] [5] (I < N) / LOOP V Bemerkung: Man packt jene Objekte in größtmöglicher Anzahl in den Rucksack, deren Wert je Gewichtseinheit maximal ist; (Anzahl des i-ten Objekts = x) Rucksack: Wert: L1 L2 L Ln Objekte: O O O O Gew. a1 a2 a3 an
 [1] I S 0. [2] LOOP: I I + 1. [3] X [I] L (B - S) : A [I] [4] S S + A [I] X [I] [5] (I < N) / LOOP. V. Bemerkung: Man packt jene Objekte in größtmöglicher Anzahl in den Rucksack, deren Wert je Gewichtseinheit maximal ist; (Anzahl des i-ten Objekts = x) Rucksack: Wert: L1 L2 L3 Ln. Objekte: O O O O. Gew. a1 a2 a3 an.")
175
Satz: der Algorithmus ALG ist ein ½- approximatives Verfahren.
dissl: Bis hierher wurde korrigiert. 19/01/04 Satz: der Algorithmus ALG ist ein ½- approximatives Verfahren. Begründung: b Offenbar gilt: opt (I) < c1 —; a1 c1 [—] < A (I); b b [—] b - [—] a1 opt (I) - A (I) A (I) a a b/2 Also = < = < = 1/2 opt (I) opt (I) b b b — b/2 Bemerkung: Die Schranke ist eng. b Beispiel: Für n = 2; c1 = p + 2; a1 = p + 1; c2 = a2 = p > 3 und b = 2p gilt: opt (I) - A (I) p p - 2 = ; jedoch gilt lim = 1/2 opt (I) p p p
 < c1 —; a1. c1 [—] < A (I); b b. [—] b - [—] a1. opt (I) - A (I) A (I) a1 a1 b/2. Also = 1 - < 1 - = < = 1/2. opt (I) opt (I) b b b. — b/2. Bemerkung: Die Schranke ist eng. b. Beispiel: Für n = 2; c1 = p + 2; a1 = p + 1; c2 = a2 = p > 3 und b = 2p. gilt: opt (I) - A (I) p - 2 p - 2. = ; jedoch gilt lim = 1/2. opt (I) 2p 2p. p")
176
Approximationsschemata
Definition: Sei p ein diskretes Optimierungsproblem und existiert zu jedem ε > 0 ein polynomial beschränktes ε-approximatives Verfahren A (ε) das p löst, so heißt die Familie von Verfahren {A (ε) | ε > 0} (polynomial beschränktes) Approximationsschema Beispiel: binäres Rucksackproblem: (es darf höchstens 1 Stück einer Art hineingepackt werden, d. h. xi {0, 1}.) Sahni zeigt, dass hierfür ein polynomial beschränktes Approximationsschema existiert, dessen Zeitkomplexität mit seiner Güte „ε“ EXPONENTIELL wächst.
 das p löst, so heißt die Familie von Verfahren. {A (ε) | ε > 0} (polynomial beschränktes) Approximationsschema. Beispiel: binäres Rucksackproblem: (es darf höchstens 1 Stück einer Art hineingepackt werden, d. h. xi {0, 1}.) Sahni zeigt, dass hierfür ein polynomial beschränktes Approximationsschema existiert, dessen Zeitkomplexität mit seiner Güte „ε EXPONENTIELL wächst.")
177
Definition:. ein approximatives Verfahren, dessen Rechenaufwand
Definition: ein approximatives Verfahren, dessen Rechenaufwand durch ein Polynom, welches die „Länge“ des Inputs und die Approximationsgüte als Argument besitzt, beschränkt ist, heißt gleichmäßig polynomial beschränktes Approximationsschema! Bemerkung: Für spezielle Varianten des Rucksackproblems gibt es ein gleichmäßig polynomial beschränktes Approximationsschema (Beweis: Sahni)
")
178
Travelling-Salesman-Problem

180
N. Christofides-Algorithmus ((s = 1,5); 0 (n³))
; 0 (n³))")
181
Approx. Algorithmus: (Probabilistisches Approximationsschema)
Vorausgesetzt: t (n) sei eine Funktion: t : N R+, derart, dass A. T (N) log2 log2 n n B. für alle n sei — ein Quadrat einer Zahl ε N. t
 sei eine Funktion: t : N R+, derart, dass. A. T (N) log2 log2 n. n. B. für alle n sei — ein Quadrat einer Zahl ε N. t.")
182
Karps Algorithmus: 1. Teile das Einheitsquadrat in ein regelmäßiges Gitter aus t (n) n/T (n) (= N/log2 log2 N) Teilquadraten mit der Seitenlänge n 2. Unter Verwendung eines dynamischen Programmierungs- algorithmus (nach Karp 0 (m2m) bei m Orten) werde eine optimale Tour für die Menge von Punkten im Subquadrat ermittelt: (n/log2 log2 n) Quadrate mit jeweils „ungefähr“ log2 log2 n Orten; also ~ 0 ((n/(log2 log2 n)) (log2 log2 n) log2 n) = 0 (n log2 n) Berechnungen. 3. A) Jede der n/t (n) Subtouren werde als Punkt betrachtet. (Als Distanz zwischen zwei „Punkten“ in P1 und P2 werde die „kürzeste“ Distanz zwischen irgendzwei Punkten in P1 und P2 gewählt; Komplexität: 0 ((n/log2 log2 n) log2 log2 n) = 0 (n). B) Konstruiere ein Minimalgerüst, dass die Subtouren verbindet (Komplexität: 0 ((n/log2 log2 n) log log (n/ log2 log2 n)) < < 0 (n log log n)
 (= N/log2 log2 N) Teilquadraten mit der Seitenlänge n. 2. Unter Verwendung eines dynamischen Programmierungs- algorithmus (nach Karp 0 (m2m) bei m Orten) werde eine optimale Tour für die Menge von Punkten im Subquadrat ermittelt: (n/log2 log2 n) Quadrate mit jeweils „ungefähr log2 log2 n Orten; also ~ 0 ((n/(log2 log2 n)) (log2 log2 n) log2 n) = 0 (n log2 n) Berechnungen. 3. A) Jede der n/t (n) Subtouren werde als Punkt betrachtet. (Als Distanz zwischen zwei „Punkten in P1 und P2 werde die „kürzeste Distanz zwischen irgendzwei Punkten in P1 und P2 gewählt; Komplexität: 0 ((n/log2 log2 n) log2 log2 n) = 0 (n). B) Konstruiere ein Minimalgerüst, dass die Subtouren verbindet (Komplexität: 0 ((n/log2 log2 n) log log (n/ log2 log2 n)) < < 0 (n log log n)")
183
4. Konstruiere einen geschlossenen Weg W, der jede Subtour genau
4. Konstruiere einen geschlossenen Weg W, der jede Subtour genau 1 mal durchläuft und jede Kante des Baumes 2 mal. W ist die gesuchte Lösung. Satz von Karp: Sei I ein T-S-Problem mit zufällig (gleichverteilten) Orten im Quader Q. Obiger Algorithmus findet eine mit dem Faktor (1 + ε) (ε > 0) garantiert „fast überall“ optimale Lösung in der Zeit 0 (n log n). Bemerkung: Der Satz von Karp basiert auf einem Theorem von Beardwood, J., Et Al. (1959), dass der Minimalumfang eines Polygons mit n Ecken, die „zufällig“ im ebenen Quadrat Q gewählt wurden, innerhalb von ε „fast überall“ um (C n A)0,5 liegt. (A = Fläche von Q; n = Anzahl der Ecken; lim c = 0,75). n (N = 1000; A = 1; (C N A)0,5 ~ 27)
 Orten im Quader Q. Obiger Algorithmus findet eine mit dem Faktor (1 + ε) (ε > 0) garantiert „fast überall optimale Lösung in der Zeit 0 (n log n). Bemerkung: Der Satz von Karp basiert auf einem Theorem von Beardwood, J., Et Al. (1959), dass der Minimalumfang eines Polygons mit n Ecken, die „zufällig im ebenen Quadrat Q gewählt wurden, innerhalb von ε „fast überall um (C n A)0,5 liegt. (A = Fläche von Q; n = Anzahl der Ecken; lim c = 0,75). n (N = 1000; A = 1; (C N A)0,5 ~ 27)")
184
Weg des Karp‘schen Algorithmus
(Euklid‘sches 52-Städte Problem) 1) t ~ log2 log2 52 ~ 2,51 ~ 3 n 3) — = 14; kein perfektes Quadrat n/t sei 16 oder 9. t Wir wählen n/t = 9; folglich t = 5,7. 4) Einheitsquader wird in 9 Quader mit der Seitenlänge: 5) Ermittle optimale Rundreisen in den Quadr. (dyn. Progr.) 6) Ermittle ein MINIMALGERÜST (mit „nächsten“ Punkten).
 1) t ~ log2 log2 52 ~ 2,51 ~ 3. n. 3) — = 14; kein perfektes Quadrat n/t sei 16 oder 9. t. Wir wählen n/t = 9; folglich t = 5,7. 4) Einheitsquader wird in 9 Quader mit der Seitenlänge: 5) Ermittle optimale Rundreisen in den Quadr. (dyn. Progr.) 6) Ermittle ein MINIMALGERÜST (mit „nächsten Punkten).")
185
Zeitkomplexität: 0 (n log2 n)
Lösungsgüte: „Fast überall“ für ε > 0 innerhalb (1 + ε) x Opt.
 x Opt.")
186
P = Mengensystem von berechenbaren Problemen
I. Begriffe P = Mengensystem von berechenbaren Problemen P = ein berechenbares Problem p = Problemstellung eines berechenbaren Problems P Es gilt daher: P P und p P

187
Problemgröße eines berechenbaren Problems:
Es gibt eine Funktion, die die Menge der Problemstellungen in die Menge der positiven ganzen Zahlen abbildet: g : P N+ Der Wert g (p) = n heiße Größe der Problemstellung p. Bemerkung: P kann in disjunkte Teilmengen PN zerlegt werden; es gelte: Pn = {p p P und g (p) = N} Weiteres gilt: U Pn = P N
 = n heiße Größe der Problemstellung p. Bemerkung: P kann in disjunkte Teilmengen PN zerlegt werden; es gelte: Pn = {p p P und g (p) = N} Weiteres gilt: U Pn = P. N.")
188
Algorithmen zur Lösung eines Problems
Die Lösungsvorschrift A zur Lösung eines berechenbaren Problems P nennen wir einen Algorithmus. Mit AP bezeichnen wir die Menge aller Algorithmen zur Lösung von P: AP = {A A löst P für alle Problemstellungen p P} Effizienz eines Algorithmus Unter der Effizienz eines Algorithmus A verstehen wir die Laufzeit eines Algorithmus A zur Lösung von p P: TA (p) und seinen Speicherbedarf: SA (p)
 und seinen Speicherbedarf: SA (p)")
189
Worst-Case-Zeitkomplexität eines Algorithmus:
Bemerkung: Es interessiert hier das Laufzeitverhalten eines Algorithmus A. Wir drücken die Laufzeit in der Anzahl der erforderlichen Berechnungsschritte aus und Sprechen von der Zeitkomplexität des Algorithmus. Worst-Case-Zeitkomplexität eines Algorithmus: Die Worst-Case-Komplexität TA (p) eines Algorithmus A ist definiert durch: TA (n) = max {tA (p) | p Pn} Mittlere Zeitkomplexität eines Algorithmus Wir bezeichnen mit wi die Wahrscheinlichkeit für das Auftreten der Problemstellung pi der Größe n, d. h: pi Pn. Unter der mittleren Zeit-Komplexität E (tA) verstehen wir den Erwartungswert: E (tA) = wi tA (pi) i
 eines Algorithmus A ist definiert durch: TA (n) = max {tA (p) | p Pn} Mittlere Zeitkomplexität eines Algorithmus. Wir bezeichnen mit wi die Wahrscheinlichkeit für das Auftreten der Problemstellung pi der Größe n, d. h: pi Pn. Unter der mittleren Zeit-Komplexität E (tA) verstehen wir den Erwartungswert: E (tA) = wi tA (pi) i.")
190
Definition: Probabilistischer Algorithmus (nach Rabin [3])
(b1, b2, ..., bM) bezeichne eine Stichprobe rM vom Umfang m aus der Menge Z; (meist gilt Z = {0, 1, 2, ... n-1}). RM bezeichne die Menge aller Stichproben rM aus Z. Es gelte R = U RM M (Die Elemente von R bezeichnen wir mit r)
![Definition: Probabilistischer Algorithmus (nach Rabin [3])](http://slideplayer.org/slide/11848645/66/images/190/Definition%3A+Probabilistischer+Algorithmus+%28nach+Rabin+%5B3%5D%29.jpg "(b1, b2, ..., bM) bezeichne eine Stichprobe rM vom Umfang m aus der Menge Z; (meist gilt Z = {0, 1, 2, ... n-1}). RM bezeichne die Menge aller Stichproben rM aus Z. Es gelte. R = U RM. M. (Die Elemente von R bezeichnen wir mit r)")
191
EA (pi) = EA (pj) für pi, pj, Pn mit
Unter einem randomisierten Algorithmus A verstehen wir einen Algorithmus, der unter Einbeziehung der Stichprobe r R jede Problemstellung p Pn mit der erwarteten Zeitkomplexität EA (n) löst: EA (n) = EA (pi) und EA (pi) = EA (pj) für pi, pj, Pn mit EA (pi) = tA (r, pi) x W (|r| = m r = rM) r R tA (r, pi) = Laufzeit des Algorithmus A bei Problemstellung pi und der Stichprobe r R W (|r| = m r = rM) = Wahrscheinlichkeit, eine spezielle Stichprobe vom Umfang M (rM RM) zu ziehen. Bemerkung: Auf analogem Wege kann man gewöhnliche und zentrale Momente der Laufzeitverteilung einführen. Häufig ist der Stichprobenumfang vorgegeben und keine Zufallsgröße, weiter ist uns kein Fall bekannt, in dem die Elemente aus Z nicht als eine Zufallsstichprobe (mit oder ohne Zurücklegen) gezogen werden.
 löst: EA (n) = EA (pi) und. EA (pi) = EA (pj) für pi, pj, Pn mit. EA (pi) = tA (r, pi) x W (|r| = m r = rM) r R. tA (r, pi) = Laufzeit des Algorithmus A bei Problemstellung pi und. der Stichprobe r R. W (|r| = m r = rM) = Wahrscheinlichkeit, eine spezielle Stichprobe vom Umfang M (rM RM) zu ziehen. Bemerkung: Auf analogem Wege kann man gewöhnliche und zentrale Momente der Laufzeitverteilung einführen. Häufig ist der Stichprobenumfang vorgegeben und keine Zufallsgröße, weiter ist uns kein Fall bekannt, in dem die Elemente aus Z nicht als eine Zufallsstichprobe (mit oder ohne Zurücklegen) gezogen werden.")
192
(Randomisierte approximative) probabilistische Algorithmen
Unter einem probabilistischen Algorithmus A verstehen wir einen Algorithmus, der nicht jede Problemstellung mit Sicherheit lösen kann. Der probabilistische Algorithmus soll jede Problemstellung pi Pn mit einer (angebbaren) Mindestsicherheit lösen; hier gibt es zwei Möglichkeiten (bzw. Kombinationen): A) Es ist eine untere Schranke für die Wahrscheinlichkeit, die Lösung gefunden zu haben, bekannt. B) Es ist eine Schranke für das maximale Ausmaß der Abweichung des Wertes P gefundenen Lösung vom Wert der gesuchten Lösung bekannt.
 Mindestsicherheit lösen; hier gibt es zwei Möglichkeiten (bzw. Kombinationen): A) Es ist eine untere Schranke für die Wahrscheinlichkeit, die Lösung gefunden zu haben, bekannt. B) Es ist eine Schranke für das maximale Ausmaß der Abweichung des Wertes P gefundenen Lösung vom Wert der gesuchten Lösung bekannt.")
193
II. Beispiele probabilistischer Algorithmen
Rabin gibt selbst einen probabilistischen Algorithmus zur Feststellung der Primalität einer Zahl N und einen mit Sicherheit lösenden Algorithmus zur Feststellung eines Paares von Punkten minimaler Distanz an (randomisiert).
.")
194
Zu 1: Nearest-Pair-Algorithmus
Beispiel eines Problems (2-dimensionale Problemstellung bei euklidscher Distanz): Gegeben sei eine Menge X von Punkten X = {x1, x2, ... xn} Im 2. Gesucht ist jenes Paar (xq, xp), für das xq xp und D (xq, xp) = min {D (xi, xj)| xi xj und xi, xj X} mit D (xi, xj) = (1xi - 1xj)2 + (2xi - 2xj)2 gilt; (1xi, 2xi bezeichnen den Wert der ersten und zweiten Koordinate von xi). Eine wesentliche Überlegung für das Design des Rabin‘schen Algorithmus ist die Einführung eines Gitters mit konstanter Maschenweite über dem 2.
: Gegeben sei eine Menge X von Punkten. X = {x1, x2, ... xn} Im 2. Gesucht ist jenes Paar (xq, xp), für das xq xp. und D (xq, xp) = min {D (xi, xj)| xi xj und xi, xj X} mit D (xi, xj) = (1xi - 1xj)2 + (2xi - 2xj)2 gilt; (1xi, 2xi bezeichnen den Wert der ersten und zweiten Koordinate von xi). Eine wesentliche Überlegung für das Design des Rabin‘schen Algorithmus ist die Einführung eines Gitters mit konstanter Maschenweite über dem 2.")
195
Qxi Grundüberlegung: IV. xj III. δ I. II. δ
1) Man lege ein Gitter mit der Maschenweite δ über den R2 2) Liegt ein Punkt xi im Quadranten Q eines Gitters der Maschenweite δ, so kann ein Punkt xj, für den gilt d (xi, xj) < δ, nicht außerhalb des schraffierten Bereichs liegen. 3) Lege ich vier Gitter mit der Maschenweite 2 δ und den Eckpunkten I., II., III., IV. über den R2, so muss jedes Paar xi, xj mit d (xi, xj) < δ in einem Quadranten eines der (vier) Gitter liegen.
 Man lege ein Gitter mit der Maschenweite δ über den R2. 2) Liegt ein Punkt xi im Quadranten Q eines Gitters der Maschenweite δ, so kann ein Punkt xj, für den gilt d (xi, xj) < δ, nicht außerhalb des schraffierten Bereichs liegen. 3) Lege ich vier Gitter mit der Maschenweite 2 δ und den Eckpunkten I., II., III., IV. über den R2, so muss jedes Paar xi, xj mit d (xi, xj) < δ in einem Quadranten eines der (vier) Gitter liegen.")
196
Algorithmus:. (erwartete Zeitkomplexität 0 (N) im Gegensatz zu
Algorithmus: (erwartete Zeitkomplexität 0 (N) im Gegensatz zu (n log n) u. höher) 1) Ziehe eine Zufallsstichprobe vom Umfang n4/9 aus X: n8/9 - n4/9 Errechne in maximal ————– Schritten (0 (n)) das Wertepaar 2 d (sq, sp) mit minimaler Distanz δ. 2) Ziehe eine Zufallsstichprobe vom Umfang von n2/3 Elementen. Lege hierüber vier Gitter mit der Maschenweite von 2 δ. Bilde für jedes der vier Gitter die Mengen I II III IV 'S , 'S , 'S , 'S , (1 < i < n2/3), die die Punkte der Stichprobe in i i i i den einzelnen Quadranten enthalten. Ermittle das Paar (xp, xq) minimaler Distanz δ.
 im Gegensatz zu 0 (n log n) u. höher) 1) Ziehe eine Zufallsstichprobe vom Umfang n4/9 aus X: n8/9 - n4/9. Errechne in maximal ————– Schritten (0 (n)) das Wertepaar. 2. d (sq, sp) mit minimaler Distanz δ. 2) Ziehe eine Zufallsstichprobe vom Umfang von n2/3 Elementen. Lege hierüber vier Gitter mit der Maschenweite von 2 δ. Bilde für jedes der vier Gitter die Mengen. I II III IV. S , S , S , S , (1 < i < n2/3), die die Punkte der Stichprobe in. i i i i. den einzelnen Quadranten enthalten. Ermittle das Paar (xp, xq) minimaler Distanz δ.")
197
3). Lege wieder VIER Gitter der Maschenweite 2 δ über die
3) Lege wieder VIER Gitter der Maschenweite 2 δ über die Punktemenge X und bilde die Mengen: I II III IV S , S , S , S , (i < n). i i i i 4) Ermittle das Punktpaar minimaler Distanz (xi, xj); I II III IV xi und xj müssen beide in einer der Mengen S , S , S , S , (i < n) i i i i liegen.
 Lege wieder VIER Gitter der Maschenweite 2 δ über die Punktemenge X und bilde die Mengen: I II III IV. S , S , S , S , (i < n). i i i i. 4) Ermittle das Punktpaar minimaler Distanz (xi, xj); I II III IV. xi und xj müssen beide in einer der Mengen S , S , S , S , (i < n) i i i i. liegen.")
198
Zu 2) Approximativer Algorithmus zur Feststellung der Primalität
Aufgabe: Es soll für eine Zahl n festgestellt werden, ob n eine Primzahl ist. Verfahren: Geht von einem Satz von Miller [2] aus. Millers Satz: Sei n eine natürliche Zahl und es gelte 1 < b < n. Sei W (b) die Aussage: (1) bn-1mod n 1 oder n - 1 (2) i ( = m und m ganzzahlig und 2i 1 < GGT (bm - 1,n) < n). Ist W (b) richtig für b {1, 2, ..., n - 1}, dann heißt n zusammengesetzt und b heißt ZEUGE der Zusammengesetztheit von n. Rabin‘s Satz: Ist n zusammengesetzt, so gibt es mindestens 2 Zahlen b, für die W (b) gilt.
 die Aussage: (1) bn-1mod n 1 oder. n - 1. (2) i ( = m und m ganzzahlig und. 2i. 1 < GGT (bm - 1,n) < n). Ist W (b) richtig für b {1, 2, ..., n - 1}, dann heißt n zusammengesetzt und b heißt ZEUGE der Zusammengesetztheit von n. Rabin‘s Satz: Ist n zusammengesetzt, so gibt es mindestens. 2. Zahlen b, für die W (b) gilt.")
199
Der Algorithmus: Problem: Ist n eine Primzahl?
1) Es werden m Zahlen 1< b1 < n, ..., 1 < bm < n zufällig aus {1, 2, .... n - 1} gezogen. 2) Ist W (b) für alle bi (i = 1, 2, ... m) nicht gültig, so schließen wir hieraus, dass n Prim sei. Gilt W (bi) mindestens ein Mal, so ist n zusammengesetzt! n n Stichprobe: bi bi bi bim
 Es werden m Zahlen. 1< b1 < n, ..., 1 < bm < n. zufällig aus {1, 2, .... n - 1} gezogen. 2) Ist W (b) für alle bi (i = 1, 2, ... m) nicht gültig, so schließen wir hieraus, dass n Prim sei. Gilt W (bi) mindestens ein Mal, so ist n zusammengesetzt! n1 n. Stichprobe: bi1 bi2 bi bim.")
200
Bemerkung: Auf Grund des Theorems von Rabin folgt für ein n, dass die Irrtumswahrscheinlichkeit kleiner ½m ist, wenn der Umfang der Zufallsstichprobe m ist! Bemerkenswert an diesem probabilistischen Algorithmus ist der Umstand, dass der Ertrag aus der (Zufalls-)Stichprobe einen monot. zunehmenden Verlauf aufweist; kein „Laufzeit Opt.“ Stichprobenumfang.
Stichprobe einen monot. zunehmenden Verlauf aufweist; kein „Laufzeit Opt. Stichprobenumfang.")
201
Primalitätsalogorithmus:
Ertrag der Stichprobe 1 1 1 - —— Schranke für Primalitätsw. 2m M (Kosten) Stichprobenumfang
 Stichprobenumfang.")
202
Nearest-Pair-Algorithums:
Laufzeit M2 n2 - n 2 M2opt M1opt M1 M1 Erster bzw. zweiter Stichprobenumfang M2 M1opt optimaler Stichprobenumfang M2opt

203
Offene Fragen: 1) Sind zwei sukzessive gezogene Zufallsstichproben optimal? 2) Welche Stichprobenumfänge sind optimal? 3) Kann man Pn in weitere Unterklassen teilen, für die verschieden effiziente und jeweils optimale Politiken angebbar sind? 4) Soll die Entscheidung über weitere größere Stichproben nicht mehrstufig gefällt werden?
 Kann man Pn in weitere Unterklassen teilen, für die verschieden effiziente und jeweils optimale Politiken angebbar sind 4) Soll die Entscheidung über weitere größere Stichproben nicht mehrstufig gefällt werden")
204
Ein Suchproblem und einige Lösungen:
Gegeben: Eine Menge S von n unterschiedlichen positiven ganzen Zahlen. s1 < s2 < ... < sn Die einfach geschlossen verkettet in aufsteigender Sortierordnung und (o.b.d.a.) auf benachbarten Speicherplätzen gespeichert sind. Z. B. gelte n = 5: Anker: a s1 s2 s3 s4 s5 Adressen: a0+4 a0+1 a0 a0+3 a0+2 (Zufallspermutation) Problem: Erfolgreiche Suche nach s S.
 auf benachbarten Speicherplätzen gespeichert sind. Z. B. gelte n = 5: Anker: a0 + 4 s1 s2 s3 s4 s5. Adressen: a0+4 a0+1 a0 a0+3 a0+2. (Zufallspermutation) Problem: Erfolgreiche Suche nach s S.")
205
I.) Nicht probabilistische Lösung: Algorithmus A‘
Gegeben: Ausgezeichnete Anfangsadresse zu Beginn der Suche: Anker Algorithmus: Beginnend mit dem an der Ankeradresse gespeicherten Element wird unter der Verkettung so lange sequentiell gesucht, bis das gesuchte Element s gefunden wurde. II.) Einfache probabilistische Lösung: A Es wird nicht eine feste Ankeradresse verwendet, sondern durch eine Stichprobe vom Umfang m = 1 die Ankeradresse zufällig bestimmt. n + 1 Erwartete Komplexität: ———– (= EA (n)) 2
 Einfache probabilistische Lösung: A. Es wird nicht eine feste Ankeradresse verwendet, sondern durch eine Stichprobe vom Umfang m = 1 die Ankeradresse zufällig bestimmt. n + 1. Erwartete Komplexität: ———– (= EA (n)) 2.")
206
Probabilistischer Algorithmus
1) Wir erzeugen Zufallszahlen (b1, b2, ...) aus {0, 1, .... n - 1}. (Durch jede Zahl bi ist ein Tabellenelement bestimmt, welches an der Adresse bi gespeichert ist.) 2) Nach Beendigung der Erzeugung zufälliger Adressen und ihrer Auswertung beginnen wir, das gesuchte Element sequentiell über die Verkettung aufzusuchen. Als Anker verwenden wir jeweils jenes Tabellenelement, welches unter allen durch die zufällig erzeugten Adressen (b1, b2 ...) bestimmten Tabellenelemente den kleinsten Distanzwert aufweist.
 Wir erzeugen Zufallszahlen (b1, b2, ...) aus {0, 1, .... n - 1}. (Durch jede Zahl bi ist ein Tabellenelement bestimmt, welches an der Adresse bi gespeichert ist.) 2) Nach Beendigung der Erzeugung zufälliger Adressen und ihrer Auswertung beginnen wir, das gesuchte Element sequentiell über die Verkettung aufzusuchen. Als Anker verwenden wir jeweils jenes Tabellenelement, welches unter allen durch die zufällig erzeugten Adressen (b1, b2 ...) bestimmten Tabellenelemente den kleinsten Distanzwert aufweist.")
207
Bemerkung:. Der Umfang der Zufallsstichprobe kann entweder von
Bemerkung: Der Umfang der Zufallsstichprobe kann entweder von vornherein festgelegt werden, oder aber selbst eine Zufallsvariable sein, wenn wir ein Stoppkriterium einführen. Je nach Stoppkriterium und Art der Ziehung (O. Z. oder M. Z.) kann der Stichprobenumfang auch potentiell unendlich sein. s1 s sq sq si si sj .... sn Gesucht Distanz bi bik bi k bm Nächstes Element Zufallsstichprobe
 kann der Stichprobenumfang auch potentiell unendlich sein. s1 s sq sq si si sj .... sn. Gesucht. Distanz. bi bik bi k bm. Nächstes Element. Zufallsstichprobe.")
208
Einige grundlegende Zusammenhänge und Begriffe:
Definition 1: Unter einer Abstandsfunktion d für eine in aufsteigender Sortierordnung geschlossen verkettet implementierte Tabelle mit den Elementen S = {s1, s2, ... sn} und s1 < s2 < ... < sn verstehen wir die Funktion: si - sj für sj < si, d (si, sj) = nd - sj + si für si < sj; d = (sn - s1) / n - 1 und heißt durchschnittlicher Abstand.
 = nd - sj + si für si < sj; d = (sn - s1) / n - 1 und heißt durchschnittlicher Abstand.")
209
Definition 2: Unter der Abstandsmatrix D verstehen wir eine Matrix mit den Komponenten dij = d (si, sj). Bemerkung: Die Abstandsmatrix D ist nicht unbedingt symmetrisch. Definition 3: Unter der Matrix von sequentiellen Suchschritten verstehen wir eine Matrix Z mit den Komponenten zij = z (si, sj). z (si, sj) bezeichnet die Anzahl von sequentiellen Suchschritten, wenn wir si von sj ausgehend sequentiell aufsuchen. Unter einem sequentiellen Suchschritt verstehen wir das Aufsuchen eines Elements aus S über die Verkettung und den Vergleich des gefundenen Elements mit dem gesuchten Wert. Bemerkung: z. B. erhalten wir zij = 0, wenn si = sj, und zij = 2, wenn si = sj+2 gilt.
. z (si, sj) bezeichnet die Anzahl von sequentiellen Suchschritten, wenn wir si von sj ausgehend sequentiell aufsuchen. Unter einem sequentiellen Suchschritt verstehen wir das Aufsuchen eines Elements aus S über die Verkettung und den Vergleich des gefundenen Elements mit dem gesuchten Wert. Bemerkung: z. B. erhalten wir zij = 0, wenn si = sj, und zij = 2, wenn si = sj+2 gilt.")
210
Definition 4:. Eine Menge S heißt äquidistant, wenn
Definition 4: Eine Menge S heißt äquidistant, wenn d = si+1 - si für i = 1, 2, ... n - 1. Bemerkung: z. B. ist die Menge S‘ = {0, 1, 2, ... n - 1} äquidistant mit d = 1. Jede äquidistante Menge S kann durch die lineare Transformation s - s1 s = ——— (s S) d In die Menge S‘ transformiert werden.
 d. In die Menge S‘ transformiert werden.")
211
Unbedingt erforderlich für den probabilistischen Algorithmus:
Angabe einer Distanzfunktion D auf S x S, die die Bestimmung des zu s nächsten Schlüssels in sequentiellen Suchschritten erlaubt: D (s, sj) = s - sj für sj < s; n ——— (sn - s1) - sj + s für s < sj n - 1 A) es gilt: B) A) gilt nicht s si = sj+1 - sj (1, J {1, 2, ... n - 1}) (zumindest für die erwarteten Differenzen) D (s, sj) = Anzahl von sequentiellen Aus D (s, si) < D (s, sj) folgt si ist si+1 - si Suchschritten um s von sj näher zu s als sj (und umgekehrt). aufzusuchen (= z (s, sj)) (gilt z. B. wenn S eine Zufallsstich- probe einer nach F (s) stetig verteilten Gesamtheit ist.
 = s - sj für sj < s; n. ——— (sn - s1) - sj + s für s < sj. n - 1. A) es gilt: B) A) gilt nicht. s si = sj+1 - sj. (1, J {1, 2, ... n - 1}) (zumindest für die erwarteten. Differenzen) D (s, sj) = Anzahl von sequentiellen Aus D (s, si) < D (s, sj) folgt si ist. si+1 - si Suchschritten um s von sj näher zu s als sj (und umgekehrt). aufzusuchen (= z (s, sj)) (gilt z. B. wenn S eine Zufallsstich- probe einer nach F (s) stetig verteilten. Gesamtheit ist.")
212
Beispiel: S = {1, 9, 27, 33, 101} = {s1, s2, s3, s4, s5}
D = —— (sn - s1) = 25 n - 1 Distanz dij = d (si, sj) D = Sequentielle zij = z (si, sj) Suchschritte Z =
 = 25. n - 1. Distanz dij = d (si, sj) D = Sequentielle zij = z (si, sj) Suchschritte Z =")
213
Der optimale Umfang von Zufallssuche
Beobachtbar durch Zufallssuche: Werte einer Distanzfunktion I Ertrag der Zufallssuche: Bestimmt durch den Wert der Zufallsvariablen Z (Anzahl von sequentiellen Suchschritten zum gesuchten Element). Die Werte von d lassen eine Einschätzung der zugeordneten Werte von z zu.
. Die Werte von d lassen eine Einschätzung der zugeordneten Werte von z zu.")
214
Möglichkeiten in der Genauigkeit der „Schätzung“:
A) Ist S äquidistant, so gilt: d (si, sj) ———– = z (si, sj) d B) Ist S äquidistant in der Erwartung, so gilt: E (d (si, sj)) ———— = z (si, sj) E (d) (E bezeichnet die Erwartung) C) Es gilt unabhängig von den Eigenschaften von S: d (si, sj) < d (si, sk) z (si, sj) < z (si, sk)
 Ist S äquidistant, so gilt: d (si, sj) ———– = z (si, sj) d. B) Ist S äquidistant in der Erwartung, so gilt: E (d (si, sj)) ———— = z (si, sj) E (d) (E bezeichnet die Erwartung) C) Es gilt unabhängig von den Eigenschaften von S: d (si, sj) < d (si, sk) z (si, sj) < z (si, sk)")
215
Zufallssuche: Kosten und Ertrag
Laufzeitbestimmungen der Berechnungsschritte : A) Zufallssuche: Zufallssuchschritt Phasen eines Schrittes: 1) Suche das durch die Zufallszahl bi rm bestimmte Element s S auf. 2) Berechne den Distanzwert δ (si, s); (si = gesuchtes Element). Zeitbedarf: cst
 Zufallssuche: Zufallssuchschritt. Phasen eines Schrittes: 1) Suche das durch die Zufallszahl bi rm bestimmte Element s S auf. 2) Berechne den Distanzwert δ (si, s); (si = gesuchtes Element). Zeitbedarf: cst.")
216
B) Sequentielle Suche: sequentieller Suchschritt
Phasen eines Schrittes: 1) Suche über einen Zeiger ein Element von S auf. 2) Vergleiche das gesuchte Element mit dem gefundenen Element. Zeitbedarf: cs Opportunitätskosten eines Zufallssuchschrittes: Reduktion der Distanz zum gesuchten Element - gemessen in sequentiellen Suchschritten - bei alternativem Einsatz der Zeit cst in sequentieller Suche: cst α = —— cs
 Suche über einen Zeiger ein Element von S auf. 2) Vergleiche das gesuchte Element mit dem gefundenen Element. Zeitbedarf: cs. Opportunitätskosten eines Zufallssuchschrittes: Reduktion der Distanz zum gesuchten Element - gemessen in sequentiellen Suchschritten - bei alternativem Einsatz der Zeit cst in sequentieller Suche: cst. α = —— cs.")
217
Grenzertrag des K-ten Zufallssuchschrittes:
Erwartete Reduktion der Anzahl der sequentiellen Suchschritte bei einer anschließenden sequentiellen Suche bei einem K-ten Zufallssuchschritt. Ziel der Zufallssuche (BALANCIERUNGSPRINZIP) Abbruch der Zufallssuche derart, dass der gesamte Zeitaufwand aus Zufallssuche und sequentieller Suche minimiert wird. Kriterium zur Minimierung des erwarteten Zeitaufwandes: Zufallssuche ist abzubrechen, wenn der Grenzertrag des K-ten Schrittes kleiner als α ist (bei konstantem cs und abnehmendem Grenzertrag der Zufallssuche).
 Abbruch der Zufallssuche derart, dass der gesamte Zeitaufwand aus Zufallssuche und sequentieller Suche minimiert wird. Kriterium zur Minimierung des erwarteten Zeitaufwandes: Zufallssuche ist abzubrechen, wenn der Grenzertrag des K-ten Schrittes kleiner als α ist (bei konstantem cs und abnehmendem Grenzertrag der Zufallssuche).")
218
Beispiele: Modell bei beobachtbarem Wert z (s, sj) gesucht s1 s2 s s[n - 2n] sn Stoppintervall: gilt z (sn, sg) < [2n] so stoppen: Effizienz (a = 1) ~ 2n F (z) = diskrete Gleichverteilung in {0, 1, .... n - 1}
![Beispiele: Modell bei beobachtbarem Wert z (s, sj) gesucht s1 s2 s s[n - 2n] sn.](http://slideplayer.org/slide/11848645/66/images/218/Beispiele%3A+Modell+bei+beobachtbarem+Wert+z+%28s%2C+sj%29+gesucht+s1+s2+s+s%5Bn+-+%EF%83%962n%5D+sn..jpg "Stoppintervall: gilt z (sn, sg) < [2n] so stoppen: Effizienz (a = 1) ~ 2n. F (z) = diskrete Gleichverteilung in {0, 1, .... n - 1}")
219
Modelle bei nicht beobachtbarem Wert z (s, sj)
1) Bekannt: F (z) ist (diskrete) Gleichverteilung Wie approximieren durch stetige Gleichverteilung in [0,1]. 1 Erwartungswert des Minimums: Ek (X1) = ——– K + 1 Opportunitätskosten (für a = 1) : — n Ek (X1) + k/n EFF. (a = 1) ~ 2n K = OPT ~ n Stichprobenumfang K
 Bekannt: F (z) ist (diskrete) Gleichverteilung. Wie approximieren durch stetige Gleichverteilung in [0,1]. 1. Erwartungswert des Minimums: Ek (X1) = ——– K + 1. Opportunitätskosten (für a = 1) : — n. Ek (X1) + k/n. EFF. (a = 1) ~ 2n. K = OPT ~ n Stichprobenumfang K.")
220
2) Kenntnis von F (z) wird nicht vorausgesetzt.
Beispiel: Rangauswahlmodelle Die Menge S sei nach den Werten z (s, si) aufsteigend geordnet; (s sei der gesuchte Schlüssel): (s =) si1, si2, si3, Sin „Wahrer“ Rang in einer Sortierordnung nach z (s, si) Differenz von si im wahren Rang zu si1 = z (s, si) Ist sk1, sk2, .... skm-1 die nach den Distanzen d (s, sk) sortierte Zufallsstichprobe von Werten aus S, so erlaubt der relative Rang des m-ten zufälligen Wertes sm aus S einen Wahrscheinlichkeitsschluss auf den wahren Rang von sm. Effizienz (a-1) : 2n < Anzahl der Suchschritte
 aufsteigend geordnet; (s sei der gesuchte Schlüssel): (s =) si1, si2, si3, Sin. „Wahrer Rang in einer Sortierordnung nach z (s, si) Differenz von si im wahren Rang zu si1 = z (s, si) Ist sk1, sk2, .... skm-1 die nach den Distanzen d (s, sk) sortierte Zufallsstichprobe von Werten aus S, so erlaubt der relative Rang des m-ten zufälligen Wertes sm aus S einen Wahrscheinlichkeitsschluss auf den wahren Rang von sm. Effizienz (a-1) : 2n < Anzahl der Suchschritte.")
221
Statistische Modelle zur Optimierung der Zufallssuche
A B Modelle, die eine Kenntnis von Kenntnis von z (si, sj) wird z (si, sj) für jedes Paar (si, sj) nicht vorausgesetzt annähernd unterstellen. II Mehrstufige Modelle, die von dem relativen Rang der Stichprobenelemente ausgehen: Vielzahl an Rangauswahlmodellen (z.B. ohne Stoppvektor-Beschränkungen: Effizienz > 2n für a=1; starke Zusatzbelastung) I Einstufige Modelle, die von den Erwartungswerten der Stichproben-minima ausgehen I Modelle ohne eine Be-schränkung der max. Anzahl von Zufallssuch-schritten II Modelle mit Beschränkung der Zufallssuchdauer (r U Ri ist vorgegeben) i = 1 Modelle mit gleichbleibender F (z) (Stichprobe mit Zurücklegen) (Effizienz (a=1):~2n) Adaptive Modelle (F(z) „adaptiert“) Bekannte Verteilung F (z) (Effizienz ~ 2n für a =1) Adaptive Modelle Mit Ohne Erinnerung Erinnerung Maximaler Stichprobenumfang ist endlich. Modelle, die erwartete Ränge minimieren (Stichprobe ohne Zurücklegen) (Effizienz (a=1):~2n)
 wird. z (si, sj) für jedes Paar (si, sj) nicht vorausgesetzt. annähernd unterstellen. II. Mehrstufige Modelle, die von dem relativen Rang der Stichprobenelemente ausgehen: Vielzahl an Rangauswahlmodellen (z.B. ohne Stoppvektor-Beschränkungen: Effizienz > 2n für a=1; starke Zusatzbelastung) I. Einstufige Modelle, die von den Erwartungswerten der Stichproben-minima ausgehen. I. Modelle ohne eine Be-schränkung der max. Anzahl von Zufallssuch-schritten. II. Modelle mit Beschränkung der Zufallssuchdauer. (r U Ri ist vorgegeben) i = 1. Modelle mit gleichbleibender F (z) (Stichprobe mit Zurücklegen) (Effizienz (a=1):~2n) Adaptive Modelle (F(z) „adaptiert ) Bekannte Verteilung F (z) (Effizienz ~ 2n für a =1) Adaptive. Modelle. Mit Ohne. Erinnerung Erinnerung. Maximaler Stichprobenumfang ist endlich. Modelle, die erwartete Ränge minimieren (Stichprobe ohne Zurücklegen) (Effizienz (a=1):~2n)")
222
Bemerkung: 1) In einzelnen Modellen meist Stichproben ohne Zurücklegen von Stichproben mit Zurücklegen zu unterscheiden. 2) Annähernde Verteilungen für F (z) und asymptotische Gesichtspunkte (z. B. Extremwertstatistik) bringen oft neue Varianten.
 Annähernde Verteilungen für F (z) und asymptotische Gesichtspunkte (z. B. Extremwertstatistik) bringen oft neue Varianten.")
223
Resultierender Vorschlag zur inhaltlich qualitativen Klassenbildung in den Problemstellungen
Probabilistischer Algorithmus 1) Einführung von Problemklassen P+, bei denen der Ertrag von Zufallssuche - gemessen in der hierdurch bestimmten Zeitkomplexität des deterministischen Algorithmusteiles - von einer beobachtbaren Zufallsgröße Z mit mehr oder weniger bekannter Verteilung, abhängt: A) Zeitinvariante Modelle: A 1) F (z) ist als Verteilung von Z unveränderlich oder die Zeit U nach Typ und Parametern bekannt. A 2) F (z) ist dem Typ nach bekannt. A priori Verteilung der Parameter ist bekannt (und natürlich konjugiert): Adaptive Modelle.
 Einführung von Problemklassen P+, bei denen der Ertrag von Zufallssuche - gemessen in der hierdurch bestimmten Zeitkomplexität des deterministischen Algorithmusteiles - von einer beobachtbaren Zufallsgröße Z mit mehr oder weniger bekannter Verteilung, abhängt: A) Zeitinvariante Modelle: A 1) F (z) ist als Verteilung von Z unveränderlich oder die Zeit U nach Typ und Parametern bekannt. A 2) F (z) ist dem Typ nach bekannt. A priori Verteilung der Parameter ist bekannt (und natürlich konjugiert): Adaptive Modelle.")
224
B) Zeitabhängige Modelle:
Wie A 2), jedoch ist F (z) auch veränderlich durch Veränderungen der a priori Verteilung der Parameter von F (z) nach der Zeit: zeitadaptive Modelle. 2) Problemklassen P++, bei denen eine konkrete Verteilung F (z) bzw. ihre Kenntnis nicht vorausgesetzt wird (Rang-Auswahl- Modelle und verwandet Modelle) 3) Problemklassen P+++, bei denen F (z) zeitinvariant zeitabhängig ist, aber Z nicht beobachtet werden muss.
, jedoch ist F (z) auch veränderlich durch Veränderungen der a priori Verteilung der Parameter von F (z) nach der Zeit: zeitadaptive Modelle. 2) Problemklassen P++, bei denen eine konkrete Verteilung F (z) bzw. ihre Kenntnis nicht vorausgesetzt wird (Rang-Auswahl- Modelle und verwandet Modelle) 3) Problemklassen P+++, bei denen F (z) zeitinvariant. zeitabhängig. ist, aber Z nicht beobachtet werden muss.")
225
Problemstellungsklassen
P P P+++ Modelle legen die Vor-stellung einer Zufalls-stichprobe von Daten aus einer (un-)genau bekannten Datenver-teilung zugrunde Modelle kommen ohne Datenverteilung aus; basieren auf Rängen, Permutationsanalysen u. a. Auch eine Verteilung des Ertrages der Zufallssuche wird nicht vorausgesetzt. (Kosten der Ziehung mit Rängen verrechenbar!) Modelle kommen ohne Datenverteilung aus; Kenntnis von einer Ertragsverteilung F (z) der Zufallssuche wird vorausgesetzt.
genau bekannten Datenver-teilung zugrunde. Modelle kommen ohne Datenverteilung aus; basieren auf Rängen, Permutationsanalysen u. a. Auch eine Verteilung des Ertrages der Zufallssuche wird nicht vorausgesetzt. (Kosten der Ziehung mit Rängen verrechenbar!) Modelle kommen ohne Datenverteilung aus; Kenntnis von einer Ertragsverteilung F (z) der Zufallssuche wird vorausgesetzt.")
226
Applikation dieser Einteilung auf Nearest-Pair-Algorithmus:
Zu optimierende Größe: Anfängliche Stichprobenumfänge: Anzahl der Stichproben u. a. P Koordinatenverteilung bekannt und Koordinatenverteilung soll ändert sich nicht zu „schnell“ nicht als bekannt vorausgesetzt werden P+, P P++ Verteilung der Distanzen Distanzenverteilung nicht bekannt bzw. zu adaptieren: bekannt: Verteilungsabhängige Betrachtungen Verteilungsunabhängige A) Verteilungen zeitinvariant Betrachtungen B) Verteilung zeitabhängig und langsame Änderungen (Adaptive Modelle)
 Verteilungen zeitinvariant Betrachtungen. B) Verteilung zeitabhängig und. langsame Änderungen. (Adaptive Modelle)")
227
Abschließende Feststellungen zu probabilistischen Algorithmen, die mit Sicherheit lösen:
1) Probabilistische Algorithmen eliminieren zu (geringen) Kosten das Risiko, welches in der Problemstellungsabhängigkeit der Zeitkomplexität einzelner Algorithmen liegt. 2) Zeitkomplexität probabilistischer Algorithmen kann durch den Einsatz von Methoden der Wahrscheinlichkeitstheorie und Statistik (insbesondere der Stopptheorie, von Rangauswahlmodellen und verwandten Modellen und von anderen Modellen der statistischen Theorie) minimiert werden. 3) a) Die Einführung von Minimierungsbetrachtungen führt zur tieferen Unterteilung in Problemstellungsklassen und damit zu einer besseren Ausnutzung der Problemkenntnis durch den Algorithmus. b) Betrachtungen nach Punkt 3a) legen nahe, zeitabhängige Klassen von Problemstellungen einzuführen. Algorithmusrelevante Informationen über die Klassen werden mittels Information aus den wiederholten Problemlösungen fortgeschrieben.
 Probabilistische Algorithmen eliminieren zu (geringen) Kosten das Risiko, welches in der Problemstellungsabhängigkeit der Zeitkomplexität einzelner Algorithmen liegt. 2) Zeitkomplexität probabilistischer Algorithmen kann durch den Einsatz von Methoden der Wahrscheinlichkeitstheorie und Statistik (insbesondere der Stopptheorie, von Rangauswahlmodellen und verwandten Modellen und von anderen Modellen der statistischen Theorie) minimiert werden. 3) a) Die Einführung von Minimierungsbetrachtungen führt zur tieferen Unterteilung in Problemstellungsklassen und damit zu einer besseren Ausnutzung der Problemkenntnis durch den Algorithmus. b) Betrachtungen nach Punkt 3a) legen nahe, zeitabhängige Klassen von Problemstellungen einzuführen. Algorithmusrelevante Informationen über die Klassen werden mittels Information aus den wiederholten Problemlösungen fortgeschrieben.")
228
Ganz analog: Quicksort
Prinzip: Stelle eine Menge S von n Elementen derart um, dass alle Elemente sj > si (sj S - {si}) rechts von si und alle Elemente sj < si links von si stehen. si wird zufällig gewählt. z. B. s1 < s2 < s3 < s4 < s5 Ursprüngliche Anordnung: s3 s4 s5 s1 s2 zufällig gezogenes si: s3 Resultat der Umstellung: s2 s1 s3 s5 s4 werden jeweils wieder geteilt mit einem zufälligen Element. Probabilistische Frage: Optimaler Stichprobenumfang, um das optimale Element zur Teilung (Median) zu schätzen. Frazen W. D. and Mc. Kellar, H. C.: Samplesort: A Sampling Approach to Minimal Storage Tree Sorting, Journal Of The ACM, Vol. 17, No. 3 (1970), pp
 rechts von si und alle Elemente sj < si links von si stehen. si wird zufällig gewählt. z. B. s1 < s2 < s3 < s4 < s5. Ursprüngliche Anordnung: s3 s4 s5 s1 s2. zufällig gezogenes si: s3. Resultat der Umstellung: s2 s1 s3 s5 s4. werden jeweils wieder geteilt mit einem zufälligen Element. Probabilistische Frage: Optimaler Stichprobenumfang, um das optimale Element zur Teilung (Median) zu schätzen. Frazen W. D. and Mc. Kellar, H. C.: Samplesort: A Sampling Approach to Minimal Storage Tree Sorting, Journal Of The ACM, Vol. 17, No. 3 (1970), pp")
229
Literatur: 0) Gill, J. T., Probabilistic Turing Machines And Complexity Of Computation, Tagungsbericht 43/1974, Algorithmen und Komplexitätstheorie, Oberwolfach. 1) Janko, W., Stochastische Modelle in Such- und Sortierprozessen, Duncker & Humblot, Berlin 1976. 2) Janko, W., An Insertion Sort For Uniformly Distributed Keys Based On Stopping Theory, Proc. Of The International Computing Symposium, (Liege), pp 3) Miller, G. L., Riemann‘s Hypotheses And Tests For Primality, Proc. Of The Seventh Annual ACM Symposium On Theory Of Computing (1975), pp
 Janko, W., Stochastische Modelle in Such- und Sortierprozessen, Duncker & Humblot, Berlin ) Janko, W., An Insertion Sort For Uniformly Distributed Keys Based On Stopping Theory, Proc. Of The International Computing Symposium, 1977 (Liege), pp ) Miller, G. L., Riemann‘s Hypotheses And Tests For Primality, Proc. Of The Seventh Annual ACM Symposium On Theory Of Computing (1975), pp")
230
4) Rabin, M. O., Probabilistic Algorithms, in: Algorithms And Complexity: New Directions And Recent Results, Ed. J. F. Traub, Academic Press, New York 1976. 5) Rabin, M. O., Theoretical Impediments To Artifical Intelligence, IFIP 1974, pp 6) Rackhoff, C., Relativized Questions Involving Probabilistic Algorithms, Proc. Of The 10th Annual ACM Symposium On Theory Of Computing, 1978. 7) Janko W., Combinatorial Consideration On The Optimality Of Heuristic Solutions Of Problems, in: Datenstrukturen, Graphen, Algorithmen. Berichte zur praktischen Informatik 8, Verl. Hanser
 Rabin, M. O., Theoretical Impediments To Artifical Intelligence, IFIP 1974, pp ) Rackhoff, C., Relativized Questions Involving Probabilistic Algorithms, Proc. Of The 10th Annual ACM Symposium On Theory Of Computing, ) Janko W., Combinatorial Consideration On The Optimality Of Heuristic Solutions Of Problems, in: Datenstrukturen, Graphen, Algorithmen. Berichte zur praktischen Informatik 8, Verl. Hanser.")
231
- Rabin, M. O., Probabilistic Algorithms;
Literatur (Auswahl) Complexity Of Sequential And Parallel Numerical Algorithms, Ed. J. F. Traub, Academic Press, New York, 1973. The Complexity Of Computer Computations, Ed. R. E. Miller, J. W. Thatcher, Plenum Press, New York, 1972 (Enthält u.a.: Karp, M., Reducibility Among Combinatorial Problems.) Algorithms And Complexity: New Directions And Recent Results, Ed. J. F. Traub, Academic Press, New York, 1976 (Enthält u.a.: - Karp, R., The Probabilistic Analysis Of Some Combinatorial Search Algorithms; *) - Rabin, M. O., Probabilistic Algorithms; - Shamos, M. I., Geometry And Statistics: Problems At The Interface; - Simon, H. A. and Kadane, J. B., Problems Of Computational Complexity In Artifical Intelligence). *) Bearwood, J., Halton, J. H. and Hammersley, J. M., The Shortest Path Through Many Points, Proc. Comb. Phil. Soc. 55 (1959), pp
 Complexity Of Sequential And Parallel Numerical Algorithms, Ed. J. F. Traub, Academic Press, New York, The Complexity Of Computer Computations, Ed. R. E. Miller, J. W. Thatcher, Plenum Press, New York, 1972 (Enthält u.a.: Karp, M., Reducibility Among Combinatorial Problems.) Algorithms And Complexity: New Directions And Recent Results, Ed. J. F. Traub, Academic Press, New York, 1976 (Enthält u.a.: - Karp, R., The Probabilistic Analysis Of Some Combinatorial Search Algorithms; *) - Rabin, M. O., Probabilistic Algorithms; - Shamos, M. I., Geometry And Statistics: Problems At The Interface; - Simon, H. A. and Kadane, J. B., Problems Of Computational Complexity In Artifical Intelligence). *) Bearwood, J., Halton, J. H. and Hammersley, J. M., The Shortest Path Through Many Points, Proc. Comb. Phil. Soc. 55 (1959), pp")
232
Borodin, A. and Munro, B. , The Computational Complexity Of Algebraic
Borodin, A. and Munro, B., The Computational Complexity Of Algebraic And Numeric Problems, Elsevier Pub. Comp., New York, 1975. Aho, A. V., Hopcroft, J. E. and Ullmann, J. D., The Design And Analysis Of Computer Algorithms, Addison-Wesley, 1974. Approximative Algorithmen (u. a.): Sahni, S., General Techniques For Combinatorial Approximation, Op. Res., Vol. 25, No. 6 (1977). Karp, R. M., Probabilistic Analysis Of Partioning Algorithms For The Travelling-Salesman-Problem In The Plane, Mathematics Of Operations Research, Vol. 2, No. 3, P. 209 ff. (1977).
: Sahni, S., General Techniques For Combinatorial Approximation, Op. Res., Vol. 25, No. 6 (1977). Karp, R. M., Probabilistic Analysis Of Partioning Algorithms For The Travelling-Salesman-Problem In The Plane, Mathematics Of Operations Research, Vol. 2, No. 3, P. 209 ff. (1977).")
233
Die Algorithmenwahl als Entscheidungsproblem Bemerkung:
Es gibt Entscheidungsprobleme unter Sicherheit, für deren näherungsweiser und exakter Lösung eine Vielzahl von Lösungsalgorithmen zur Verfügung stehen. . . αk . . αj α1 α2 I I a1 a2 am u (a ) - c u(a ) - c u (a ) - c . . . . u (a ) - c u (a ) - c m m m m2 Approximative Algorithmen Optimierende Algorithmen
 - c u(a ) - c u (a ) - c u (a ) - c u (a ) - c m m1 m m2. Approximative Algorithmen. Optimierende Algorithmen.")
234
A = {α1, α2, ...., αk} ist die Menge der möglichen Algorithmen
Beispiel: A = {a1, a2, ... , an} sei die Menge der möglichen Touren in einem T-S-Problem (es gelte u (am) > u (am - 1) > ... > u (a1)) {I1, I2, } ist die Menge der möglichen T-S-Problemstellungen A = {α1, α2, ...., αk} ist die Menge der möglichen Algorithmen cij: „Durchführungskosten“ des jeweiligen Algorithmus bei Datensituation Ij und Aktion ai
 > u (am - 1) > ... > u (a1)) {I1, I2, } ist die Menge der möglichen T-S-Problemstellungen. A = {α1, α2, ...., αk} ist die Menge der möglichen Algorithmen. cij: „Durchführungskosten des jeweiligen Algorithmus bei Datensituation Ij und Aktion ai.")
235
Von den Aktionen wird meist implizit die „beste“ als gewählt unterstellt!
Derzeit zwei Varianten der Algorithmenauswahl üblich: 1) p1, p2, seien die Wahrscheinlichkeiten der Datenausgangssituationen. Σ Man bilde Ei (c) = { } pj cij J Auswahlregel: Man wähle jenen optimierenden Algorithmus a, für D u (am) Em (c) maximal ist, d. h. Em (c) ist minimal Häufige - eher unbegründete - Annahme hierbei: pi = — (i = 1, 2, ...., n) (bzw. f(x) = —– für x [a, b]). n b-a
 p1, p2, seien die Wahrscheinlichkeiten der Datenausgangssituationen. Σ. Man bilde Ei (c) = { } pj cij. J. Auswahlregel: Man wähle jenen optimierenden Algorithmus a, für D u (am) - Em (c) maximal ist, d. h. Em (c) ist minimal. Häufige - eher unbegründete - Annahme hierbei: 1 1. pi = — (i = 1, 2, ...., n) (bzw. f(x) = —– für x [a, b]). n b-a.")
236
2) Man wähle jenen optimierenden Algorithmus α für den gilt:
max {min {u (am) - cmj}}; j {1, 2, ... } bzw. min {max{cmj}} i j D. h. man wähle jenen optimierenden Algorithmus α, dessen ungünstigstes Verhalten noch am besten ist. Vorgangsweise 1) und 2) sind nicht günstig, da hiermit nicht die Gesamtsituation berücksichtigt wird. Vielmehr müssten die Datensituationen (und die Ergebnissituationen) mit berücksichtigt werden, um folgendes Tableau zu erstellen:
 - cmj}}; j {1, 2, ... } bzw. min {max{cmj}} i j. D. h. man wähle jenen optimierenden Algorithmus α, dessen ungünstigstes Verhalten noch am besten ist. Vorgangsweise 1) und 2) sind nicht günstig, da hiermit nicht die Gesamtsituation berücksichtigt wird. Vielmehr müssten die Datensituationen (und die Ergebnissituationen) mit berücksichtigt werden, um folgendes Tableau zu erstellen:")
237
Datensituationen Aktionen x Algorithmen I1 I a1 a1 u (a ) - c u (a ) - c a2 a1 u (a ) - c u (a ) - c am a a1 a am a am ak
 - c u (a ) - c am a1 . . a1 a2 . . am a2 . . am ak . .")
238
(Eine besondere Problemstellung resultiert aus probabilistischen Algorithmen, die optimale Lösungen nicht unbedingt finden.) Die Algorithmenwahl bei Entscheidungen unter Sicherheit ist selbst u.U. ein Entscheidungsproblem unter Unsicherheit bzw. Ungewissheit.

239
Gremiale Entscheidungen unter Sicherheit
Problemstellung: Können - und wenn ja, wie können - N Präferenz- ordnungen der Mitglieder eines Gremiums zu einer einzigen Präferenzordnung aggregiert werden? Entscheidungsraum: N Mitglieder Aktionenraum: A = {a, b, c, ...} bestehe aus m Alternativen Präferenzordnungen auf den Alternativen: ~, ~ , ...., ~ N Problem: Entwicklung einer gremialen Präferenzordnung, ~ die plausible Kriterien erfüllt. Sei R die Menge aller möglichen Präferenzordnungen. Das Problem besteht dann im Auffinden einer Abbildung F : Rn R

240
Bemerkung:. die Anzahl der Aggregationsmechanismen F wächst sehr
Bemerkung: die Anzahl der Aggregationsmechanismen F wächst sehr rasch mit |A|: Beispiel: 1) |A| = 2; R = {a ~ b, b ~ a, b ~ a} 2) |A| = 3; R = {a ~ b ~ c; b ~ c ~ a; c ~ a ~ b; a ~ c ~ b; b ~ a ~ c; c ~ b ~ a; a ~ b ~ c; b ~ a ~ c; c ~ a ~ b; b ~ c ~ a; a ~ c ~ b; a ~ b ~ c; a ~ b ~ c} |R| = 3! + ( ) 2! + ( ) = 13; |F| = |R| |R|3 = Kardinalzahl der Menge der möglichen Abbildungen
 |A| = 2; R = {a ~ b, b ~ a, b ~ a} 2) |A| = 3; R = {a ~ b ~ c; b ~ c ~ a; c ~ a ~ b; a ~ c ~ b; b ~ a ~ c; c ~ b ~ a; a ~ b ~ c; b ~ a ~ c; c ~ a ~ b; b ~ c ~ a; a ~ c ~ b; a ~ b ~ c; a ~ b ~ c} 3 3. |R| = 3! + ( ) 2! + ( ) = 13; |F| = |R| |R|3 = Kardinalzahl der Menge der möglichen Abbildungen. ")
241
Wählerparadoxon bei Mehrheitsentscheidung
3 Alternativen (A = {a, b, c}) und 3 Gremienmitglieder Abstimmungsreihenfolge: 1) a VOR b 1,3 = Mehrheit 2) b VOR c 1,2 = Mehrheit 3) c VOR a 2,3 = Mehrheit Also: resultierende Prioritätsordnung muss nicht transitiv sein.
 und 3 Gremienmitglieder. Abstimmungsreihenfolge: 1) a VOR b 1,3 = Mehrheit. 2) b VOR c 1,2 = Mehrheit. 3) c VOR a 2,3 = Mehrheit. Also: resultierende Prioritätsordnung muss nicht transitiv sein.")
242
Anerkannte Forderungen an einen rationalen Aggregationsmechanismus F:
Forderung 1: Universeller Definitionsbereich Definitionsbereich des Aggregationsmechanismus F ist die Menge RN aller Präferenzordnungsprofile. Forderung 2: Einstimmigkeitsbedingung Es gelte a, b, A und a b (i = 1, 2, .... , N); i Es soll dann auch für F mit der Relation gelten: a b
; i. Es soll dann auch für F mit der Relation gelten: a b.")
243
Beispiel: ~ : a b c; 1 ~ : a c b; also gilt: a b (i = 1, 2, 3); i a c (i = 1, 2, 3); ~ : a b c i 3 Also soll für F gelten: a b und a c.
; ~ : a b c i. 3. Also soll für F gelten: a b. und a c.")
244
Forderung 3: Unabhängigkeit von irrelevanten Alternativen
‘ ‘ ‘ Es seien (~, ~, ..., ~) und ( ~, ~, ..., ~) zwei Präferenzordnungstupel; N N ‘ die beiden kollektiven Präferenzordnungen ~ und ~ müssen genau dann auf {a, b} übereinstimmen, wenn die beiden Präferenz- ordungstupel auf {a, b} übereinstimmen. Forderung 4: Diktaturverbot Es gibt kein Gremienmitglied i, so dass genau dann, wenn a b i gilt, auch a b gelten muss (=Diktator). Ein Entscheidungsspielraum bliebe bei Existenz eines Diktators nur bei Indifferenz.
 und ( ~, ~, ..., ~) zwei Präferenzordnungstupel; 1 2 N 1 2 N. ‘ die beiden kollektiven Präferenzordnungen ~ und ~ müssen genau. dann auf {a, b} übereinstimmen, wenn die beiden Präferenz- ordungstupel auf {a, b} übereinstimmen. Forderung 4: Diktaturverbot. Es gibt kein Gremienmitglied i, so dass genau dann, wenn a b. i. gilt, auch a b gelten muss (=Diktator). Ein Entscheidungsspielraum bliebe bei Existenz eines Diktators nur bei Indifferenz.")
245
Satz (Unmöglichkeitstheorem von Arrow)
Gilt N > 2 und m > 3, so sind die Forderungen 1 bis 4 miteinander unvereinbar; (d. h. es gibt für N > 2 und m > 3 keinen Aggregations- mechanismus, der alle 4 Forderungen erfüllt!) Bemerkung: für m = 2 erfüllt die Mehrheitsentscheidung alle Forderungen. (Beweis: Blau 1957)
 Bemerkung: für m = 2 erfüllt die Mehrheitsentscheidung alle Forderungen. (Beweis: Blau 1957)")
246
Möglichkeiten des Verzichts auf Forderungen
1) Verzichtsmöglichkeiten bei Forderung 1 (Universeller Definitionsbereich) a) Black D.: Einschränkung des universellen Definitionsbereichs durch Eingipfelbedingung Fordert, dass nur solche Präferenzordnungen betrachtet werden dürfen, welche die Eingipfelbedingung erfüllen. Eingipfelbedingung: Alternativenmenge {a, b, ...} Präferenzordnungen {|i = 1, 2, ...N} 1 Ist erfüllt, wenn Alternativen so angeordnet werden können, dass für jedes Gremienmitglied die Präferenzordnung eine eingipfelige Kurve darstellt.
 Verzichtsmöglichkeiten bei Forderung 1 (Universeller Definitionsbereich) a) Black D.: Einschränkung des universellen Definitionsbereichs durch Eingipfelbedingung. Fordert, dass nur solche Präferenzordnungen betrachtet werden dürfen, welche die Eingipfelbedingung erfüllen. Eingipfelbedingung: Alternativenmenge {a, b, ...} Präferenzordnungen {|i = 1, 2, ...N} 1. Ist erfüllt, wenn Alternativen so angeordnet werden können, dass für jedes Gremienmitglied die Präferenzordnung eine eingipfelige Kurve darstellt.")
247
Beispiel (Wählerparadoxon):
a b c b c a ~ ~ ~ 1 2 3 a b c b c a c a b Man kann beweisen (Black (1948) Arrow (1951)), dass bei ungerader Anzahl von Gremienmitgliedern bei Beschränkung des Aggregationsmechanismus auf jene Präferenzordnung, die der Eingipfelbedingung genügen, Forderung 2, 3, 4 miteinander verträglich sind. Die Mehrheitsentscheidung ist der entsprechende Aggregationsmechanismus!
 Arrow (1951)), dass bei ungerader Anzahl von Gremienmitgliedern bei Beschränkung des Aggregationsmechanismus auf jene Präferenzordnung, die der Eingipfelbedingung genügen, Forderung 2, 3, 4 miteinander verträglich sind. Die Mehrheitsentscheidung ist der entsprechende Aggregationsmechanismus!")
248
N ungerade erforderlich!
Beispiel ungeraden N: ~ ~ 1 2 a b b c c a Mehrheitsentscheidung jedoch: c ~ a (1 : 1) a ~ b (1 : 1) b c (statt c ~ b wegen Transitivität!)
 a ~ b (1 : 1) b c (statt c ~ b wegen Transitivität!)")
249
Dynamische Entscheidungsmodelle unter Sicherheit
Beispiel eines dynamischen Entscheidungsproblems: xi = Lagerbestand am Ende der Periode i wi = Bedarf der Periode i Bi = Bestellung zu Beginn der i-ten Periode x3 = 0 b3 w3 x2 w2 b2 x1 b1 w1 Planungshorizont

250
Problem:. Bestimme eine Bestellpolitik (a1. , a2. ,. an. ), die die
Problem: Bestimme eine Bestellpolitik (a1*, a2*, ... an*), die die Lagerkosten bzw. damit zusammenhängende Kosten minimiert. Bemerkung: Ist eine dieser Größen eine Zufallsvariable, so ist das Modell stochastisch. Ist der Planungshorizont endlich und die Anzahl der Perioden endlich, so handelt es sich um eine endliche Problemstellung. Satz: Jede endliche Problemstellung mit endlich vielen möglichen Bestellmengen, Lagermengen kann in eine statische Problemstellung überführt und als solche gelöst werden.
, die die Lagerkosten bzw. damit zusammenhängende Kosten minimiert. Bemerkung: Ist eine dieser Größen eine Zufallsvariable, so ist das Modell stochastisch. Ist der Planungshorizont endlich und die Anzahl der Perioden endlich, so handelt es sich um eine endliche Problemstellung. Satz: Jede endliche Problemstellung mit endlich vielen möglichen Bestellmengen, Lagermengen kann in eine statische Problemstellung überführt und als solche gelöst werden.")
251
Beispiel (Notation): xn = Anfangsbestand der n + 1-ten Periode bn = bestellte Menge (zu Anfang der n-ten Periode) < 2 wn = Nachfrage der n-ten Periode: w0 = 1; w1 = 3; w2 = 2 h = Lagerkosten pro Stück: 1,-- € c = Bestellkosten pro Stück: 1,-- € p = Kosten unbefriedigten Bedarfs: 3,-- € kn = kn xn-1 h + (wn - bn - xn-1) p + bnc
 p + bnc.")
252
Wir bauen einen Entscheidungsbaum auf und können hieraus leicht die optimale Politik ersehen:
3. Periode: w2 = 2 x2 = 0 1. Periode: w0 = 1 2. Periode: w1 = 3 8-Kosten

253
Wir können uns leicht durch Durchrechnung aller 27 Fälle die optimale Bestellpolitik (b0*, b1*, b2*) ermitteln, das Problem ist typisch für eine Reihe systemtheoretischer Problemstellungen der folgenden Art: Externe „Störung“ (deterministisch oder stochastisch) Input Output S = Steuerbereich π Feedback-Kontrolle
 Input Output. S = Steuerbereich. π. Feedback-Kontrolle.")
254
Lagerhaltung: Input = (b0, b1, b2)
Output = (x0, x1, x2, x3) Externe Störung = (w0, w1, w2) S (Steuerbereich) = Lagerbeschränkungen Da das System in diskreter Zeit arbeitet, kann man sich den Entscheidungsprozess als wiederholte Einzelentscheidungen μk vorstellen, die in ihrer Gesamtheit die Steuerungsfunktion π ausmachen: xk+1 = f (xk, wk, bk)(Systemgleichung) wk bk Lager: S xk Bestellung μk (xk) = bk
 Externe Störung = (w0, w1, w2) S (Steuerbereich) = Lagerbeschränkungen. Da das System in diskreter Zeit arbeitet, kann man sich den Entscheidungsprozess als wiederholte Einzelentscheidungen μk vorstellen, die in ihrer Gesamtheit die Steuerungsfunktion π ausmachen: xk+1 = f (xk, wk, bk)(Systemgleichung) wk. bk Lager: S xk. Bestellung. μk (xk) = bk.")
255
π = (μ0, μ1,..., μn-1) = Menge von Funktionsfolgen!
Optimale Steuerung: Jenes Funktionstupel = (μ0*, μ1*, ..., μn-1*) Welches die Kostenfunktion: n-1 K (x, w, b) = Kn (xn) + Kk (xk, bk, wk) (n sei letzte Periode) k=0 minimiert. Bemerkung: wir können auch andere als lineare Varianten wählen! Derartige Probleme sind mitunter relativ einfach mittels der Funktional-gleichung der dynamischen Programmierung zu lösen.
 Welches die Kostenfunktion: n-1. K (x, w, b) = Kn (xn) + Kk (xk, bk, wk) (n sei letzte Periode) k=0. minimiert. Bemerkung: wir können auch andere als lineare Varianten wählen! Derartige Probleme sind mitunter relativ einfach mittels der Funktional-gleichung der dynamischen Programmierung zu lösen.")
256
Der Algorithmus Es sei K* (x0) der optimale Wert der Politik; es gilt dann K* (x0) = K0 (x0), wobei K0 (x0) durch folgende Funktionalgleichung bestimmt ist (von n-1 nach 0 gehend!): Kn (xn) = gn (xn) Kk (xk) = inf {gk (xk, bk, wk) + Kk+1 (gk(xk, bk, wk)} bk Bk (xk) k = 0, 1, ..., n-1 Jenes μk* = μk* (xk), welches die rechte Seite von obiger Funktionalgleichung für jedes xk und k minimiert, bildet als Tupel das optimale Kontrollgesetz: π = (μ0*, μ1*, ... μ*n-1)
 durch folgende Funktionalgleichung bestimmt ist (von n-1 nach 0 gehend!): Kn (xn) = gn (xn) Kk (xk) = inf {gk (xk, bk, wk) + Kk+1 (gk(xk, bk, wk)} bk Bk (xk) k = 0, 1, ..., n-1. Jenes μk* = μk* (xk), welches die rechte Seite von obiger Funktionalgleichung für jedes xk und k minimiert, bildet als Tupel das optimale Kontrollgesetz: π = (μ0*, μ1*, ... μ*n-1)")
257
Wir lösen nun obiges Beispiel:
es gilt: K3(x3) = 0; (Endbestand soll 0 sein). Kk(xk) = min {bk + max (0, xk + bk - wk) + 3 max (0, wk - xk - bk) + 0 < bk < 2 - xk + Kk+1 (max (0, xk + bk - wk))} für K = 0, 1, 2, und xk, bk {0, 1, 2, } Lösung: Periode 3: Wir berechnen K3 (x3) für jeden der 3 möglichen Anfangsbestände: x2 = 0 K2 (0) = min {b2 + max (0, b2 - 2) + 3 max (0, 2 - b2)} = b2 = 0, 1, 2 b2 = 0 K2 (0) = 6 b2 = 1 K2 (0) = 4 b2 = 2 K2 (0) = 2
 = 0; (Endbestand soll 0 sein). Kk(xk) = min {bk + max (0, xk + bk - wk) + 3 max (0, wk - xk - bk) + 0 < bk < 2 - xk. + Kk+1 (max (0, xk + bk - wk))} für K = 0, 1, 2, und xk, bk {0, 1, 2, } Lösung: Periode 3: Wir berechnen K3 (x3) für jeden der 3 möglichen Anfangsbestände: x2 = 0. K2 (0) = min {b2 + max (0, b2 - 2) + 3 max (0, 2 - b2)} = b2 = 0, 1, 2. b2 = 0 K2 (0) = 6. b2 = 1 K2 (0) = 4. b2 = 2 K2 (0) = 2.")
258
x2 = 1 K2 (1) = min {b2 + max (0, 1 + b2 - 2) + 3 max (0, b2)} b2 = 0, 1 b2 = 0 3 b2 = 1 1 x2 = 2 K2 (2) = min {0 + max (0, 2 - 2) + 3 max (0, )} = b2 = 0 b2 = 1 0 Periode 2 wir berechnen wieder K1 (x1) für jede der 3 verschiedenen Stadien x2 = 0, 1, 2, indem wir K2 (0), K2 (1) und K2 (2) aus der vorhergehenden Analyse verwenden! x1 = 0 K1(0) = min {b1 + max (0, b1-3) + 3 max (0, 3-b1) + K2 (max (0, b1-3))} b1 = 0, 1, 2 b1 = 0 = 11 b1 = 1 = 9 b1 = 2 = 7
 = min {0 + max (0, 2 - 2) + 3 max (0, )} = b2 = 0. b2 = 1 0. Periode 2. wir berechnen wieder K1 (x1) für jede der 3 verschiedenen Stadien x2 = 0, 1, 2, indem wir K2 (0), K2 (1) und K2 (2) aus der vorhergehenden Analyse verwenden! x1 = 0. K1(0) = min {b1 + max (0, b1-3) + 3 max (0, 3-b1) + K2 (max (0, b1-3))} b1 = 0, 1, 2. b1 = 0 = 11. b1 = 1 = 9. b1 = 2 = 7.")
259
x2 = 1 K1(1) = min {b1+max (0,1+b1-3) + 3 max (0,3-1-b1)+K2 (max (0,1,+b1-3)} b1 = 0, 1 b1 = 0 8 b1 = 1 6 x2 = 2 K1 (2) = min {max (0, 2 - 3) + 3 max (0, 3 - 2) + K2 (0)} = 3 + 2 b1 = 0 b1 = 0 5 Periode 1: es gilt bekanntlich x0 = 0; w0 = 1 x0 = 0 K0 (0) = min {b0 + max (0, b0 - 1) + 3 max (0, 1, - b0) + K1 (max (0,b0-1))} b0 = 0, 1, 2, b0 = 0 = 10 b0 = 1 = 8 b0 = 2 = 9
 = min {max (0, 2 - 3) + 3 max (0, 3 - 2) + K2 (0)} = b1 = 0. b1 = 0 5. Periode 1: es gilt bekanntlich x0 = 0; w0 = 1. x0 = 0. K0 (0) = min {b0 + max (0, b0 - 1) + 3 max (0, 1, - b0) + K1 (max (0,b0-1))} b0 = 0, 1, 2, b0 = 0 = 10. b0 = 1 = 8. b0 = 2 = 9.")
260
Optimales Kontrollgesetz:
π = (b0 = 1, b1 = 2, b3 = 2) Gesamtlagerkosten = 8 Nachweis durch Vorwärtsrechung: 1. Periode: x0 = 0 b0 = 1 w1 = 1 1 2. Periode: x1 = b1 = 2 w2 = gesamt 3. Periode: x2 = 0 b2 = 2 w2 = 2 2
 Gesamtlagerkosten = 8. Nachweis durch Vorwärtsrechung: 1. Periode: x0 = 0. b0 = 1 w1 = Periode: x1 = 0 2. b1 = 2 w2 = gesamt. 3. Periode: x2 = 0. b2 = 2 w2 = 2 2.")
261
Bemerkung: 1) A) Es wäre keinerlei Schwierigkeit, die Problemstellung für ein Maximierungsproblem mit einer allgemeinen Kostenfunktion abzuändern, z. B.: n-1 K (x0) = β exp (α (gn (xn) + gk (xk, uk wk))) k=0 Je nach Wert der Konstanten β, α ist diese Kostenfunktion (Nutzenfunktion) durch Risikofreude β > 0; α > 0 oder Risikoaversion β < 0; α > 0 bestimmt. B) Auch mehrfache Zielsetzung kann eingeführt werden.
 A) Es wäre keinerlei Schwierigkeit, die Problemstellung für ein Maximierungsproblem mit einer allgemeinen Kostenfunktion abzuändern, z. B.: n-1. K (x0) = β exp (α (gn (xn) + gk (xk, uk wk))) k=0. Je nach Wert der Konstanten β, α ist diese Kostenfunktion (Nutzenfunktion) durch. Risikofreude β > 0; α > 0. oder Risikoaversion β < 0; α > 0. bestimmt. B) Auch mehrfache Zielsetzung kann eingeführt werden.")
262
2) Der Zeithorizont muss nicht endlich sein und die Zeit nicht diskret.
α) Zeithorizont unendlich In solchen Fällen wird dann meist ein anderes Zielkriterium zu verwenden sein. Sehr häufig verwendete Varianten: A) Maximierung der diskontierten Summe der Stufenauszahlungen: Kt λt-1 t=1 B) Maximierung der langfristigen Durchschnittsauszahlung: T min μt T T t=1 β) Zeit stetig
 Zeithorizont unendlich. In solchen Fällen wird dann meist ein anderes Zielkriterium zu verwenden sein. Sehr häufig verwendete Varianten: A) Maximierung der diskontierten Summe der Stufenauszahlungen: Kt λt-1. t=1. B) Maximierung der langfristigen Durchschnittsauszahlung: T. min 1 μt. T T t=1. β) Zeit stetig.")
263
3) Es können stochastische Größen in den Prozess eingehen
A) wi ist Zufallsvariable: Ansatz wie oben; Funktionsgleichung wird bei Diskreten zu einfach gewichtet. B) Systemfunktion ist Markoff‘scher Prozess; d.h. die Obergänge in verschiedene Werte xi+1 finden nur mit gewisser Wahrscheinlichkeit statt; erwartetes Verhalten ist zu errechnen.
 wi ist Zufallsvariable: Ansatz wie oben; Funktionsgleichung wird bei Diskreten zu einfach gewichtet. B) Systemfunktion ist Markoff‘scher Prozess; d.h. die Obergänge in verschiedene Werte xi+1 finden nur mit gewisser Wahrscheinlichkeit statt; erwartetes Verhalten ist zu errechnen.")
264
III. ENTSCHEIDUNG OHNE INFORMATIONSBESCHAFFUNG
A) Einstufige Entscheidungsprozesse Möglichkeit unter Unsicherheit Ausgangsbasis: - A = Menge der Aktionen (hier: endlich) - Z = Menge der Zustände (hier: endlich) - X = (A x Z) = Menge der Konsequenzen auf X existiert eine schwache Präferenzrelation (vollständig, transitiv) - Es existiert eine Abbildung, die kardinale Nutzenfunktion: u : A × Z 1
 Einstufige Entscheidungsprozesse. Möglichkeit unter Unsicherheit. Ausgangsbasis: - A = Menge der Aktionen (hier: endlich) - Z = Menge der Zustände (hier: endlich) - X = (A x Z) = Menge der Konsequenzen. auf X existiert eine schwache Präferenzrelation (vollständig, transitiv) - Es existiert eine Abbildung, die kardinale Nutzenfunktion: u : A × Z 1.")
265
Wir gehen im folgenden davon aus, dass sich der Entscheidungsträger nicht durch zusätzliche Investitionen in Informationsbeschaffungsprozesse informieren müsse, sondern auf Grund einer vorgegebenen Datenkonfiguration entscheiden müsse. Die Entscheidung bestehe in der Auswahl einer „besten“ Alternative! BWL unterscheidet: 1) Entscheidung unter Ungewissheit 2) Entscheidung unter Unsicherheit (es sind Zustandswahrscheinlichkeiten bekannt und diese werden in die Entscheidung einbezogen! Wir treffen hier diese Unterscheidung nicht!
 Entscheidung unter Ungewissheit. 2) Entscheidung unter Unsicherheit. (es sind Zustandswahrscheinlichkeiten bekannt und diese werden in die Entscheidung einbezogen! Wir treffen hier diese Unterscheidung nicht!")
266
1) ENTSCHEIDUNGSREGELN (j J (= {1, 2, .... n}); i I (= {1, 2, .... m})
1) Maximin-Regel (auch Wald-Regel) Jeder Aktion ai wird eine Zahl mi nach AI MI = min u (ai, zj) (Minimum über Zustände) zugeordnet. j J Dann bestimmt man M = max mi = max min u (ai, zj) i I i I j J Eine Aktion ai für die gilt mi = M heißt Maximin-Regel-Aktion (Minimax- Verlust-Aktion). Bemerkung: Diese und die folgenden Auswahlregeln leisten also zweierlei: 1) Sie definieren in der Menge A eine schwache Präferenzrelation 2) Sie liefern ein „größtes“ Element (d. h. ein Element, dem kein anderes vorgezogen wird) von A.
 Maximin-Regel (auch Wald-Regel) Jeder Aktion ai wird eine Zahl mi nach. AI MI = min u (ai, zj) (Minimum über Zustände) zugeordnet. j J. Dann bestimmt man. M = max mi = max min u (ai, zj) i I i I j J. Eine Aktion ai für die gilt mi = M heißt Maximin-Regel-Aktion (Minimax- Verlust-Aktion). Bemerkung: Diese und die folgenden Auswahlregeln leisten also zweierlei: 1) Sie definieren in der Menge A eine schwache Präferenzrelation. 2) Sie liefern ein „größtes Element (d. h. ein Element, dem kein anderes vorgezogen wird) von A.")
267
Problematik: Pathologischer Pessimismus (Krelle)
Beispiel: Z0 Z1 Z2 a1 0, a Nach obiger Regel gilt: a2 a1 (Auf Verlustfunktionen - U Minimax-Verlust-Regel) ~
 ~")
268
Die geometrische Interpretation der Maximin-Regel
Ist die Zustandsmenge Z endlich, d. h. es gilt |Z| = n, dann kann die Menge der Aktionen als Punktmenge in N gezeichnet werden. Beispiel: α) Z1 Z2 β) Z1 Z2 a a1 0 10 a a2 2 7 a a3 8 2 Z1 a1 a2 . . a3 Z2 Z1 . a3 . a2 a1 Z2 Q(v) Q (v) Q(v) = {(x1, .... xn) | min xj > V} j J
 Z1 Z2 β) Z1 Z2. a a a a a3 8 8 a Z a1. 10 a2 . . a3. 10 Z2. Z1. . a3. . a2. a1. Z2. Q(v) Q (v) Q(v) = {(x1, .... xn) | min xj > V} j J.")
269
Die Punkte a A, welche „zuletzt“ auf dem Rand Q (v) liegen, bei Verschiebung von Q (v) in Richtung v, sind Maximin-Aktionen; Bemerkung: es können auch mehrere Punkte sein. α) a β) a3, a2
 a1 β) a3, a2.")
270
2.) Die Minimax-Regret-Regel (auch Savage-Niehans-Regel)
Bildet zunächst aus der Entscheidungsmatrix die Opportunitätskostenmatrix mit den Elementen sij = max u u k kj ij Spaltenmaximum Die Zahl sij kann als „Maß des Bedauerns“ aufgefasst werden, wenn ai gewählt wurde und man dann erst erfährt, welcher Zustand Zj nun tatsächlich eingetroffen ist. Auf die Opportunitätskostenmatrix wendet man das Minimax-Verfahren an: mi = max sij (Zeilenmaximum von S) j J M‘ = min mi‘ = min max s (ai, zj) i I i I j J
 j J. M‘ = min mi‘ = min max s (ai, zj) i I i I j J.")
271
Die Aktion, für die m‘i = M‘ gilt, heißt Minimax-Regret-Regel
(Name kommt von Verlustinterpretation) Beispiele: α) Opportunitätskostenmatrix z1 z2 z1 z2 max. a a min a a a a max 12 12 β) Opportunitätskostenmatrix a a a a min a a max 8 10
 Beispiele: α) Opportunitätskostenmatrix. z1 z2 z1 z2 max. a a min. a a a3 8 8 a max β) Opportunitätskostenmatrix. a a a2 2 7 a min. a3 8 2 a max")
272
α) β) Q‘(v) = {x1, x2, ... xn) | max xj v} j J a1 ist „beste“ Aktion! α2 ist „beste Aktion!

273
Die durch diese Regel eingeführte schwache Präferenzrelation ist dann oft
ai aj, wenn m‘i > m‘j. ~ Kritisches Beispiel: Opportunitäts- kostenmatrix Z1 Z2 Z Z1000 Z1 Z2 Z Z1000 max a a a a a1 ~ a2 nach Savage-Niehans-Regel! Grund: Es gehen keine Größenverhältnisse wie „Anzahl der Umweltzustände“ usw. ein. (ähnlich: Minimax-Regel)
")
274
3) Die Bayes‘sche Entscheidungsregel
Versuch einer Einbeziehung der Zustandseintreffensplausibilität: Bewertung der Zustände (mit Wahrscheinlichkeiten!) Möglichkeiten zur Bewertung der Eintreffensplausibilität: A) Anerkannte Wahrscheinlichkeitsgesetze und anerkannte Erfahrung Beispiel: 1) Telefonanrufe je Zeiteinheit sind nach Poisson verteilt: E-λ λx : x = 0, 1, .... x! 2) Glücksspiele u.a.m. B) Wahrscheinlichkeit muss geschätzt bzw. ermittelt werden: 1) Simulationsversuche zur Ermittlung der Wahrscheinlichkeiten 2) Das Einsetzen eigener (indiv. oder gremialer) Erfahrung zur Festlegung von Wahrscheinlichkeiten subjektive Wahrscheinlichkeitsermittlung.
 Möglichkeiten zur Bewertung der Eintreffensplausibilität: A) Anerkannte Wahrscheinlichkeitsgesetze und anerkannte Erfahrung. Beispiel: 1) Telefonanrufe je Zeiteinheit sind nach Poisson verteilt: E-λ λx. : x = 0, 1, .... x! 2) Glücksspiele. u.a.m. B) Wahrscheinlichkeit muss geschätzt bzw. ermittelt werden: 1) Simulationsversuche zur Ermittlung der Wahrscheinlichkeiten. 2) Das Einsetzen eigener (indiv. oder gremialer) Erfahrung zur Festlegung von Wahrscheinlichkeiten subjektive Wahrscheinlichkeitsermittlung.")
275
Subjektive Wahrscheinlichkeit
Ziel: Ermittlung der Wahrscheinlichkeiten für Ereignisse, deren „objektive“ Wahrscheinlichkeiten nicht bekannt sind, aufgrund der Informationen (und) der Erfahrung des Entscheidungsträgers. Ausgangspunkt: 1) Menge von Ergebnissen (Stichprobenraum): S 2) Menge von Ereignissen: P (S) (für endliches |S|) 3) Auf der Menge der Ereignisse sei eine schwache Präferenzrelation für jedes Paar A, B P (S) erklärt. Gilt A B, so sagen wir, B trifft mindestens ebenso wahrscheinlich ein als A. Definition: Eine Wahrscheinlichkeitsverteilung W für die gilt: W (A) < W (B) genau dann, wenn A B stimmt mit der Relation überein. Problem: Angabe der Bedingungen, die erfüllt werden müssen, damit eine einzige Wahrscheinlichkeitsverteilung existiert, die diese erfüllt. < ~ < ~ < ~ < ~
 der Erfahrung des Entscheidungsträgers. Ausgangspunkt: 1) Menge von Ergebnissen (Stichprobenraum): S. 2) Menge von Ereignissen: P (S) (für endliches |S|) 3) Auf der Menge der Ereignisse sei eine schwache Präferenzrelation für jedes Paar A, B P (S) erklärt. Gilt A B, so sagen wir, B trifft mindestens ebenso wahrscheinlich ein als A. Definition: Eine Wahrscheinlichkeitsverteilung W für die gilt: W (A) < W (B) genau dann, wenn A B. stimmt mit der Relation überein. Problem: Angabe der Bedingungen, die erfüllt werden müssen, damit eine einzige Wahrscheinlichkeitsverteilung existiert, die diese erfüllt. < ~ < ~ < ~ < ~")
276
Zu treffende Annahmen:
A < B A ist nicht wahrscheinlicher als B! ~ SW1: Für zwei beliebige Ereignisse A und B muss genau eine der folgenden 3 Relationen gelten: A B B A (Zusammenhang) A ~ B SW2: Für vier Ereignisse A1, A2, B1, B2 gelte: A1 A2 = B1 B2 = Ø und Ai Bi (i = 1, 2). Dann folgt A1 A2 B1 B2 und falls entweder A1 B1 oder A2 B2 dann folgt A1 A2 B1 B2 < ~ < ~
 A ~ B. SW2: Für vier Ereignisse A1, A2, B1, B2 gelte: A1 A2 = B1 B2 = Ø. und Ai Bi (i = 1, 2). Dann folgt A1 A2 B1 B2 und falls entweder A1 B1 oder A2 B2. dann folgt. A1 A2 B1 B2. < ~ < ~")
277
< ~ SW3: Sei A irgendein nicht-leeres Ereignis, so gilt Ø A. Zudem gilt Ø S (S = Elementarereignismenge, Stichprobenraum). SW4: Ist A1, A2 ... eine abnehmende Folge von Ereignissen und B sei ein bestimmtes Ereignis, für das gelte: Ai B (für i = 1, 2, ...). Dann folgt Ai B. i = 1 Kraft, Pratt, Seidenberg 1959: Antwort auf Frage von B. de Finetti und L. Savage, ob diese Bedingungen genügen, damit immer zumindest eine Wahrscheinlichkeitsverteilung existiert, die mit einer Relation , die SWi (i = 1, 2, 3, 4) erfüllen, ÜBEREINSTIMMT: NEIN! Daher ist eine 5. Annahme erforderlich: ~ > ~ < ~
. Dann folgt. Ai B. i = 1. Kraft, Pratt, Seidenberg. 1959: Antwort auf Frage von B. de Finetti und L. Savage, ob diese Bedingungen genügen, damit immer zumindest eine Wahrscheinlichkeitsverteilung existiert, die mit einer Relation , die SWi (i = 1, 2, 3, 4) erfüllen, ÜBEREINSTIMMT: NEIN! Daher ist eine 5. Annahme erforderlich: ~ > ~ < ~")
278
SW5:. Es existiert eine Zufallsvariable mit einer Gleichverteilung
SW5: Es existiert eine Zufallsvariable mit einer Gleichverteilung in [0,1]. Bemerkung: Es gelte für ein beliebiges Intervall I = [a, b]: λ (I) ist die Länge (b - a) des Intervalls. Wir definieren nun eine Gleichverteilung ohne Angabe von Wahrscheinlichkeiten. Definition: Sei X eine Zufallsvariable 0 < X (s) < 1 (s S). Die Zufallsvariable X heißt gleichverteilt in [0, 1], wenn folgende Eigenschaft gilt: Für I1, I2 [0, 1] gilt {x I1} {x I2} genau dann, wenn λ (I1) < λ (I2) gilt. Aufgabe von Annahme SW5: Die Zuordnung von numerischen Wahrscheinlichkeiten ist manchmal schwer möglich; z.B. gelte A Ac . Um die Wahrscheinlichkeit von A festzustellen, genügt es, ein Ereignis {x I} zu finden, für das gilt: {x I} ~ A. < ~
 ist die Länge (b - a) des Intervalls. Wir definieren nun eine Gleichverteilung ohne Angabe von Wahrscheinlichkeiten. Definition: Sei X eine Zufallsvariable 0 < X (s) < 1 (s S). Die Zufallsvariable X heißt gleichverteilt in [0, 1], wenn folgende Eigenschaft gilt: Für I1, I2 [0, 1] gilt {x I1} {x I2} genau dann, wenn λ (I1) < λ (I2) gilt. Aufgabe von Annahme SW5: Die Zuordnung von numerischen Wahrscheinlichkeiten ist manchmal schwer möglich; z.B. gelte A Ac . Um die Wahrscheinlichkeit von A festzustellen, genügt es, ein Ereignis {x I} zu finden, für das gilt: {x I} ~ A. < ~")
279
Hierdurch ist eine Verteilung W auf S konstruierbar.
Nun kann man zeigen: Satz 1: Sei A ein Ereignis, so existiert eine einzige Zahl a* (0 < a* < 1), sodass A ~ {x (0, a*)} Hierdurch ist eine Verteilung W auf S konstruierbar. Satz 2: W stimmt mit auf S überein. Satz 3: Erfüllt " " SW1 - SW5, so ist die nach Satz 1 konstruierte Verteilung W die einzige Verteilung, die übereinstimmt. Literatur: z.B. DeGroot M., Optimal Statistical Decissions, McGraw-Hill 1970. < ~ < ~
, sodass. A ~ {x (0, a*)} Hierdurch ist eine Verteilung W auf S konstruierbar. Satz 2: W stimmt mit auf S überein. Satz 3: Erfüllt SW1 - SW5, so ist die nach Satz 1 konstruierte Verteilung W die einzige Verteilung, die übereinstimmt. Literatur: z.B. DeGroot M., Optimal Statistical Decissions, McGraw-Hill < ~ < ~")
280
Die Bayes‘sche Entscheidungsregel — Fortsetzung
Während die Maximin-Regel noch mit ordinalem Nutzenindex ihr Auslangen gefunden hätte, fordern die Minimax-Regret-Regel und auch die Bayes-Entscheidungsregel bereits eine kardinale Nutzenfunktion. Die Anwendbarkeit der Regel fordert noch zusätzlich das Vorliegen eines Wahrscheinlichkeitsvektors n (w1, w2, ... wn) ( wj = 1) j=1 Für das Eintreffen der Zustände Z1, Z2, .... Zn.
 ( wj = 1) j=1. Für das Eintreffen der Zustände Z1, Z2, .... Zn.")
281
Vorgangsweise: Man ermittelt den erwarteten Nutzen für jede Aktion AI: n (ai) = wj uij j=1 Man bestimmt dann jene Aktion a*, für die gilt: φ (a*) = max φ (ai) (bei Verlusttafel: min!) aiA Definition: a* heißt Bayes-Aktion zur Bewertung (w1, w2, .... wn).
 = max φ (ai) (bei Verlusttafel: min!) aiA. Definition: a* heißt Bayes-Aktion zur Bewertung (w1, w2, .... wn).")
282
Die Bayes-Entscheidungsregel gewinnt u. a
Die Bayes-Entscheidungsregel gewinnt u.a. auch dadurch an Bedeutung, dass es Feststellungen gibt, die von der Form der a priori Verteilung unabhängig sind! Definition: Eine Aktion a A heißt Bayes-Aktion, wenn es eine Bewertung gibt, für die a zur optimalen Aktion wird! Behauptung: Jede Bayes-Aktion berechnet aus einer Verlusttafel ist gleich der Bayes-Aktion, berechnet aus der zugehörigen Regrettafel.

283
Nachweis: Es gilt: * (ai) = wj (-u (ai, zj));
jJ Weiters gelte: ‘ (ai) = wj s (ai, zj) = = wj (max {ukj} - uij) = jJ kJ = (wj max {ukj} - wj uij) = C (gew. Spaltenmaxima) + (ai) Nun gilt: a*i = min * (ai) = max (ai) (=Bayes-Regel) Aber auch: a*i = min (C + * (ai)) = min (C - (ai)) d.h. also, die gestiftete Ordnungsrelation ist die gleiche!
 = wj s (ai, zj) = = wj (max {ukj} - uij) = jJ kJ. = (wj max {ukj} - wj uij) = C (gew. Spaltenmaxima) + (ai) Nun gilt: a*i = min * (ai) = max (ai) (=Bayes-Regel) Aber auch: a*i = min (C + * (ai)) = min (C - (ai)) d.h. also, die gestiftete Ordnungsrelation ist die gleiche!")
284
Beispiel 1): Bewertung (w1 = 0,2; w2 = 0,8);
Entscheidungstafel Regrettafel Z1 Z2 Z1 Z2 a a1 0 0 a a2 2 6 a a3 4 4 Bewertung (0, 2, 0, 8): (a1) = 2,4 + 9,6 = 12 ‘ (a1) = 0 (a2) = 2 + 4,8 = 6,8 ‘ (a2) = 0,4 + 4,8 = 5,2 (a3) = 1,6 + 6,4 = 8 ‘ (a3) = 0,8 + 3,2 = 4,0 a* = a1 a* = min ‘ (ai) = a1 C = 12
: (a1) = 2,4 + 9,6 = 12 ‘ (a1) = 0. (a2) = 2 + 4,8 = 6,8 ‘ (a2) = 0,4 + 4,8 = 5,2. (a3) = 1,6 + 6,4 = 8 ‘ (a3) = 0,8 + 3,2 = 4,0. a* = a1 a* = min ‘ (ai) = a1. C = 12.")
285
Beispiel 2): w1 = 0,2 w2 = 0,8 Regrettafel: Z1 Z2 Z1 Z2 a a1 8 0 a a2 6 3 a a3 0 8 (a1) = 8 - max ‘ (a1) = 1,6 - min (a2) = 6 ‘ (a2) = 3,6 (a3) = 3,2 ‘ (a3) = 6,4 a* = a1 a* = a1 C = 0,2 8 + 0,8 10 = 9,6
 = 8 - max ‘ (a1) = 1,6 - min. (a2) = 6 ‘ (a2) = 3,6. (a3) = 3,2 ‘ (a3) = 6,4. a* = a1 a* = a1. C = 0,2 8 + 0,8 10 = 9,6.")
286
Bemerkung: Sehr interessant ist auch die umgekehrte Fragestellung: Für welche Bewertungen sind a1, a2 und a3 Bayes-Aktionen? Wir nehmen zur Bestimmung die Verlusttafel (neg. Nutzentafel). Regrettafel: w1 w2 w1 w2 Z1 Z2 Z1 Z2 a a1 8 0 a a2 6 3 a a3 0 8
. Regrettafel: w1 w2 w1 w2. Z1 Z2 Z1 Z2. a a a2 2 7 a a3 8 2 a")
287
Offenbar gilt: Für w2 = 1 und w1 = 0 : a* = a1
Für den Zwischenbereich gilt (z. B. w1 = 0,5; w2 = 0,5 : a* = a2) Wegen w2 = 1 - w1 genügt es zunächst, die Grenzen in a1 zu finden: a* = a a* = a2 a* = a3 1. Grenze: 8w1 = 6w1 + 3 (1 - w1) 5w1 = 3 w1 = = 0,6 2. Grenze: 8w2 = 6 (1 - w2) + 3w2 8w2 = 6 - 6w2 + 3w2 8w2 + 3w2 = 6 w2 = w1 = 0,4545 0, w1=1 3 5 6 11 5 11
 Wegen w2 = 1 - w1 genügt es zunächst, die Grenzen in a1 zu finden: a* = a1 a* = a2 a* = a3. 1. Grenze: 8w1 = 6w1 + 3 (1 - w1) 5w1 = 3 w1 = = 0,6. 2. Grenze: 8w2 = 6 (1 - w2) + 3w2 8w2 = 6 - 6w2 + 3w2 8w2 + 3w2 = 6 w2 = w1 = 0, ,6 w1=")
288
Graphisch: w1 = w w2 = 1 - w1 Z1 Z2 a1 0 10 a2 2 7 a3 8 2 (a1,w)
I…(?) Lösung (5/11, 6/11) (a3,w) (a3) (a2,w) (a2) (a1) min-Regretwert = max Nutzen = min Verlust 0,5 0,6 0,4545 1 w
 Lösung (5/11, 6/11) (a3,w) (a3) (a2,w) (a2) (a1) min-Regretwert. = max Nutzen. = min Verlust. 0,5. 0,6. 0, w.")
289
Regrettafelrechnung = Nutzentafelrechnung
3 = 5w w = 0,6 3 Gleichungen: 0w + 10 (1-w) = w = (a1, w) 2w + 7 (1-w) = 7 - 5w = (a2, w) 8 = 16w w = ½ 8w + 2 (1-w) = 2 + 6w = (a3, w) 5 = 11w w = 5/11 Spieltheoretische Betrachtung: Randomisierung: Könnte ein „Gegner“ den Bewertungsvektor wählen, so würde er ihn so wählen, dass die beste Aktion möglichst nieder bewertet wird.
 = w = (a1, w) 2w + 7 (1-w) = 7 - 5w = (a2, w) 8 = 16w w = ½. 8w + 2 (1-w) = 2 + 6w = (a3, w) 5 = 11w w = 5/11. Spieltheoretische Betrachtung: Randomisierung: Könnte ein „Gegner den Bewertungsvektor wählen, so würde er ihn so wählen, dass die beste Aktion möglichst nieder bewertet wird.")
290
Beispiel 2 Z1 Z2 a1 0 10 a2 2 7 Verlusttafel a3 8 2 Beispiel: 0,8 = w1 0,2 = w2 Bayes-Aktion ai

291
Geometrische Deutung (|Z| = 2)
(b1) Bayes-Aktion A1 -u.1 = -u.2 (b3) (b2) A2 (b3, b3) = (φ (a3), φ (a3)) b2, b2 Geometrische Deutung (|Z| = 2) (z. B. müssten bei w1 = 0,5 a1 und a3 auf ε (b) liegen!)
 Bayes-Aktion. A1. -u.1 = -u.2. (b3) (b2) A2. (b3, b3) = (φ (a3), φ (a3)) b2, b2. Geometrische Deutung (|Z| = 2) (z. B. müssten bei w1 = 0,5 a1 und a3 auf ε (b) liegen!)")
292
Bayes-Entscheidung (bei Maximierung)
(a1) = 2 - min (a2) = 3 (a3) = 6,8 Bezeichnung: (bi) w1 ui1 + w2 ui2 = bi Bemerkung: (bi) schneidet die Gerade u.1 = u.2 im Punkt (bi, bi); da ja gelten muss p x1 + (1-p) x2 = bi für x1 = x2 = x (p+1-p) x = bi 1 Schnittpunkte mit den Koordinaten: dort wo w1 ui1 = (ai) bzw. w2 ui2 = (ai)
 = 2 - min. (a2) = 3. (a3) = 6,8. Bezeichnung: (bi) w1 ui1 + w2 ui2 = bi. Bemerkung: (bi) schneidet die Gerade u.1 = u.2 im Punkt (bi, bi); da ja gelten muss. p x1 + (1-p) x2 = bi für x1 = x2 = x (p+1-p) x = bi. 1. Schnittpunkte mit den Koordinaten: dort wo w1 ui1 = (ai) bzw. w2 ui2 = (ai)")
293
Andere (abgeleitete) Entscheidungsregeln
Bayes-Aktion: Jene, die bei Verschieben in positiver Richtung u.1 = u.2 die letzte Aktion ist, die von (b) berührt wird! (Bei Verlusttafel - die erste Aktion) Andere (abgeleitete) Entscheidungsregeln 1) Laplace-Regel: Spezielle Bewertung der Zustandswahr- scheinlichkeiten mit wi = (i = 1, 2, .... n) Also: Spezialfall der Bayes-Regel Praktisch genügt es, den Faktor 1/n wegzulassen; es gilt dann: n (ai) = uij j=1 Bemerkung: Hinzufügen einer identischen Spalte kann beste Aktion ändern: a1 a2 1 – n
 berührt wird! (Bei Verlusttafel - die erste Aktion) Andere (abgeleitete) Entscheidungsregeln. 1) Laplace-Regel: Spezielle Bewertung der Zustandswahr- scheinlichkeiten mit wi = (i = 1, 2, .... n) Also: Spezialfall der Bayes-Regel. Praktisch genügt es, den Faktor 1/n wegzulassen; es gilt dann: n. (ai) = uij. j=1. Bemerkung: Hinzufügen einer identischen Spalte kann beste Aktion ändern: a1. a2 – n.")
294
2) Die Maximax-Regel: Auswahlfunktion: (ai) = max uij jJ Man wählt dann diejenige Aktion, die (ai) maximiert: a* = max (ai) ai A Einwand: Pathologischer Optimismus
 ai A. Einwand: Pathologischer Optimismus.")
295
3) Optimismus-Pessimismus-Regel (Hurwicz-Regel)
Es gelte für die Auswahlfunktion: (ai) = max uij + (1 - ) min uij jJ jJ a* = max (ai) aiA Bemerkung: Für = 1 entspricht sie Maximax-Regel; Für = 0 entspricht sie Maximin-Regel; Also Kompromiss! Empirische Ermittlung des Wertes von : man stelle dem Entscheidungsträger folgendes Problem: Z1 Z2 a1 1 0 a2 x x
 = max uij + (1 - ) min uij. jJ jJ. a* = max (ai) aiA. Bemerkung: Für = 1 entspricht sie Maximax-Regel; Für = 0 entspricht sie Maximin-Regel; Also Kompromiss! Empirische Ermittlung des Wertes von : man stelle dem Entscheidungsträger folgendes Problem: Z1 Z2. a a2 x x.")
296
Er möge x derart festlegen, dass er zwischen a1 und a2 indifferent ist.
Nun gilt: (a1) = also x = ! (a2) = x Bemerkung: Hurewicz-Regel erfordert kardinale Nutzenmessung, da sie gegenüber monotonen Transformationen nicht indifferent ist! Ähnliche Problematik wie bei Minimax: Z1 Z2 Z3 Z4 Z5 Z6 Z7 ... Zn a a
 = also x = ! (a2) = x. Bemerkung: Hurewicz-Regel erfordert kardinale Nutzenmessung, da sie gegenüber monotonen Transformationen nicht indifferent ist! Ähnliche Problematik wie bei Minimax: Z1 Z2 Z3 Z4 Z5 Z6 Z7 ... Zn. a a")
297
4) Hodges-Lehmann-Regel
Es gelte mi = min u (ai, zj); u (ai) = pj uij jJ jJ Für die Bewertungsfunktion gilt dann: (ai) = (1 - ) mi + u (ai) a* = max (ai) aiA Bemerkung: Wird insbesondere für unsichere Zustandswahrscheinlichkeiten gerne verwendet! Die Hodges-Lehmann-Regel ist ein Kompromiss zwischen der Bayes- und der Maximin-Regel. Gilt = 1 Bayes-Regel = 0 Maximin-Regel
; u (ai) = pj uij. jJ jJ. Für die Bewertungsfunktion gilt dann: (ai) = (1 - ) mi + u (ai) a* = max (ai) aiA. Bemerkung: Wird insbesondere für unsichere Zustandswahrscheinlichkeiten gerne verwendet! Die Hodges-Lehmann-Regel ist ein Kompromiss zwischen der Bayes- und der Maximin-Regel. Gilt = 1 Bayes-Regel. = 0 Maximin-Regel.")
298
5) Krelle-Regel Krelle schlägt vor, 2 Dinge zu trennen: a) Die Scheu vor Unsicherheit - ausgedrückt durch eine Unsicherheitspräferenzfunktion - (Ermittlung analog zur kardinalen Nutzenfunktion): b) Die (kardinalen) Nutzenwerte (praktisch jedoch homogenen Einheiten; z. B. Geld): uij Entscheidungsregel: (ai) = (uij) jJ a* = max (ai) aiA Krelle bewertet praktisch wie Laplace mit 1/n, da er summiert! Unsicherheitspräferenzfunktion
 Die Scheu vor Unsicherheit - ausgedrückt durch eine Unsicherheitspräferenzfunktion - (Ermittlung analog zur kardinalen Nutzenfunktion): b) Die (kardinalen) Nutzenwerte (praktisch jedoch homogenen Einheiten; z. B. Geld): uij. Entscheidungsregel: (ai) = (uij) jJ. a* = max (ai) aiA. Krelle bewertet praktisch wie Laplace mit 1/n, da er summiert! Unsicherheitspräferenzfunktion.")
299
Bemerkung: Die Entscheidungsregel entspricht der Laplace-Regel mit gewichtetem Nutzen; da jedoch anstelle des Nutzens ein homogenes Gut, z.B. Geld, gemeint ist, entspricht diese Entscheidungsregel der Laplace-Regel (Wichtung = Nutzenbewertung). Abschluss: Alle Regeln sind gegenüber linearen Transformationen invariant! (Minimax-Regel: invariant gegenüber monotonen Transformationen)
. Abschluss: Alle Regeln sind gegenüber linearen Transformationen invariant! (Minimax-Regel: invariant gegenüber monotonen Transformationen)")
300
Beispiele: 1) (aus Bamberg, Coenenberg) Ein Unternehmen habe für drei zur Debatte stehende Aktionen folgende Entscheidungsmatrix ermittelt: Zustände Aktion Z1 Z2 Z3 Opportunitätskostenmatrix: a a a

301
Wie lautet die optimale Aktion bei Verwendung von:
a) Maximin-Regel b) Maximax-Regel c) Hurwicz-Regel ( = 0,3) d) Laplace-Regel e) Savage-Niehans-Regel f) Krelle-Regel g) Hodges-Lehmann-Regel ( = 0,2) h) Bayes-Regel (w1 = 0,3; w2 = 0,6; w3 = 0,1) Maximin schlägt durch!
 Maximin-Regel. b) Maximax-Regel. c) Hurwicz-Regel ( = 0,3) d) Laplace-Regel. e) Savage-Niehans-Regel. f) Krelle-Regel. g) Hodges-Lehmann-Regel ( = 0,2) h) Bayes-Regel (w1 = 0,3; w2 = 0,6; w3 = 0,1) Maximin schlägt durch!")
302
2) Dominanzrelationen auf der Aktionenmenge
Entscheidungsregel: Abbildung von A in die reellen Zahlen! Mittels der Ordnung der reellen Zahlen wurde in A eine vollständige Ordnungsrelation eingeführt! Allerdings je nach Entscheidungsregel verschiedene Anordnungen möglich! Definition: A) Die Aktion ai DOMINIERT die Aktion Ak, wenn u (ak, z) < u (ai, z) gilt (reflexiv, antisymmetrisch, transitiv) für alle z. B) Die Aktion ai DOMINIERT STRENG die Aktion ak, wenn A) gilt und zusätzlich: u (ak, z) < u (ai, z) für mindestens ein z gilt! (irreflexiv, asymetrisch, transitiv) C) Zwei Aktionen werden als gleich bezeichnet, wenn gilt: u (ai, z) = u (ak, z) für alle z (nicht trivial, da aus der Gleichheit des Nutzens (und nicht der Konsequenzen) die Gleichheit ai = ak definiert wird.)
 Die Aktion ai DOMINIERT die Aktion Ak, wenn u (ak, z) < u (ai, z) gilt (reflexiv, antisymmetrisch, transitiv) für alle z. B) Die Aktion ai DOMINIERT STRENG die Aktion ak, wenn A) gilt und zusätzlich: u (ak, z) < u (ai, z) für mindestens ein z gilt! (irreflexiv, asymetrisch, transitiv) C) Zwei Aktionen werden als gleich bezeichnet, wenn gilt: u (ai, z) = u (ak, z) für alle z (nicht trivial, da aus der Gleichheit des Nutzens (und nicht der Konsequenzen) die Gleichheit ai = ak definiert wird.)")
303
Eine wichtige Eigenschaft:
Die Dominanzrelation stimmt mit den Auswahlregeln r überein; d.h. aus ak ai folgt ak rai (nicht unbedingt umgekehrt!) Definition: A) Eine Aktion heißt ZULÄSSIG, wenn sie von keiner Aktion streng dominiert wird. B) Eine Menge von Aktionen B A heißt VOLLSTÄNDIG, wenn jede Aktion außerhalb von B von einer Aktion in B streng dominiert wird. C) B A heißt MINIMAL VOLLSTÄNDIG, wenn sie keine echte Teilmenge enthält, die ebenfalls vollständig ist. Bemerkung: Endliche Aktionenmengen haben immer minimale vollständige Aktionenteilmengen; (unendliche nicht!) ~ ~ ~
 Definition: A) Eine Aktion heißt ZULÄSSIG, wenn sie von keiner Aktion streng dominiert wird. B) Eine Menge von Aktionen B A heißt VOLLSTÄNDIG, wenn jede Aktion außerhalb von B von einer Aktion in B streng dominiert wird. C) B A heißt MINIMAL VOLLSTÄNDIG, wenn sie keine echte Teilmenge enthält, die ebenfalls vollständig ist. Bemerkung: Endliche Aktionenmengen haben immer minimale vollständige Aktionenteilmengen; (unendliche nicht!) ~ ~ ~")
304
• a2,a3 Minimale vollständige Aktionenmenge • a4 a5 a6 • • u2 Umwelt
Beispiel: u a1 • • a2,a Minimale vollständige Aktionenmenge • a4 a5 a6 • • u2 Umwelt Aktionen Z1 Z2 a1 9 5 a2 8 7 a3 8 7 a4 6 6 a5 4 8 a6 4 7

305
Vollständige Aktionenmengen (in obigem Beispiel):
{ai (i = 1, 2, .... , 6)} Komplement: und ({a1, a2, a3, a4, a5}, {a1, a2, a3, a5, a6}, {a1, a2, a3, a5}) Minimale vollständige Aktionenmenge: {a1, a2, a3, a5} ! Nicht hingegen: {a1, a2, a5} oder {a1, a3, a5} (a2 bzw. a3 werden von keiner Aktion streng dominiert) B B6
} Komplement: und ({a1, a2, a3, a4, a5}, {a1, a2, a3, a5, a6}, {a1, a2, a3, a5}) Minimale vollständige Aktionenmenge: {a1, a2, a3, a5} ! Nicht hingegen: {a1, a2, a5} oder {a1, a3, a5} (a2 bzw. a3 werden von keiner Aktion streng dominiert) B5 B6.")
306
Daher: Definition: a) Eine Aktionenmenge B heißt wesentlich vollständig, wenn jede Aktion außerhalb von B von einer Aktion in B dominiert wird! (nicht STRENG DOMINIERT) b) B heißt minimal wesentlich vollständig, wenn B keine ebenfalls wesentlich vollständige Teilmenge enthält! z.B.: B5 und B6 sind wesentlich vollständige Aktionenmengen, jedoch nicht vollständig!
 Eine Aktionenmenge B heißt wesentlich vollständig, wenn jede Aktion außerhalb von B von einer Aktion in B dominiert wird! (nicht STRENG DOMINIERT) b) B heißt minimal wesentlich vollständig, wenn B keine ebenfalls wesentlich vollständige Teilmenge enthält! z.B.: B5 und B6 sind wesentlich vollständige Aktionenmengen, jedoch nicht vollständig!")
307
Beispiel: a) Aktionenmenge, die - keine minimale vollständige Aktionenmenge und - keine zulässigen Aktionen besitzt. Z1 Z2 a1 0 0 a2 1/2 1/2 a3 3/4 3/4 . . . an n/n+1 n/n+1 Hat auch keine Bayes-Aktion! (keine kleinste Zahl!) Grund: Häufungspunkt (1,1) gehört nicht zur Aktionenmenge, da diese Menge OFFEN ist! • a6 • a5 • a4 • a3 • a2 • a
 Grund: Häufungspunkt (1,1) gehört nicht zur Aktionenmenge, da diese Menge OFFEN ist! 1 • a6. • a5. • a4. • a3. • a2. • a1 1.")
308
b). Aktionenmenge, deren zulässige Aktionenmenge nicht minimal
b) Aktionenmenge, deren zulässige Aktionenmenge nicht minimal vollständig ist. Umwelt Aktionen Z1 Z2 a0 3/2 1/2 a1 0 0 a2 1/2 1/2 a3 3/4 3/4 a4 4/5 4/5 . . . Wichtiger Satz: Existiert eine minimale vollständige Aktionenmenge, so ist sie eindeutig bestimmt; sie besteht dann gerade aus der Menge aller zulässigen Aktionen. Beweis: s. Ferschl. S. 76
 Aktionenmenge, deren zulässige Aktionenmenge nicht minimal vollständig ist. Umwelt. Aktionen Z1 Z2. a0 3/2 1/2. a a2 1/2 1/2. a3 3/4 3/4. a4 4/5 4/ Wichtiger Satz: Existiert eine minimale vollständige Aktionenmenge, so ist sie eindeutig bestimmt; sie besteht dann gerade aus der Menge aller zulässigen Aktionen. Beweis: s. Ferschl. S. 76.")
309
GEMISCHTE AKTIONEN Einführungsbeispiel: Betrachten wir folgendes Problem: Ein Besitzer einer Galerie kann für ein junges Talent, dessen Werke er vertreibt a1) eine Ausstellung organisieren a2) einige Werbeaktionen organisieren und dann ausstellen mit 1 ½ Jahren Verzögerung a3) sich an einer jährlichen Sammel-Förderungsausstellung beteiligen.
 eine Ausstellung organisieren. a2) einige Werbeaktionen organisieren und dann ausstellen mit 1 ½ Jahren Verzögerung. a3) sich an einer jährlichen Sammel-Förderungsausstellung beteiligen.")
310
Matrix Z1 Z2 a1 30 6 a Bisher Maximin: a a* = a2 Z1 = entspricht dem durchschnittlichen Geschmack Z2 = wird eher abgelehnt • a1 20 • a3 10 • a2 Frage: Der Besitzer der Galerie fragt sich, da er wiederholt vor diesem Problem steht, ob er am besten entscheidet, wenn er immer a2 wählt.

311
Alternative: Entscheidungsträger wählt gemischte Aktionen; d. h. er wählt die Aktionen nur mit gewissen Wahrscheinlichkeiten p1, p2, p3. Die Aktion ist dann so zu schreiben: p1 p2 p3 a‘ = ( pi = 1; pi > 0) a1 a2 a3 Menge der einfachen Aktionen Der Nutzen der Aktion a‘ ermittelt sich dann aus dem Erwartungswert über die einzelnen Spalten: 0,5 0,5 0 z. B. a‘ = a1 a2 a3
 a1 a2 a3. Menge der einfachen Aktionen. Der Nutzen der Aktion a‘ ermittelt sich dann aus dem Erwartungswert über die einzelnen Spalten: 0,5 0,5 0. z. B. a‘ = a1 a2 a3.")
312
Das Nutzentupel erhält man aus
(u11 p1 + u21 p2 + u31 p3, u12 p1 + u22 p2 + u32 p3): = (15 + 5, ) = (20, 13) Bemerkung: 1) Die Aktion a‘ dominiert a3 2) Die Aktion a‘ ist die optimale Maximin-Aktion! Z1 Z2 Minima der Zeilen a a a* max a* = a‘ nach Maximin-Kriterium
: = (15 + 5, ) = (20, 13) Bemerkung: 1) Die Aktion a‘ dominiert a3. 2) Die Aktion a‘ ist die optimale Maximin-Aktion! Z1 Z2 Minima der Zeilen. a a a* max a* = a‘ nach Maximin-Kriterium.")
313
Wir untersuchen dieses Phänomen mit intuitiven Argumenten genauer:
Definition: Die Menge der gemischten Aktionen A* ist die Menge aller Aktionen vom Typ p1 p2 ... pm a1 a2 ... am m pi = 1 und 1 > pi > 0 p=1 „Reine“ Aktionen sind also Spezialfälle!

314
Bemerkung:. Die Realisierung von gemischten Aktionen kann z. B. so
Bemerkung: Die Realisierung von gemischten Aktionen kann z.B. so erfolgen: Q wurde erzeugt, implizit A2 ist zu wählen! a1 a2 m-1 rp1 (p1+p2)r ( pi) r gesuchte Zufallszahl Q pi=1 Man erzeugt eine genauso gleichverteilte Zufallszahl Q in [0, r] und wählt jene Aktion, in deren Intervall Q fällt!
r ( pi) r gesuchte Zufallszahl Q. pi=1. Man erzeugt eine genauso gleichverteilte Zufallszahl Q in [0, r] und wählt jene Aktion, in deren Intervall Q fällt!")
315
Konstruktion des neuen Entscheidungsproblems:
u: A* Z 1 u (a*, z) ist der Nutzen, der eintritt, wenn a* gewählt wird! Es gibt allerdings unendlich viele Aktionen a* A*. Wir definieren: m m m u (a*, z) = ( pi u (ai, z1), pi u (ai, z2), ... , pi u (ai, zn)) i= i= i=1 Als Nutzentupel von a*. (Dies ist möglich auf Grund der Lotterieeigenschaften des Erwartungsnutzens!)
 ist der Nutzen, der eintritt, wenn a* gewählt wird! Es gibt allerdings unendlich viele Aktionen a* A*. Wir definieren: m m m. u (a*, z) = ( pi u (ai, z1), pi u (ai, z2), ... , pi u (ai, zn)) i=1 i=1 i=1. Als Nutzentupel von a*. (Dies ist möglich auf Grund der Lotterieeigenschaften des Erwartungsnutzens!)")
316
Geometrische Interpretation
Merksatz: ) Eine gemischte Aktion ist eine konvexe Linearkombination aus reinen Aktionen. 2) Die Menge A* ist gleich der konvexen Hülle der Menge A der reinen Aktionen! Obiges Beispiel: • • • •
 Eine gemischte Aktion ist eine konvexe Linearkombination aus reinen Aktionen. 2) Die Menge A* ist gleich der konvexen Hülle der Menge A der reinen Aktionen! Obiges Beispiel: • • • •")
317
Z1 Z2 a1 30 6 a a3 15 8 Optimale gemischte Maximin-Aktion: a*opt ~ (17,4; 17,4) Definition: Gilt a*opt = (c, c, ..., c) (c 1), so nennt man a*opt Equalizer-Aktion! Ermittlung der Wahrscheinlichkeiten unserer Equalizer Aktion a*opt: Bewertung: p1u11 + p2u21 = p1u12 + p2u22 p1 (u11 - u21) + p2 (u12 - u22) = 0 p1 + p2 = 1 Gleichungssystem mit zwei Unbekannten kann nach p1, p2 aufgelöst werden.
 (c 1), so nennt man. a*opt Equalizer-Aktion! Ermittlung der Wahrscheinlichkeiten unserer Equalizer Aktion a*opt: Bewertung: p1u11 + p2u21 = p1u12 + p2u22 p1 (u11 - u21) + p2 (u12 - u22) = 0. p1 + p2 = 1. Gleichungssystem mit zwei Unbekannten kann nach p1, p2 aufgelöst werden.")
318
Obiges Beispiel: 30p1 + 10p2 = 6p1 + 20p2 24p1 - 10p2 = 0 Also: 10p1 + 10p2 = 10 24p1 - 10p2 = 0 34p1 = 10 p1 = ; p2 = Die optimale Minimax-Aktion a*opt ist daher a*opt = ( ) Mit dem Wert: ( • • , • • ) = ( , ) (17.4, 17.4) 5 — 17 12 — 17 5/ /17 a a2 5 — 17 12 — 17 5 — 17 12 — 17 270 —– 17 270 —– 17 – ~
 Mit dem Wert: ( • • , • • ) = ( , ) (17.4, 17.4) 5. — — 17. 5/17 12/17. a1 a2. 5. — — — — —– —– 17. – ~")
319
Savage-Niehans-Regel und gemischte Aktionen
Regret-Werte Es gibt also auch hier Equalizer-Aktionen: a*opt

320
Bayes-Aktionen und gemischte Aktionen
m n Beispiel: (a*) = pi wj u (ai, zj) i=1 j=1 Bei der Bewertung (w1, w2) ist a3 Bayes-Aktion
 = pi wj u (ai, zj) i=1 j=1. Bei der Bewertung (w1, w2) ist a3 Bayes-Aktion.")
321
Aus diesem Beispiel ersieht man (beweisbar!):
Existiert eine gemischte Bayes-Aktion, so gibt es zugleich eine reine Aktion zur gleichen Bewertung der Bayes-Aktion. D. h. auf der Suche nach einer Bayes-Aktion müssen wir die gemischten Aktionen nicht berücksichtigen! Bemerkung zur Ermittlung allgemeiner gemischter Maximin-Aktionen: a) Mittels des Lösungsinstrumentariums der Theorie der 2-Personen- Nullsummenspiele möglich! b) Bei Maximin-Aktionen kann natürlich auch nur eine reine Aktion die optimale Aktion sein. aopt (Diese muss keine Equalizer-Aktion sein!)
 Mittels des Lösungsinstrumentariums der Theorie der 2-Personen- Nullsummenspiele möglich! b) Bei Maximin-Aktionen kann natürlich auch nur eine reine Aktion die optimale Aktion sein. aopt. (Diese muss keine Equalizer-Aktion sein!)")
322
VIII. Bayes‘sche mehrstufige Entscheidungen unter Unsicherheit ohne
VIII. Bayes‘sche mehrstufige Entscheidungen unter Unsicherheit ohne Informationsbeschaffung Wir wählen als Ausgangsbeispiel wieder das Lagerhaltungsproblem aus dem Kapitel „mehrstufige Entscheidungen bei Sicherheit“ (Nachfrage) wk Externe Störung (stochastisch) Bestellung = bk xk = Lagerbestand S (Steuerbereich) k (xk) = bk
 wk Externe Störung (stochastisch) Bestellung = bk xk = Lagerbestand. S (Steuerbereich) k (xk) = bk.")
323
Algorithmus: k0 (x0) ist der optimale Wert der Politik und es gilt (von N - 1 nach 0 gehend): kk (xk) = inf E {g (xk, bk, wk) + Kk+1 (fk (xk, bk, wk))} bkbk (xk)k K = 0, 1, ... N - 1 Jenes *k = *k (xk), welches die rechte Seite von obiger Funktionalgleichung minimiert, bildet das optimale Kontrolltupel: = (*0, *1, ... *n-1) (E steht für Erwartungswert)
 = inf E {g (xk, bk, wk) + Kk+1 (fk (xk, bk, wk))} bkbk (xk)k. K = 0, 1, ... N - 1. Jenes *k = *k (xk), welches die rechte Seite von obiger Funktionalgleichung minimiert, bildet das optimale Kontrolltupel: = (*0, *1, ... *n-1) (E steht für Erwartungswert)")
324
Wir lösen nun obiges Beispiel unter der Annahme, dass wir die Verteilung der wi je Periode kennen und dass über das tatsächliche Eintreffen des Bedarfs keine zusätzliche Information eingeholt werden könne: Es gelte: Lagerkapazität (xk + bk) : 0 < xk + bk < 2 Planungshorizont: 3 Perioden Lagerkosten: h = 1 Bestellkosten: c = 1 Kosten des nicht erfüllten Bedarfs: 3 Bedarfsverteilung: W (wk = 0) = 0,1 W (wk = 1) = 0,7 W (wk = 2) = 0,2
 : 0 < xk + bk < 2. Planungshorizont: 3 Perioden. Lagerkosten: h = 1. Bestellkosten: c = 1. Kosten des nicht erfüllten Bedarfs: 3. Bedarfsverteilung: W (wk = 0) = 0,1. W (wk = 1) = 0,7. W (wk = 2) = 0,2.")
325
Unsere Funktionalgleichung lautet:
Anfangsbestand x0 = 0; Systemgleichung: xk + 1 = max (0,xk + bk - wk) nicht erfüllter Bedarf ist verloren! K3 (x3) = 0 Unsere Funktionalgleichung lautet: Bestellkosten Lagerkosten Kosten d. entgangenen Bedarfs Kk (xk) = min E {bk - max (0,xk + bk - wk ) + 3 max (0,wk - xk - bk) + 0<bk<2-xk {wk} bk = 0, 1, 2 Kosten d. nächsten Periode bei xk+1 + Kk + 1 (max (0, xk + bk - wk))} K = 0, 1, 2; xk, bk, wk {0, 1, 2}
 nicht erfüllter Bedarf ist verloren! K3 (x3) = 0. Unsere Funktionalgleichung lautet: Bestellkosten Lagerkosten Kosten d. entgangenen Bedarfs. Kk (xk) = min E {bk - max (0,xk + bk - wk ) + 3 max (0,wk - xk - bk) + 0<bk<2-xk {wk} bk = 0, 1, 2. Kosten d. nächsten Periode bei xk+1. + Kk + 1 (max (0, xk + bk - wk))} K = 0, 1, 2; xk, bk, wk {0, 1, 2}")
326
Stufe 2: Wir berechnen K2 (x2) für jedes der drei möglichen Stadien: X2 = 0 K2 (0) = min E {b2 + max (0, b2 - w2) + 3 max (0, w2 - b2)} = bk=0,1,2, = min {b2 + 0,1 (max (0,b2) + 3 max (0 - b2)) b2=0,1,2 + 0,7 (max (0,b2 - 1) + 3 max (0, 1 - b2)) + + 0,2 ( max (0,b2 - 2 ) + 3 max (0,2 - b2))} Wir erhalten für: b2 = 0 3,3 (0,7 3 1 + 0,2 3 2) b2 = 1 1,7 (1 + 0,1 1 + 0,2 3 1) b2 = 2 2,9 (2 + 0,1 2 + 0,7 1) Also K2 (0) = 1,7; 2* (0) = 1 (opt. Bestellung)
 + 3 max (0 - b2)) b2=0,1,2. + 0,7 (max (0,b2 - 1) + 3 max (0, 1 - b2)) + + 0,2 ( max (0,b2 - 2 ) + 3 max (0,2 - b2))} Wir erhalten für: b2 = 0 3,3 (0,7 3 1 + 0,2 3 2) b2 = 1 1,7 (1 + 0,1 1 + 0,2 3 1) b2 = 2 2,9 (2 + 0,1 2 + 0,7 1) Also K2 (0) = 1,7; 2* (0) = 1 (opt. Bestellung)")
327
X2 = 1 K2 (1) = min E {b2 + max (0, 1 + b2 - w2) + 3 max (0, w2 - b2 - 1)} = b2=0,1 = min {b2 + 0,1 (max (0,1 - b2) + 3 max ( b2)) + 0,7 (max (0,b2) + 3 max (0 - b2)) + 0,2 (max (0,b2 - 1) + 3 max (0, 1 - b2))} Wir erhalten für: b2 = 0 0,7 (0,1 1 + 0,2 3) b2 = 1 1,9 (1 + 0,1 ,7 1) Also K2 (1) = 0,7; 2* (1) = 0
 + 3 max (0 - b2)) + 0,2 (max (0,b2 - 1) + 3 max (0, 1 - b2))} Wir erhalten für: b2 = 0 0,7 (0,1 1 + 0,2 3) b2 = 1 1,9 (1 + 0,1 ,7 1) Also K2 (1) = 0,7; 2* (1) = 0.")
328
Für X2 = 2, K2 (2) = E {max (0, 2 - w2) + 3max (0, w2 - 2)} w2
= 0,1 2 + 0,7 1 = 0,9 Also K2 (2) = 0,9; 2* (2) =0
 = 0,9; 2* (2) =0.")
329
Stufe 1. Nun berechnen wir K1 (x1), indem wir die oben berechneten
Stufe 1 Nun berechnen wir K1 (x1), indem wir die oben berechneten Werte K2 (0), K2 (1), K2 (2) hierzu heranziehen. Es gilt (s. obige Funktionalgleichung!) X1 = 0 K1 (0) = min E {b1 + max (0,b1 - w1) + 3max (0,w1 - b1) + K2(max(0,b1-w1)} bk=0,1,2 w1 Wir erhalten: b1 = 0: E {.} = 0,1 K2 (0) + 0,7 (3 1 + K2 (0)) + 0,2 (3 2 + K2 (0)) = 5.0 b2 = 1: E {.} = 1 + 0,1 (1 + K2 (1) + 0,7 K2 (0) + 0,2 (3 1 + K2 (0)) = 3,3 b1 = 2: E {.} = 2 + 0,1 (2 + K2 (2)) + 0,7 (1 + K2 (1)) + 0,1 K2 (0) = 3,82 K1 (0) = 3,3; 1* (0) = 1
, indem wir die oben berechneten Werte K2 (0), K2 (1), K2 (2) hierzu heranziehen. Es gilt (s. obige Funktionalgleichung!) X1 = 0. K1 (0) = min E {b1 + max (0,b1 - w1) + 3max (0,w1 - b1) + K2(max(0,b1-w1)} bk=0,1,2 w1. Wir erhalten: b1 = 0: E {.} = 0,1 K2 (0) + 0,7 (3 1 + K2 (0)) + 0,2 (3 2 + K2 (0)) = 5.0. b2 = 1: E {.} = 1 + 0,1 (1 + K2 (1) + 0,7 K2 (0) + 0,2 (3 1 + K2 (0)) = 3,3. b1 = 2: E {.} = 2 + 0,1 (2 + K2 (2)) + 0,7 (1 + K2 (1)) + 0,1 K2 (0) = 3,82. K1 (0) = 3,3; 1* (0) = 1.")
330
x1 = 1 min E {b1 + max (0, 1 + b1 - w1) + 3max (0, w1 - 1 - b1) +
+ K2 (max (0, 1 + b1 - w1))} b1 = 0 E {.} = 0,1 (1 + K2 (1)) + 0,7 K2 (0) + 0,2 (3 1 + K2 (0)) = 2,3 b1 = 1 E {.} = 1 + 0,1 (2 + K2 (2) + 0,7 (1 + K2 (1)) + 0,2 K2 (0) = 2,82 Also: K1 (1) = 2,3; 1* (1) = 0 x1 = 2 K1 (2) = E {max (0,2 - w1) + 3 max (0, w1 - 2) + K2 (max (0, 2 - w1))} = = 0,1 (2 + K2 (2) + 0,7 (1 + K2 (1) + 0,2 K2 (0) = 1,82 K1 (2) = 1,82; 1* (2) = 0
)} b1 = 0 E {.} = 0,1 (1 + K2 (1)) + 0,7 K2 (0) + 0,2 (3 1 + K2 (0)) = 2,3. b1 = 1 E {.} = 1 + 0,1 (2 + K2 (2) + 0,7 (1 + K2 (1)) + 0,2 K2 (0) = 2,82. Also: K1 (1) = 2,3; 1* (1) = 0. x1 = 2. K1 (2) = E {max (0,2 - w1) + 3 max (0, w1 - 2) + K2 (max (0, 2 - w1))} = = 0,1 (2 + K2 (2) + 0,7 (1 + K2 (1) + 0,2 K2 (0) = 1,82. K1 (2) = 1,82; 1* (2) = 0.")
331
Stufe 0: Da der Anfangsbestand 0 ist, müssen wir nun K0(0) berechnen!
X0 = 0 K0(0) = min E {b0 + max (0, b0 - w0) + 3max (0, w0 - b0) + b0=0, 1, 2 + K1 (max (0, b0 - w0)} b0 = 0 E {.} = 0,1 K1 (0) + 0,7 (3 1 + K1 (0)) + 0,1(3 2 + K1(0)) = 6,6 b0 = 1 E {.} = 1 + 0,1 (1 + K1(1)) + 0,7 K1(0) + 0,2 (3 1 + K1(0)) = 4,9 b0 = 2 E {.} = 2 + 0,1 (2 + K1(2)) + 0,7 (1 + K1(1)) + 0,2 K1(0) = 5,352 K0(0) = 4,9; 0*(0) = 1
 = min E {b0 + max (0, b0 - w0) + 3max (0, w0 - b0) + b0=0, 1, 2. + K1 (max (0, b0 - w0)} b0 = 0 E {.} = 0,1 K1 (0) + 0,7 (3 1 + K1 (0)) + 0,1(3 2 + K1(0)) = 6,6. b0 = 1 E {.} = 1 + 0,1 (1 + K1(1)) + 0,7 K1(0) + 0,2 (3 1 + K1(0)) = 4,9. b0 = 2 E {.} = 2 + 0,1 (2 + K1(2)) + 0,7 (1 + K1(1)) + 0,2 K1(0) = 5,352. K0(0) = 4,9; 0*(0) = 1.")
332
D. h. die optimale Politik besteht in der Bestellung von 1 Stück (wenn Anfangsbestand 0 ist).
Resumée: Bei stoschastischen Problemen bringt die Vorgangsweise von rückwärts (Rollback-Analyse) tatsächliche Vorteile, da das globale Optimum oft auf diese Weise ermittelbar ist. Bei deterministischen Problemen bringt dieser Typ von Vorgangsweise keinen unmittelbaren Vorteil und andere (?) Vorgangsweisen sind oft weniger rechenaufwendig (NLP, LP, Brand....(?) u.a.m.)
 tatsächliche Vorteile, da das globale Optimum oft auf diese Weise ermittelbar ist. Bei deterministischen Problemen bringt dieser Typ von Vorgangsweise keinen unmittelbaren Vorteil und andere ( ) Vorgangsweisen sind oft weniger rechenaufwendig (NLP, LP, Brand....( ) u.a.m.)")
333
Praktisch äquivalent zu folgendem Tableau: Zi = (w1, w2, w3)
Z1 = Z2 = Z27 = E(z) (0, 0, 0) (0, 0, 1). . (222) W (Z = zi) 0,001 0, ,008 a1 = (0, 0, 0) a2 = (0, 0, 1) . a27 = (222) E (Z) Bayes Gewählt wurde Bayes-Aktion! Ist allerdings die Verteilung stetig, wird die Berechnung der Bayes-Aktion auf diese Weise unmöglich! Man beachte auch den beträchtlichen Unterschied im Rechenaufwand!
 (0, 0, 0) (0, 0, 1). . (222) W (Z = zi) 0,001 0,007 0,008. a1 = (0, 0, 0) a2 = (0, 0, 1) a27 = (222) E (Z) Bayes. Gewählt wurde Bayes-Aktion! Ist allerdings die Verteilung stetig, wird die Berechnung der Bayes-Aktion auf diese Weise unmöglich! Man beachte auch den beträchtlichen Unterschied im Rechenaufwand!")
334
IX. Information und Entscheidung -
Unter besonderer Berücksichtigung Bayes‘scher Entscheidungen Unvollständige Informationen können bei Form...(?) Handlungsziel und Problem prinzipiell über beide „Koordinaten“ des Entscheidungsproblems herrschen: „Aktionsraum“ „Zustandsraum“ Entscheidungsproblem mit unvollständiger Information (Problem und Handlungsziele sind formuliert) Alternativensuchprozess Umweltsituationsfeststellungsprozess Datenpräzisierung und Rechenmodellwahl zur Präzisierung der Alternativen-konsequenzen in den Umweltsituationen Informationsaktivitäten zur Präzisierung der Eintreffenswahrscheinlichkeiten der Umweltsituationen Resultat: Entscheidungsmatrix
 Handlungsziel und Problem prinzipiell über beide „Koordinaten des Entscheidungsproblems herrschen: „Aktionsraum „Zustandsraum Entscheidungsproblem mit unvollständiger Information. (Problem und Handlungsziele sind formuliert) Alternativensuchprozess Umweltsituationsfeststellungsprozess Datenpräzisierung und Rechenmodellwahl zur Präzisierung der Alternativen-konsequenzen in den Umweltsituationen Informationsaktivitäten zur Präzisierung der Eintreffenswahrscheinlichkeiten der Umweltsituationen Resultat: Entscheidungsmatrix.")
335
1) Adaptive Modelle A) mit langer Gültigkeit der Alternative
Entscheidungsmodelle mit stochastischen Informationsbeschaffungsprozessen (mit Beschaffungskosten) Modelle zur Information über die Handlungsalternativen Modelle zur Information über die Umweltlagen Präzisierung der Daten über bekannte Alternativen Umweltlagener-mittlung (Suche) Präzisierung der Eintreffenswahr-scheinlichkeiten (-Vorstellungen) Alternativen-suche Simultane Alternativensuche und Datenpräzisierung Simultane Berücksichtigung der Suche und des Präzisierungsprozesses 1) Adaptive Modelle A) mit langer Gültigkeit der Alternative B) mit kurzer Gültigkeit der Alternative 2) Modelle mit „festen“ Verteilungen
 Modelle zur Information über die Handlungsalternativen. Modelle zur Information über die Umweltlagen. Präzisierung der Daten über bekannte Alternativen. Umweltlagener-mittlung (Suche) Präzisierung der Eintreffenswahr-scheinlichkeiten (-Vorstellungen) Alternativen-suche. Simultane Alternativensuche und Datenpräzisierung. Simultane Berücksichtigung der Suche und des Präzisierungsprozesses. 1) Adaptive Modelle A) mit langer Gültigkeit der Alternative. B) mit kurzer Gültigkeit der Alternative. 2) Modelle mit „festen Verteilungen.")
336
Alternativengütebeurteilungskriterium:
1) Beitrag zum Ausmaß der Realisierung des Handlungsziels (Nutzen) 2) Rang bei Anordnung einer (endlichen) Anzahl von Alternativen nach ihrer „Güte“. 3) Optimalitätswahrscheinlichkeit bzw. Entropie (suchtheoretische Modelle u.a.m.). 1) Entscheidungsprozesse bei einstufigen Informationsentscheidungen 2) Entscheidungsprozesse bei mehrstufigen Informationsentscheidungen Informationsbeschaffung bei Auswahl nach dem Mini-Max-Kriterium Informationsbeschaffung bei Auswahl nach dem Bayes‘schen Kriterium u.v.a.
 Beitrag zum Ausmaß der Realisierung des Handlungsziels (Nutzen) 2) Rang bei Anordnung einer (endlichen) Anzahl von Alternativen nach ihrer „Güte . 3) Optimalitätswahrscheinlichkeit bzw. Entropie (suchtheoretische Modelle u.a.m.). 1) Entscheidungsprozesse bei einstufigen Informationsentscheidungen. 2) Entscheidungsprozesse bei mehrstufigen Informationsentscheidungen. Informationsbeschaffung bei Auswahl nach dem Mini-Max-Kriterium. Informationsbeschaffung bei Auswahl nach dem Bayes‘schen Kriterium. u.v.a.")
337
Hier werde zunächst nur das Problem der Informationspräzisierung über die (voraussichtlich) vorliegende Umweltlage bei verschiedenen Entscheidungskriterien betrachtet. A) Einstufige Entscheidungsmodelle bei Informationsmöglichkeit zur Präzisierung der Kenntnisse über die Zustände a) Experimente und Aktionen - der Begriff der Entscheidungsfunktion Wir kommen nun auf den Begriff des Informationssystems zurück, wie wir ihn zu Beginn eingeführt haben. Es existiere eine Informations- beschaffungsmöglichkeit mit einem Nachrichtenraum: Y = {yi|i = 1, 2, ... k}
 Einstufige Entscheidungsmodelle bei Informationsmöglichkeit zur Präzisierung der Kenntnisse über die Zustände. a) Experimente und Aktionen - der Begriff der Entscheidungsfunktion. Wir kommen nun auf den Begriff des Informationssystems zurück, wie wir ihn zu Beginn eingeführt haben. Es existiere eine Informations- beschaffungsmöglichkeit mit einem Nachrichtenraum: Y = {yi|i = 1, 2, ... k}")
338
„Beobachten“ wir yq, so können wir eine Wahrscheinlichkeitsverteilung
„Beobachten“ wir yq, so können wir eine Wahrscheinlichkeitsverteilung {wjq|j = 1, 2, .... n} für die Zustandswahrscheinlichkeiten angeben: NACHRICHTEN Zustände y1 y yk x1 w11 w w1k x2 w21 w w2k xn wn1 wn wnk

339
Um nun das Informationsergebnis in das Entscheidungsproblem einzubeziehen, machen wir die Wahl einer Aktion vom Ergebnis des Informationsbeschaffungsprozesses abhängig: Definition: Es sei Y die Zufallsvariable mit dem Wertebereich Y = {y1, y2, ... yk}. Die Funktion d: Y A (x d(x)) heißt Entscheidungsfunktion! Bemerkung: Eine Entscheidungsfunktion ist bei endlichen Y und A einfach zu schreiben: y y yk y1 y yk d = ( ) = ( ) d(y1) d(y2) d(yn) ai1 ai aik d.h. also, liefert uns der stochastisch beeinflusste Informationsbeschaffungs-prozess die Nachricht yj, so handeln wir gemäß d(yj) = aij
) heißt Entscheidungsfunktion! Bemerkung: Eine Entscheidungsfunktion ist bei endlichen Y und A einfach zu schreiben: y1 y yk y1 y yk. d = ( ) = ( ) d(y1) d(y2) d(yn) ai1 ai aik. d.h. also, liefert uns der stochastisch beeinflusste Informationsbeschaffungs-prozess die Nachricht. yj, so handeln wir gemäß d(yj) = aij.")
340
Zustandsmenge: {Zi+1|i = 0, 1, 2, 3 Stücke sind nicht verwendbar}
(Obiges) Beispiel: Eine Sendung von 3 Stück sei angekommen, es soll beurteilt werden, ob die Sendung zurückzuweisen ist. Zustandsmenge: {Zi+1|i = 0, 1, 2, 3 Stücke sind nicht verwendbar} Informationssystem: Y = {yj+1|j = 0, 1 Stück sind schlecht in einer Zufallsstichprobe vom Umfang 1} Matrix des Informationssystems: Zufallsstichprobe vom Umfang 1 Zustände NACHRICHTEN y1 y2 Z1 1 0 Z2 2/3 1/3 Z3 1/3 2/3 Z4 0 1 i i ( ) ( ) j j W (yj+1|Zi+1) = ———– 3 ( ) 1
 Beispiel: Eine Sendung von 3 Stück sei angekommen, es soll beurteilt werden, ob die Sendung zurückzuweisen ist. Zustandsmenge: {Zi+1|i = 0, 1, 2, 3 Stücke sind nicht verwendbar} Informationssystem: Y = {yj+1|j = 0, 1 Stück sind schlecht in einer Zufallsstichprobe vom Umfang 1} Matrix des Informationssystems: Zufallsstichprobe vom Umfang 1. Zustände NACHRICHTEN. y1 y2. Z Z2 2/3 1/3. Z3 1/3 2/3. Z i 3-i. ( ) ( ) j 1-j. W (yj+1|Zi+1) = ———– 3. ( ) 1.")
341
Entscheidungsmatrix ohne Informationen mit einfachen Alternativen
Z1 Z2 Z3 Z4 Annahme d. Sendung a Ablehnung d. Sendung a Regrettabelle Z1 Z2 Z3 Z4 a a Transport: 20 Deckungsbeitrag pro Stück: 40 Kosten bei Ablehnung mit keinem mangelhaften Stück: 30 + Transport Kosten bei einem mangelhaften Stück: nur Transport mehr als einem Stück: 0

342
Entscheidungsfunktion: Es gibt |Y||A| (?) Entscheidungsfunktionen.
y1 y2 Hier (22) : d1 = ( ) (d (y0) = a0; d (y1) = a0) usw. a1 a1 d2 = ( ) a1 a2 d3 = ( ) a2 a1 d4 = ( ) a2 a2
 : d1 = ( ) (d (y0) = a0; d (y1) = a0) usw. a1 a1. d2 = ( ) a1 a2. d3 = ( ) a2 a1. d4 = ( ) a2 a2.")
343
Wir ersetzen nun das einfache Entscheidungsproblem ohne Informationen durch folgendes Entscheidungsproblem mit Informationen (nach Umindizierung!): Wir nennen diese Tafel die Entscheidungstabelle für Entscheidungs-funktionen.

344
Definition: Mit bezeichnen wir die Menge aller Entscheidungsfunktionen. Es sei d eine Entscheidungsfunktion; dann gelte für den Nutzen je Entscheidungsfunktion d und Zustand Zi: u (d, zi) = u (d (y1), zi) W (y1| zi) + u (d (y2) , zi) W (y2| Zi) + ..... u (d (yk), zi) W (yk| zi) = k = u (d (yi), zi) W (yj | zi) j=1 Analog gilt in einer Regrettafel für die Regretwerte je Entscheidungsfunktion (d ): R (d, zi) = r (d (yj), zi) W (yj | zi)
 = u (d (y1), zi) W (y1| zi) + u (d (y2) , zi) W (y2| Zi) u (d (yk), zi) W (yk| zi) = k. = u (d (yi), zi) W (yj | zi) j=1. Analog gilt in einer Regrettafel für die Regretwerte je Entscheidungsfunktion (d ): R (d, zi) = r (d (yj), zi) W (yj | zi)")
345
Beispiel: Entscheidungstabelle der Entscheidungsfunktionen
Zustände Entscheidungsfunktion Z1 Z2 Z3 Z4 d d /3 20/3 -20 d /3 40/3 0 d u (d1, Z1) = u (d (y1), Z1) W (y1 | Z1) + u (d (y2), Z1) W (y2 | Z1) = = u (a1, Z1) W (y1 | Z1) + u (a1, Z1) W (y2 | Z1) = = 100 = 100 u (d2 Z1) = u (a1, Z1) W (y1 | Z1) + u (a2, Z1) W (y2 | Z1) = = 100 = 100 d1 dominiert d2 streng d3 dominiert d4 streng ... usw.
 = u (d (y1), Z1) W (y1 | Z1) + u (d (y2), Z1) W (y2 | Z1) = = u (a1, Z1) W (y1 | Z1) + u (a1, Z1) W (y2 | Z1) = = 100 = 100. u (d2 Z1) = u (a1, Z1) W (y1 | Z1) + u (a2, Z1) W (y2 | Z1) = = 100 = 100. d1 dominiert. d2 streng. d3 dominiert. d4 streng. ... usw.")
346
Bemerkung:. Das einfache Problem ohne Informationen ist auch in
Bemerkung: Das einfache Problem ohne Informationen ist auch in der Entscheidungsfunktionstabelle enthalten: d1, d4! (= konstante Entscheidungsfunktionen!) Satz: Zur Bestimmung der Regret-Tafel genügt es, bei ermittelter Nutzentafel die Regrettafel aus der Entscheidungsfunktionstafel im üblichen Weg abzuleiten. Beweis: Ferschl S. 104, 105.
 Satz: Zur Bestimmung der Regret-Tafel genügt es, bei ermittelter Nutzentafel die Regrettafel aus. der Entscheidungsfunktionstafel im üblichen Weg abzuleiten. Beweis: Ferschl S. 104, 105.")
347
Beispiel: Entscheidungsfunktionsregrettabelle
Kann aus einfacher Aktionsregrettabelle oder aus Entscheidungsfunktions-nutzentabelle ermittelt werden! Z1 Z2 Z3 Z4 d d2 0 80/3 40/3 20 d /3 20/3 0 d

348
b) Gemischte (randomisierte) Entscheidungsfunktionen
Ganz analog zum einfachen Entscheidungsproblem kann man beim Entscheidungsfunktionsproblem gemischte Entscheidungsfunktionen d* einführen: d1 d dmk d* = ( ) p1 p pmk Vorgangsweise bei Wahl einer Aktion: I) Durchführung eines Zufallsexperiments, welches uns mit den Wahrscheinlichkeiten p1, p2, ... pmk die Indizes 1, 2, ... mk liefert; z.B. „s“. II) Durchführung des Informationsbeschaffungsprozesses mit dem Ausgang yj. Resultat: Wahl der durch ds(yj) bestimmten Aktion.
 p1 p2 ... pmk. Vorgangsweise bei Wahl einer Aktion: I) Durchführung eines Zufallsexperiments, welches uns mit den Wahrscheinlichkeiten p1, p2, ... pmk die Indizes 1, 2, ... mk liefert; z.B. „s . II) Durchführung des Informationsbeschaffungsprozesses mit dem Ausgang yj. Resultat: Wahl der durch ds(yj) bestimmten Aktion.")
349
Beispiel: Z1 Z2 Z3 Z4 d‘ d‘ /3 40/3 0 Es gelte für die gemischte Entscheidungsfunktion d*: d‘1, d‘2 d* : ( ) 1/6 5/6 Ausführung: 1) Wir werfen einen Würfel; werfen wir eine 1, so gelte s = 1; sonst gelte s = 2. 2) Wir „ziehen“ ein Element aus der Sendung (Zufallsstichprobe). Dieses Element sei fehlerhaft. Folglich: zu realisierende Aktion d‘2 (y2) = a1 Ablehnung.
 1/6 5/6. Ausführung: 1) Wir werfen einen Würfel; werfen wir eine 1, so gelte s = 1; sonst gelte s = 2. 2) Wir „ziehen ein Element aus der Sendung (Zufallsstichprobe). Dieses Element sei fehlerhaft. Folglich: zu realisierende Aktion d‘2 (y2) = a1 Ablehnung.")
350
Die Frage, ob eine gemischte Entscheidungsfunktion zur Effizienzerhöhung beitragen kann, kann ganz analog zur Frage bei einfachen Aktionen beantwortet werden. Bei allen Entscheidungsregeln, die die Maximin-Regel bzw. die Minimax-Regel verwenden, kann eine solche Verbesserung erfolgen. Entscheidungs- Zustände funktion x1 x2 d d2 0,5 0,6 d3 9,5 29,4 d Beispiel:

351
d1 d2 d3 d4 d‘ = W3 d3 + W4 d4 = ( ) (W4 = 1 - W3) W3 W4 Hier erhalten: w (9,5 29,4) + (1 - w) (10 0) = (b b); also 9,5w + 10 (1 - w) = 29,4w w 1/3
 + (1 - w) (10 0) = (b b); also 9,5w + 10 (1 - w) = 29,4w. w 1/3.")
352
c) Bayes-Entscheidungsfunktionen
Grundannahmen: 1) Existenz eines Vektors Z1 Z Zn ( ) (Wi = 1) W1 W Wn Von Wahrscheinlichkeiten für das Eintreffen der Zustände Zi. 2) Existenz einer Informationsquelle mit dem Informationsraum (Nachrichtenraum) Y = {y1, y2, .... yk} Für die Bayes-Entscheidungsfunktion gilt analog zur Problemstellung ohne Information: n (d) = u (d, xj) w (xj) j=1
 Existenz eines Vektors. Z1 Z Zn. ( ) (Wi = 1) W1 W Wn. Von Wahrscheinlichkeiten für das Eintreffen der Zustände Zi. 2) Existenz einer Informationsquelle mit dem Informationsraum (Nachrichtenraum) Y = {y1, y2, .... yk} Für die Bayes-Entscheidungsfunktion gilt analog zur Problemstellung ohne Information: n. (d) = u (d, xj) w (xj) j=1.")
353
(d) = [ u (d (ys), xj) W (ys|xj)] W (xj)) = j=1 s=1 k n
Die Besonderheit bei Bayes-Entscheidungsfunktionen liegt nun in dem Umstand, dass man nicht für alle Mk Entscheidungsfunktionen d den Wert (d) errechnen muss, sondern sozusagen vom „Problem ohne Information“ unmittelbar die Lösung des Problems mit Information ermitteln kann; es gilt nämlich: n n (d) = [ u (d (ys), xj) W (ys|xj)] W (xj)) = j=1 s=1 k n = [ u (d (ys), xj) W (ys|xj) W (xj)] = s=1 j=1 k n = (d (ys)) mit s (d (ys)) = u (d (ys), xj) W (ys|xj) W (xj)) s= j=1 (Vertauschen der Summation)
![ (d) = [ u (d (ys), xj) W (ys|xj)] W (xj)) = j=1 s=1 k n](http://slideplayer.org/slide/11848645/66/images/353/%EF%81%AA+%28d%29+%3D+%EF%83%A5+%5B%EF%83%A5+u+%28d+%28ys%29%2C+xj%29+W+%28ys%7Cxj%29%5D+W+%28xj%29%29+%3D+j%3D1+s%3D1+k+n.jpg "Die Besonderheit bei Bayes-Entscheidungsfunktionen liegt nun in dem Umstand, dass man nicht für alle Mk Entscheidungsfunktionen d den Wert (d) errechnen muss, sondern sozusagen vom „Problem ohne Information unmittelbar die Lösung des Problems mit Information ermitteln kann; es gilt nämlich: n n. (d) = [ u (d (ys), xj) W (ys|xj)] W (xj)) = j=1 s=1. k n. = [ u (d (ys), xj) W (ys|xj) W (xj)] = s=1 j=1. k n. = (d (ys)) mit s (d (ys)) = u (d (ys), xj) W (ys|xj) W (xj)) s=1 j=1. (Vertauschen der Summation)")
354
= max (1 (d (y1)) + ..... + k (d(yk))
Da die Bayes-Entscheidungsfunktion B das Maximum aus { (d)} ist, können wir schreiben: B = max { (d)} = d = max (1 (d (y1)) k (d(yk)) = max 1 (d (y1) + max 2 (d (y2)) max k (d (yk)) d(y1)A d(y2)A d(yk)A Daher können wir schreiben: Die Bayes-Entscheidungsfunktion zur Bewertung W (x1), W (x2), ... W (xn) wird bestimmt, indem man als Funktionswert d (ys) eine Bayes-Aktion im einfachen Entscheidungsproblem jedoch mit der Bewertung W (Ys | X1) W (X1), ... , W (Ys | Xn) W (Xn) heranzieht.
} ist, können wir schreiben: B = max { (d)} = d = max (1 (d (y1)) k (d(yk)) = max 1 (d (y1) + max 2 (d (y2)) max k (d (yk)) d(y1)A d(y2)A d(yk)A. Daher können wir schreiben: Die Bayes-Entscheidungsfunktion zur Bewertung W (x1), W (x2), ... W (xn) wird bestimmt, indem man als Funktionswert d (ys) eine Bayes-Aktion im einfachen Entscheidungsproblem jedoch mit der Bewertung. W (Ys | X1) W (X1), ... , W (Ys | Xn) W (Xn) heranzieht.")
355
Nun folgt aus n max s (d (ys)) = u (d (ys), xj) W (ys | xj) W (xj), d(ys)A j=1 dass die Maxima gegenüber einer Normierung mit jeweils (d.h. für jedes ys) einem Wert W (ys) = W (ys| xj) W (xj) j=1 unbeeinflusst bleiben: max s (d (ys)) max (d (ys)) d(ys)A = d(ys)A W(ys)
 einem Wert. W (ys) = W (ys| xj) W (xj) j=1. unbeeinflusst bleiben: max s (d (ys)) max (d (ys)) d(ys)A = d(ys)A. W(ys)")
356
s(d (ys) n W (ys|xj) W (xj) ‘s (d (ys)) = = u (d (ys), xj) =
Nun gilt: s(d (ys) n W (ys|xj) W (xj) ‘s (d (ys)) = = u (d (ys), xj) = W (ys) j= W (ys|xj) W (xj) n = u (d (ys) xj) W (xj | ys) j=1 W (xj) = a priori Zustandswahrscheinlichkeit W (ys | xj) = Verlässlichkeit des unvollkommenen Informationssystems W (ys | xj) W (xj) a posteriori Wahrscheinlichkeit für den W (xj | ys) = = W (ys | xj) W (xj) Zustand xj nach Information ys (Bayes‘scher Satz) n j=1 a posteriori Wahrscheinlichkeiten! n j=1
 n W (ys|xj) W (xj) ‘s (d (ys)) = = u (d (ys), xj) = W (ys) j=1 W (ys|xj) W (xj) n. = u (d (ys) xj) W (xj | ys) j=1. W (xj) = a priori Zustandswahrscheinlichkeit. W (ys | xj) = Verlässlichkeit des unvollkommenen Informationssystems. W (ys | xj) W (xj) a posteriori Wahrscheinlichkeit für den. W (xj | ys) = = W (ys | xj) W (xj) Zustand xj nach Information ys. (Bayes‘scher Satz) n. j=1. a posteriori Wahrscheinlichkeiten! n. j=1.")
357
Hauptsatz der Bayes-Entscheidungstheorie:
Eine optimale Entscheidungsfunktion d* erhält man, indem man für jede Nachricht ys Y das modifizierte Entscheidungsproblem mit den Zustandswahrscheinlichkeiten W (x1 | ys), W (x2 | ys), ... , W (xn | ys) für jedes ys (s = 1, 2, ... k) löst. Die zugehörige optimale Aktion aus A ist das Bild d (ys) in der gesuchten Bayes Entscheidungsfunktion zur a priori Bewertung W (x1), W (x2), ... W (xn) bei dem unvollkommenen Informationssystem charakterisiert durch {W (ys | xj) | j = 1, 2, ... n; s = 1, 2, ... k}.
, W (x2 | ys), ... , W (xn | ys) für jedes ys (s = 1, 2, ... k) löst. Die zugehörige optimale Aktion aus A ist das Bild d (ys) in der gesuchten Bayes Entscheidungsfunktion zur a priori Bewertung W (x1), W (x2), ... W (xn) bei dem unvollkommenen Informationssystem charakterisiert durch {W (ys | xj) | j = 1, 2, ... n; s = 1, 2, ... k}.")
358
Beispiel: Es gelte: W (x1) = 0,7 W (x2) = 0,3 Matrix des Nutzens x1 x2 a1 0 10 a2 2 7 a3 8 3 unvollkommenes Informationssystem: (W (ys | xj) y1 0,7 0,2 y2 0,2 0,3 y3 0,1 0,5 a priori Bewertung
 y1 0,7 0,2. y2 0,2 0,3. y3 0,1 0,5. a priori Bewertung.")
359
A posteriori Zustandsverteilungen (normiert)
(W (xj | ys)): x1 x2 y1 0,89 0,11 y2 0,61 0,39 y3 0,32 0,68
): x1 x2. y1 0,89 0,11. y2 0,61 0,39. y3 0,32 0,68.")
360
{W (xj | ys)} W (ys) = W (ys | xj) W (xj) n W (ys | xj) W (xj)
Ermittlung der Bayes-Entscheidungsregel mittels a posteriori Verteilung {W (xj | ys)} W (ys) = W (ys | xj) W (xj) n W (ys | xj) W (xj) x1 x2 j=1 x1 x2 y1 0,89 0,11 0,55 y1 0,49 0,06 y2 0,61 0,39 0,23 y2 0,14 0,09 y3 0,32 0,68 0,22 y3 0,07 0,15 x1 x2 a1 0 10 a2 2 7 a3 8 3 Mittels der (nicht normierten) Nachrichtenwahrscheinlichkeiten 0,49/0,55 W(y3|x2)w(x2) W(y3|x1).W(x1) {E (u(ai, ys))} y y y3 a1 1,1 3,9 6,8 - max ‘(d(y3) a2 2,55 3,95 5, d*=(d(y1)d(y2)d(y3)= a3 7,45 6,05 4, (a3 a2 a1) y y y3 a ,6 0, ,5 - max (d(y3) a2 1,4 0,91 1,19 a3 4,1 1,49 1,01
} W (ys) = W (ys | xj) W (xj) n. W (ys | xj) W (xj) x1 x2 j=1 x1 x2. y1 0,89 0,11 0,55 y1 0,49 0,06. y2 0,61 0,39 0,23 y2 0,14 0,09. y3 0,32 0,68 0,22 y3 0,07 0,15. x1 x2. a a a Mittels der (nicht normierten) Nachrichtenwahrscheinlichkeiten. 0,49/0,55. W(y3|x2)w(x2) W(y3|x1).W(x1) {E (u(ai, ys))} y1 y2 y3. a1 1,1 3,9 6,8 - max ‘(d(y3) a2 2,55 3,95 5,4 d*=(d(y1)d(y2)d(y3)= a3 7,45 6,05 4,6 (a3 a2 a1) y1 y2 y3. a1 0,6 0,9 1,5 - max (d(y3) a2 1,4 0,91 1,19. a3 4,1 1,49 1,01.")
361
Wert der optimalen Bayes‘schen Entscheidungsfunktion daher:
W (y1) Eu (a3, y1) + W (y2) Eu (a3, y2) + W (y3) Eu (a1, y3) = 7,45 0,55 + 0,23 6,05 + 0,22 6,8 = 6,985 (= 4,1 + 1,39 + 1,5!) Vergleichen wir diesen Wert mit dem Wert der Bayes-Entscheidung ohne Inanspruchnahme des Informationssystems zur a priori Bewertung (0,7 0,3), wo erhalten wir: x1 x2 (ai) a a ,5 a ,5 - Bayes-Wert
 Eu (a3, y1) + W (y2) Eu (a3, y2) + W (y3) Eu (a1, y3) = 7,45 0,55 + 0,23 6,05 + 0,22 6,8 = 6,985 (= 4,1 + 1,39 + 1,5!) Vergleichen wir diesen Wert mit dem Wert der Bayes-Entscheidung ohne Inanspruchnahme des Informationssystems zur a priori Bewertung (0,7 0,3), wo erhalten wir: x1 x2 (ai) a a ,5. a ,5 - Bayes-Wert.")
362
Wert des Informationssystems in dieser Entscheidung, d. h
Wert des Informationssystems in dieser Entscheidung, d.h. Wert einer Informationsbeschaffung beträgt bei GELD als Konsequenzen oij und LINEARER Nutzenfunktion: 6, ,5 = 0,485! Bemerkung: Bei statistischen Problemen spricht man meist von Zufallsexperimenten oder Stichproben statt von Informationssystemen.

363
d) Der Informationswert eines Informationssystems
Definition: Der Wert, der durch ein Informationssystem (Zufallsexperiment) ermittelten Information ist gleich dem maximalen Ertrag im Entscheidungsproblem aller mittels des Informationssystems konstruierten Entscheidungsfunktionen abzüglich des maximalen Ertrags bei Entscheidung ohne Informationseinholung! Satz: Der Wert der durch ein Informationssystem (Zufallsexperiment) vermittelten Information ist bei den obigen Entscheidungsregeln (Bayes-Regel Maximin-Regel Optimismus-Pessimismus-Regel Hodges-Lehmann-Regel und den damit zusammenhängenden Regeln) NICHT NEGATIV ! Beweis: S. Ferschl., S. 120.
 ermittelten Information ist gleich dem maximalen Ertrag im Entscheidungsproblem aller mittels des Informationssystems konstruierten Entscheidungsfunktionen abzüglich des maximalen Ertrags bei Entscheidung ohne Informationseinholung! Satz: Der Wert der durch ein Informationssystem (Zufallsexperiment) vermittelten Information ist bei den obigen Entscheidungsregeln. (Bayes-Regel. Maximin-Regel. Optimismus-Pessimismus-Regel. Hodges-Lehmann-Regel. und den damit zusammenhängenden Regeln) NICHT NEGATIV ! Beweis: S. Ferschl., S")
364
d1) Der Wert vollständiger Information (perfektes Informationssystem)
Der vollständigen Information entspricht ein besonders einfaches Informationssystem y: y1 y yk z z zn Die Frage nach der Entscheidungsregel d0 = (d (y1) d (y2) ... d (yk), welche die optimale Regel darstellt, ist für jede Entscheidungsregel getrennt zu beantworten. Der Wert vollständiger Information ergibt sich aufgrund folgender Rechnung: Uopt (d0, Z) : = Wert der opt. Entscheidungsregel mit Information Uopt (a0, Z) : = Wert der opt. Aktionswahl (ohne Information) WVI = Wert vollständiger Information
 d (y2) ... d (yk), welche die optimale Regel darstellt, ist für jede Entscheidungsregel getrennt zu beantworten. Der Wert vollständiger Information ergibt sich aufgrund folgender Rechnung: Uopt (d0, Z) : = Wert der opt. Entscheidungsregel mit Information. Uopt (a0, Z) : = Wert der opt. Aktionswahl (ohne Information) WVI = Wert vollständiger Information.")
365
). Der Wert vollständiger Information bei Verwendung der
) Der Wert vollständiger Information bei Verwendung der Maximin-Entscheidungsregel Man wird bei der Information xi jene Aktion wählen, die den Nutzen maximiert, also das Spaltenmaximum im einfachen Tableau o. inf. Beispiel: es gelte Z1 Z2 Minima Informationssystem a y1 y2 a max z1 1 0 a z2 0 1 Maxima y y2 d0 = ( ) a1 a2 Uopt (d0, Z) = Minimum der Spaltenmaxima = 20 Uopt (a0, Z) = Maximum der Zeilenminima = 10 WVI = = 10
 Der Wert vollständiger Information bei Verwendung der Maximin-Entscheidungsregel. Man wird bei der Information xi jene Aktion wählen, die den Nutzen maximiert, also das Spaltenmaximum im einfachen Tableau o. inf. Beispiel: es gelte. Z1 Z2 Minima Informationssystem. a y1 y2. a max z a z Maxima y1 y2. d0 = ( ) a1 a2. Uopt (d0, Z) = Minimum der Spaltenmaxima = 20. Uopt (a0, Z) = Maximum der Zeilenminima = 10. WVI = = 10.")
366
Bemerkung:. Der Wert vollständiger Information ist offenbar genau
Bemerkung: Der Wert vollständiger Information ist offenbar genau dann gleich Null, wenn gilt: min max u (ai, zj) = max min u (ai, zj) j i i j Ein derartiger Punkt u (ai, zj) heißt auch Sattelpunkt der Matrix (2-Personen-Spiele) (falls er existiert!) ) Der Wert vollständiger Information im Falle der Minimax-Regret-Regel Beispiel: Z1 Z2 Regrettafel Z1 Z2 Minimax ? a a a a a a Vollständige Information: man weiß Zustand M = min 14 also: WVI = M (=14) (Regret-Wert der Regrettafel 0, Information)
 = max min u (ai, zj) j i i j. Ein derartiger Punkt u (ai, zj) heißt auch Sattelpunkt der Matrix (2-Personen-Spiele) (falls er existiert!) ) Der Wert vollständiger Information im Falle der Minimax-Regret-Regel. Beispiel: Z1 Z2 Regrettafel Z1 Z2 Minimax a a a a a a Vollständige Information: man weiß Zustand M = min 14. also: WVI = M (=14) (Regret-Wert der Regrettafel 0, Information)")
367
) Der Wert vollständiger Information bei Verwendung der Bayes-Regel
Vorgegeben ist der a priori Wahrscheinlichkeitsvektor (W (Z = z1) W (Z = z2), .... W (Z = zn)) n ( W (Z = zi) = 1). i=1 Nun gilt für das Problem ohne Information EWOI = max W (Z = zi) uij = max (ai) (i = 1, 2, ... m) Für das Entscheidungsproblem mit perfekter Information gilt: EWPI = W (Z = zi) max uij = i
 W (Z = z2), .... W (Z = zn)) n. ( W (Z = zi) = 1). i=1. Nun gilt für das Problem ohne Information. EWOI = max W (Z = zi) uij = max (ai) (i = 1, 2, ... m) Für das Entscheidungsproblem mit perfekter Information gilt: EWPI = W (Z = zi) max uij = i.")
368
EWVI = W (Z = zj) max uij - max W (Z = zj) uij
Der Erwartungswert perfekter Information ergibt sich aus der Differenz: EWPI EWOI EWVI = W (Z = zj) max uij - max W (Z = zj) uij i i = min [ W (Z = zj) (0i - uij)] i n = min W (Z = zj) sij ! I j=1 D. h. der Wert der perfekten Information ist gleich dem Bayes-Wert der zugehörigen Regrettafel. Bemerkung: In obiger Darstellung wird von dem erwarteten Gewinn perfekter Information ausgegangen. Es kann durchaus sein, dass der TATSÄCHLICHE Wert der Information über einem Zustand zj der Wert der Information KLEINER oder größer als EWVI ist. 0i
 max uij - max W (Z = zj) uij. i i. = min [ W (Z = zj) (0i - uij)] i. n. = min W (Z = zj) sij ! I j=1. D. h. der Wert der perfekten Information ist gleich dem. Bayes-Wert der zugehörigen Regrettafel. Bemerkung: In obiger Darstellung wird von dem erwarteten Gewinn perfekter Information ausgegangen. Es kann durchaus sein, dass der TATSÄCHLICHE Wert der Information über einem Zustand zj der Wert der Information KLEINER oder größer als EWVI ist. 0i.")
Ähnliche Präsentationen
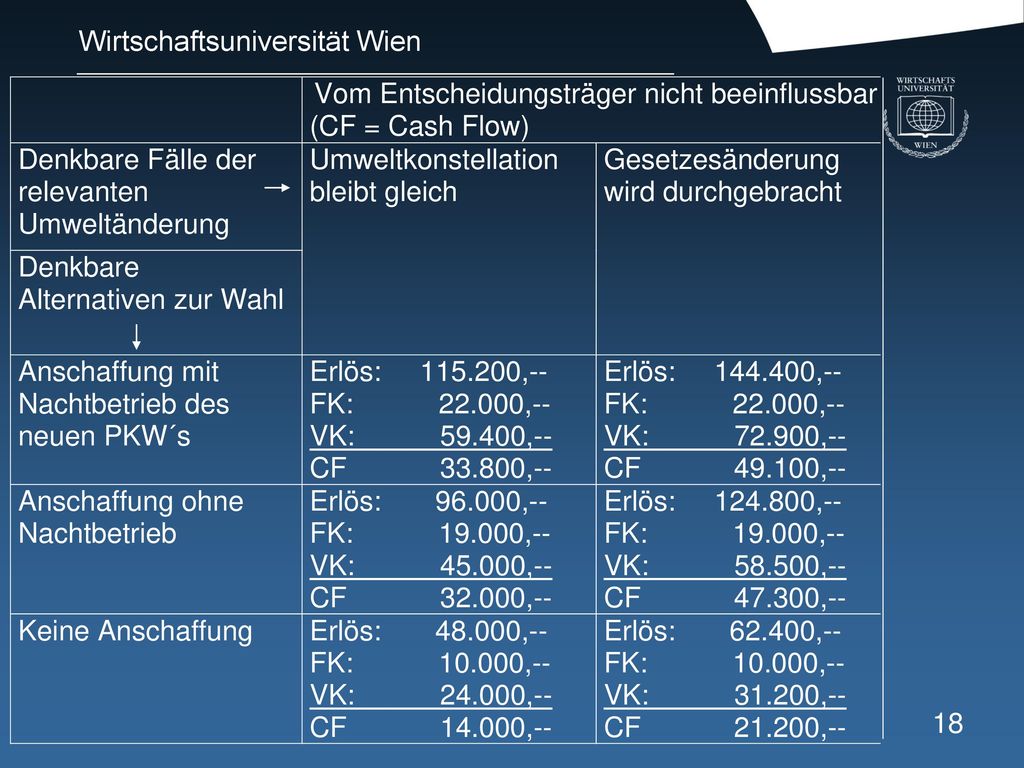

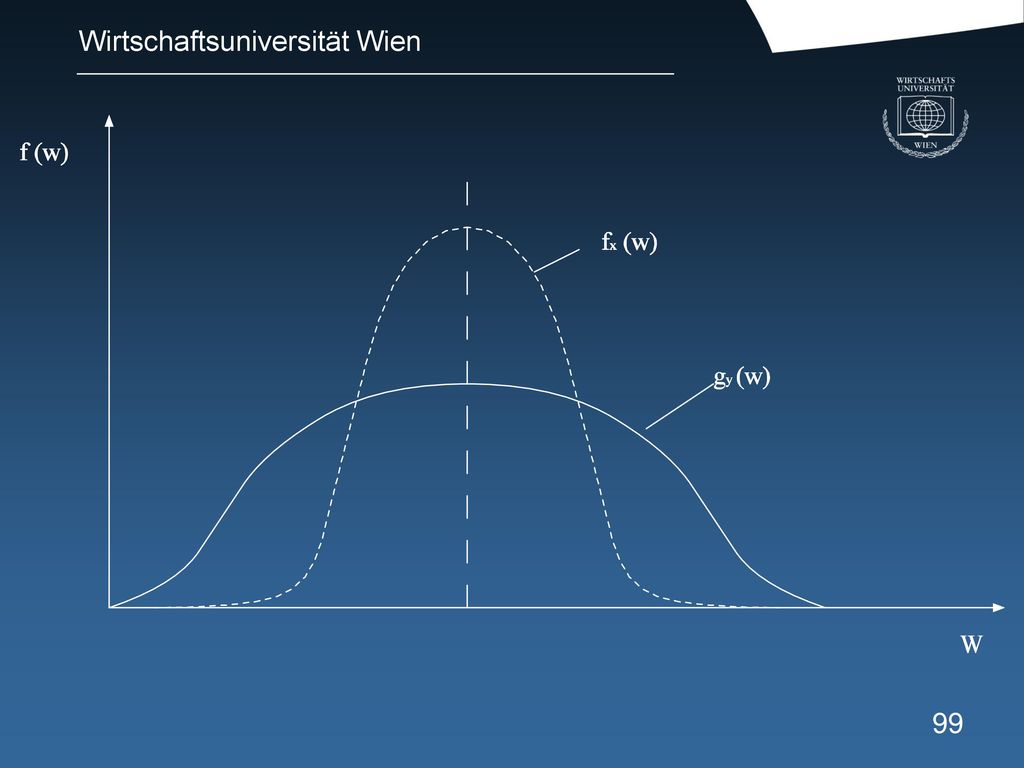



![Definition [1]: Sei S eine endliche Menge und sei p eine Abbildung von S in die positiven reellen Zahlen Für einen Teilmenge ES von S sei p definiert.](/1/209241/big_thumb.jpg "Definition [1]: Sei S eine endliche Menge und sei p eine Abbildung von S in die positiven reellen Zahlen Für einen Teilmenge ES von S sei p definiert.>")
 auf.>")


 Algorithmen hängt von gewissen zufälligen Ereignissen ab (Beispiel Quicksort). Um die Laufzeiten dieser.>")


>")

>")


 berechenbar? Intuitiv: Wenn es einen Algorithmus gibt, der sie berechnet! Was heißt,>")



 Prof. Dr. Th. Ottmann.>")
 Tobias Lauer.>")
 Prof. Dr. Th. Ottmann.>")