Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
MathNet a network for mathematicians Judith Plümer Universität Osnabrück Judith.Pluemer@uos.de Judith Plümer Universität Osnabrück Judith.Pluemer@uos.de

2
28.05.01Oldenburg2 Inhalt Problemstellung Math-Net Preprints organizing WWW servers (the MathNet Page) personal homepages weiterführende Projekte CARMEN Replication of Services
 personal homepages weiterführende Projekte CARMEN Replication of Services")
3
28.05.01Oldenburg3 Probleme... im Bereich elektronischer Information und Kommunikation jeder Fachbereich bietet Informationen an: Liste von Mitarbeitern Publikationen Vorlesungsmaterial Mensaplan wie findet man gezielt Information? (Alta Vista)
.")
4
erster Lösungsansatz (1994) Sensitive map der mathematischen Fachbereiche in Deutschland
 Sensitive map der mathematischen Fachbereiche in Deutschland")
5
28.05.01Oldenburg5 Sensitive map geographische Strukturierung sinnvoller wäre eine Strukturierung nach Dokumenttypen oder Themengebieten

6
28.05.01Oldenburg6 Ein Lösungsansatz (1997) Aus der Sicht eines Mathematikers: Math-Net von Nutzern betrieben Strukturierung mathematischer Information Komplettierung elektronischer Information Angebot von Retrieval Mechanismen Angebot von Navigationswerkzeugen nationales Projekt / weltweite Initiative
 Aus der Sicht eines Mathematikers: Math-Net von Nutzern betrieben Strukturierung mathematischer Information Komplettierung elektronischer Information Angebot von Retrieval Mechanismen Angebot von Navigationswerkzeugen nationales Projekt / weltweite Initiative")
7
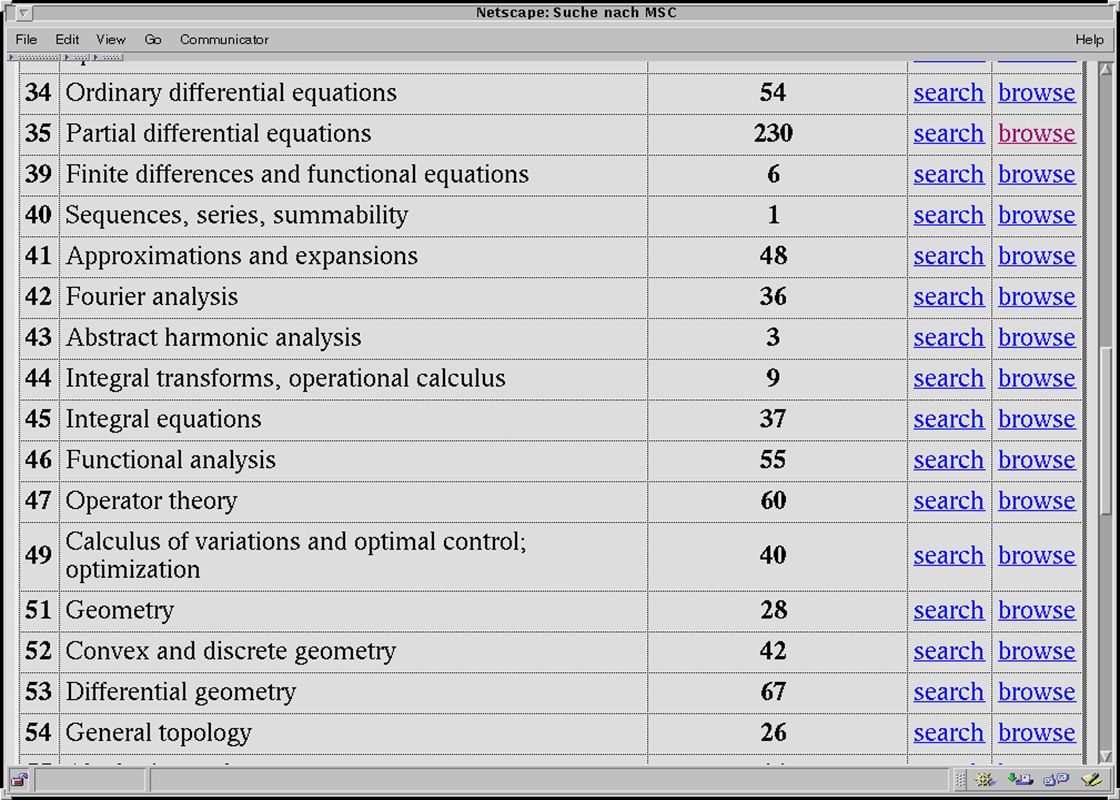
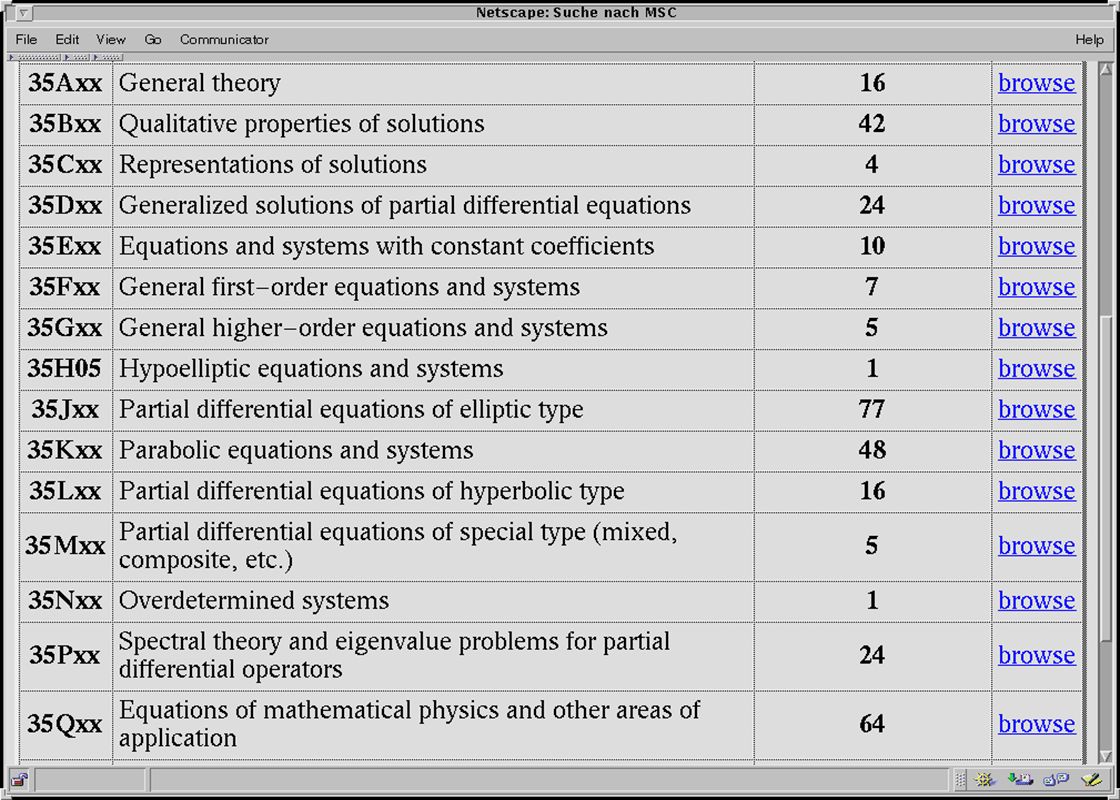
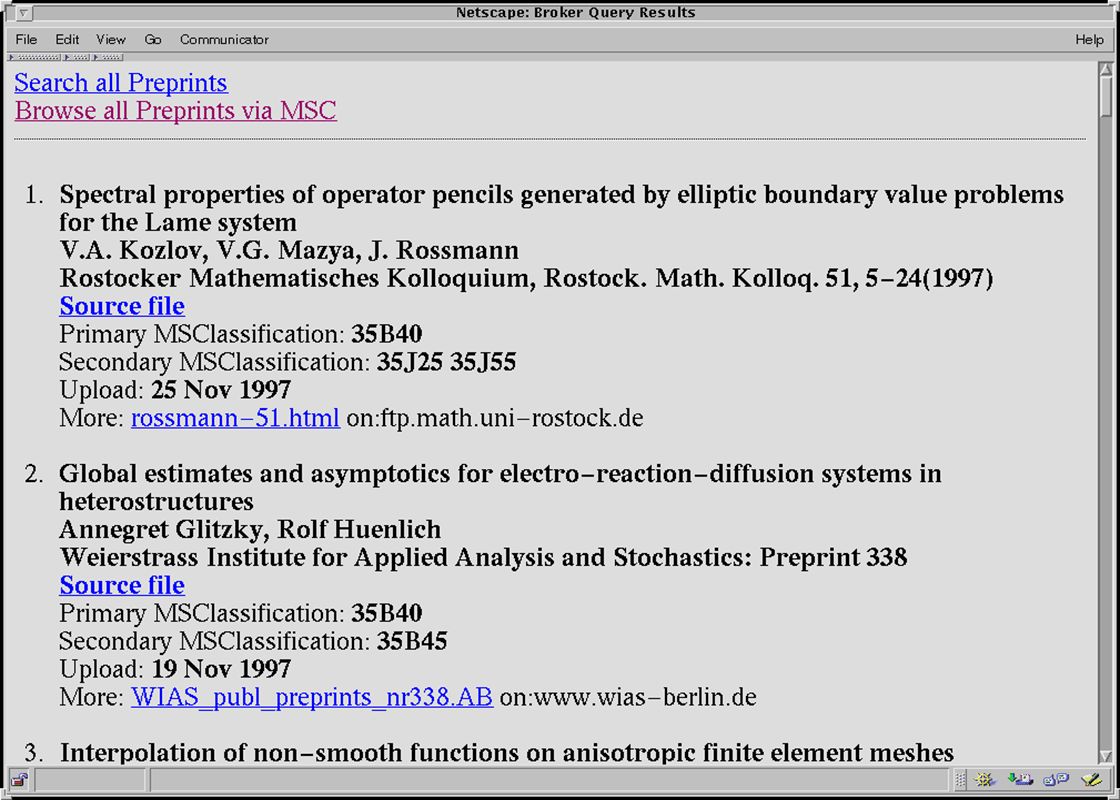
28.05.01Oldenburg7 MPRESS ein Beispiel für einen Math-Net Dienst Topology Atlas Preprints von WWW Servern Deutschlands Frankreich Österreich Fachbereiche in Europa LANL Brasilien

8
The Mathematics PREprint Search System MPRESS MathNet.preprints

9
28.05.01Oldenburg9 Technische Basis Software Harvest Broker Komponente Replicator Komponente Gatherer Komponente http://www.tardis.ed.uk/harvest/ lauffähig unter UNIX / Linux (Variante: Netscape Compass Server)
")
10
GET Doc 1 http – protocol Gatherer Doc 1 HRef Homepage einer Serie Doc 2 HRef Titelseite eines Artikels Doc 3 HRef Volltext eines Artikels Essence Docs Broker SOIFs

12
Volltextsuche liefert unscharfe Ergebnisse

13
28.05.01Oldenburg13 Suche in festen Datenfeldern bzw. Suche in Metadaten: Autor Titel Keywords Klassifikation (MSC) Datum
 Datum.")
14
28.05.01Oldenburg14

15
28.05.01Oldenburg15

19
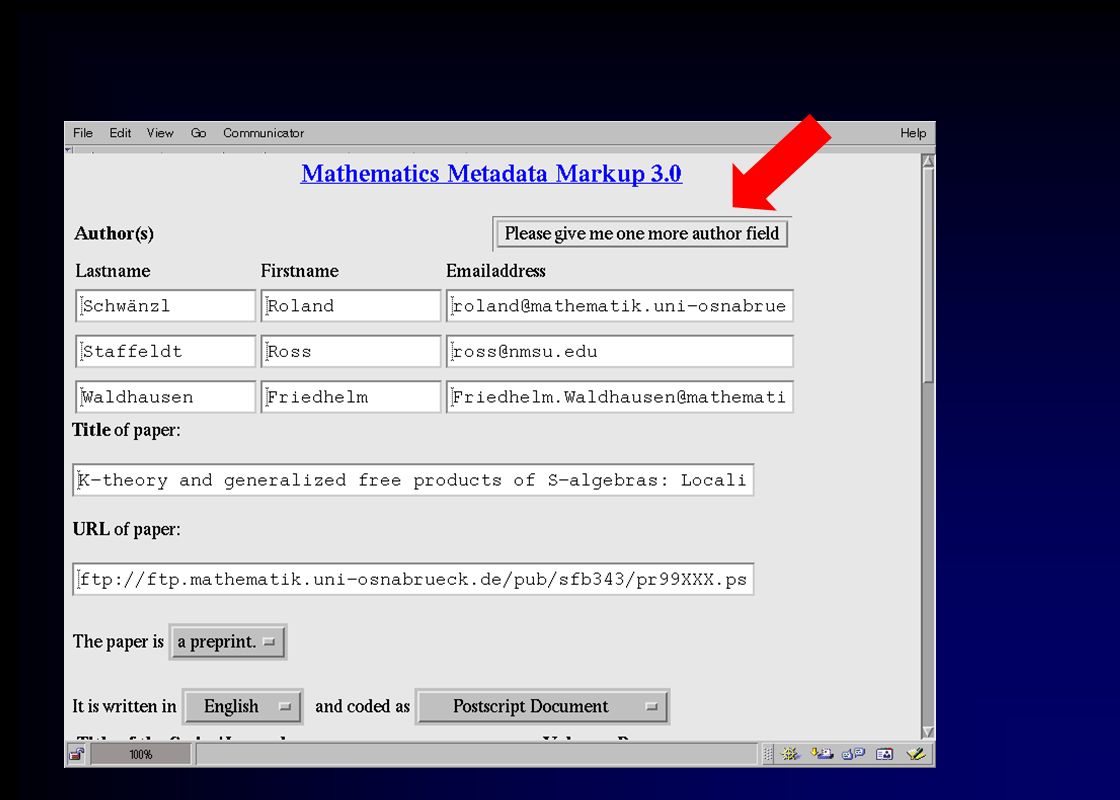
28.05.01Oldenburg19 Wer erstellt die Metadaten? Traditionell werden Metadaten von Bibliothekaren oder Dokumentaren erstellt: braucht Zeit kostet Geld verlangt hohe, spezifische Fachkompetenz ist also unrealistisch bleibt der Autor des Artikels selbst

20
Autoren kennen sich häufig nicht mit Datenformaten aus

22
19D10

24
28.05.01Oldenburg24 Kodierung der Metadaten Metadaten werden im Header einer HTML-Datei gespeichert. Erwin Mustermann Theorems on Potatoes http://www.here/ToP/ DC.Creator.Personalname DC.Title DC.Identifier <META NAME=„ “> CONTENT=„“> <META NAME=„“> CONTENT=„“> <META NAME=„ CONTENT=„ “>

25
28.05.01Oldenburg25 Speicherung durch Harvest (SOIF). Erwin Mustermann DC.Creator.Personalname <META NAME=„ “> CONTENT=„“> Theorems on Potatoes DC.Title <META NAME=„“> CONTENT=„“> dc.creator.personalname{16}: Erwin Mustermann dc.title{20}: Theorems on Potatoes

26
28.05.01Oldenburg26 Dublin Core Weltweite Initiative von Bibliothekaren und Wissenschaftlern, die 1994 bei OCLC, Dublin Ohio gegründet wurde Ziel ist es eine Klassifikation zu definieren, die inhaltsbezogen ist nutzbar ist, sowohl für Bibliotheken, als auch für Internetdokumente brauchbar für Internet Search Engines unabhängig von einer speziellen Kodierung

27
Weitere Anwendungen und Dienste in Math-Net

28
28.05.01Oldenburg28

29
28.05.01Oldenburg29

30
28.05.01Oldenburg30

31
28.05.01Oldenburg31

32
28.05.01Oldenburg32...soweit die Geschichte All diese Aktivitäten wurden betrieben vom Fachbereich Mathematik/Informatik der Universität Osnabrück. Gründung des Instituts für wissenschaftliche Information (iwi) Studiengang Information Engineering
 Studiengang Information Engineering.")
33
28.05.01Oldenburg33 iwi Mitglieder: persönliche Mitglieder institutionelle Mitglieder Informationszentrum Sozialwissenschaften, Bonn Konrad-Zuse-Zentrum Berlin Staats- und Universitätsbibliothek Göttingen European Mathematical Union Zusammenarbeit mit Die Deutsche Bibliothek Frankfurt International Mathematical Union

34
28.05.01Oldenburg34 iwi Ziele des gemeinnützigen Vereins: Konzeption von nutzerzentrierten Systemen für Information und Kommunikation (IuK) in den Wissenschaften, Entwicklung geeigneter Werkzeuge ausgewählte Informationsdienste zu entwickeln und zu betreiben auch in Zusammenarbeit mit Bibliotheken etc. sich als stabiler und zuverlässiger Partner in die internationale, wissenschaftliche Entwicklung im IuK- Bereich einzubringen International Mathematical Union hat mit iwi den Betrieb des Math-Net Dienstes MPRESS vereinbart.

35
28.05.01Oldenburg35 Master Studiengang Information Engineering Beginn im WS 2001/2002 mit U Twente Inhalte: Applications and tools in Cryptography and Coding, Applied information representation, Organizational aspects of the information chain, Mathematical foundations of Cryptography and Coding, Knowledge representation,Methodology, Methods and theory of Clustering, Formal methods of information representation,Neural Networks, Information Retrieval

36
Zurück zu den MetaDaten...

37
28.05.01Oldenburg37 RDF - What’s that? W3C: “The Resource Description Framework (RDF) integrates a variety of web-based metadata activities including sitemaps, content ratings, stream channel definitions, search engine data collection (web crawling), digital library collections, and distributed authoring, using XML as an interchange syntax.”
 integrates a variety of web-based metadata activities including sitemaps, content ratings, stream channel definitions, search engine data collection (web crawling), digital library collections, and distributed authoring, using XML as an interchange syntax. .")
38
28.05.01Oldenburg38 RDF - What’s that? Problem: Alles im Netz ist Maschinen-lesbar aber nicht Maschinen-verstehbar. Ziele von RDF: Definition zur Dokumentenbeschreibung, die keine Voraussetzungen an Anwendungen stellt. Domänen neutral ist. geeignet is in verschiedenen Bereichen Ressourcen zu beschreiben.

39
28.05.01Oldenburg39 Metadaten im HTML Header von Dateien Die Nutzung des HTML META-tag: Die Nutzung des HTML META-tag: HTML META ist kommutativ und assoziativ

40
28.05.01Oldenburg40 RDF - erster Eindruck Document dc.creatorrdf:type rdf:bag rdf:_1 rdf:_2 Dokument mit zwei Autoren

41
28.05.01Oldenburg41 RDF - erster Eindruck rdf:type dct:Person vCard:FN vCard: EMAIL Marie marie@... Person hat den Namen “Marie” hat als Emailadresse “marie@...”

42
28.05.01Oldenburg42 RDF - erster Eindruck Document dc.creatorrdf:type rdf:bag rdf:_1 rdf:_2 rdf:type dct:Person vCard:FN vCard: EMAIL Paulpaul@... rdf:type dct:Person vCard:FN vCard: EMAIL Marie marie@...

43
28.05.01Oldenburg43 HTML Meta RDF HTML Meta besteht aus Paaren (Attribut,Wert) RDF besteht aus Tripeln (Prädikat, Subjekt, Objekt) RDF kodiert Sätze (Statements)
 RDF besteht aus Tripeln (Prädikat, Subjekt, Objekt) RDF kodiert Sätze (Statements)")
44
28.05.01Oldenburg44 RDF ein Beispiel Die Seite http://www.hallo.org hat Paul als Autor. (Autor, http://www.hallo.org, Paul) http://www.hallo.org dc:creator Paul
 dc:creator Paul.")
45
28.05.01Oldenburg45 Darstellungsformen von RDF Tripel Darstellung (nicht eindeutig) Graphendarstellung XML-Darstellung (nicht eindeutig) Einführung einer Äquivalenzrelation um Eindeutigkeit eines RDF Datensatzes zu gewinnen!
 Graphendarstellung XML-Darstellung (nicht eindeutig) Einführung einer Äquivalenzrelation um Eindeutigkeit eines RDF Datensatzes zu gewinnen!")
46
Weiterführende Projekte

47
28.05.01Oldenburg47 Replication DFG Projekt gemeinsam mit Cellule Math Doc in Grenoble, Frankreich Verbesserung des bestehenden Replica- Systems der Harvest Software weg von der Master-Slave Architektur Aufbau eines Systems von Replica des Dienstes MPRESS in der ganzen Welt, basierend auf RDF

48
28.05.01Oldenburg48 Ziele von CARMEN Verbesserung (automatischer) Methoden zur Inhaltserschließung unter Nutzung neuer Techniken mit enger Verbindung zum Retrieval 3 Schwerpunkte Dokumente Heterogenität Metadaten Retrieval
 Methoden zur Inhaltserschließung unter Nutzung neuer Techniken mit enger Verbindung zum Retrieval 3 Schwerpunkte Dokumente Heterogenität Metadaten Retrieval")
49
28.05.01Oldenburg49 CARMEN AP7 Ein integriertes Hypertext- und Retrievalsystem für Digitale Bibliotheken Entwicklung eines Retrievalsystems auf der Basis der Harvest Software und mit der gleichen Funktionalität Der Gatherer generiert wohl strukturiertes RDF an Stelle der flachen SOIF Datensätze Retrievalkomponente designed für XML Retrieval mit der Sprache XIRQL (XQL+)
")
50
28.05.01Oldenburg50 Architektur

51
28.05.01Oldenburg51 Transformation RDF XML RDF ist ein Graph, XML baumförmig Keine eindeutige Abbildung RDF XML RDF ist offen bzgl. Struktur und Namensraum XML-Retrieval sollte auf vorgegebener DTD basieren (valid XML) Ziel: benutzerfreundliches Retrieval übersichtliche Informationsstrukturen
 Ziel: benutzerfreundliches Retrieval übersichtliche Informationsstrukturen.")
52
XQL-Anfragen //chapter/heading heading

53
28.05.01Oldenburg53 XQL Bedingungen bzgl. Dokumentstruktur Ergebnis: Teilbäume der XML-Dokumente

54
28.05.01Oldenburg54 XIRQL: XML IR query language Gewichtung für unsichere Dokumentrepräsentationen Datentypen mit vagen Prädikaten Relativismus bezüglich Struktur

55
28.05.01Oldenburg55 XIRQL: Datentypen mit vagen Prädikaten Erweiterbare Typhierarchie Personennamen, Klassifikation, Text - Englisch/Deutsch Menge vager Prädikate für jeden Datentyp Datentypen definiert in erweiterter DTD

56
28.05.01Oldenburg56 XIRQL- Anfragen chapter, in denen das Wort „extensible“ im heading vorkommt //chapter[heading $contains$ „extensible“] document mit class ähnlich „H.3.3“ und author phonetisch ähnlich zu „Maier“ //document[@class $approx$ „H.3.3“ $and$ author $sounds$ „Maier“]
![Oldenburg56 XIRQL- Anfragen chapter, in denen das Wort „extensible im heading vorkommt //chapter[heading $contains$ „extensible ] document mit class ähnlich „H.3.3 und author phonetisch ähnlich zu „Maier $approx$ „H.3.3 $and$ author $sounds$ „Maier ]](http://images.slideplayer.org/39/10960517/slides/slide_56.jpg "Oldenburg56 XIRQL- Anfragen chapter, in denen das Wort „extensible im heading vorkommt //chapter[heading $contains$ „extensible ] document mit class ähnlich „H.3.3 und author phonetisch ähnlich zu „Maier $approx$ „H.3.3 $and$ author $sounds$ „Maier ]")
57
28.05.01Oldenburg57 Die Wirklichkeit 40.000 Datensätze in MPRESS 18.000 mit wohlstrukturierten Metadaten 12.000 mit MSC Klassifikation heterogenes Material in einem Datenpool. Was tun mit Datensätzen ohne Metadaten?

58
28.05.01Oldenburg58 AP11: Heterogenitätsbehandlung Entwicklung von Heuristiken zur Extraktion von Metadaten aus unstrukturierten Textformaten und schlecht strukturiertem HTML. Thematisch begrenzt auf Mathematik und Sozialwissenschaften. Generierung von Relationen zwischen Keywords und kontrolliertem Vokabular. Module, die mit CAP 7 zusammenarbeiten können.

59
28.05.01Oldenburg59 Einige Probleme automatischer Metadatengenerierung Fehlende oder uneinheitliche Verwendung von Meta-Tags (author, keywords, DC-Tags) Inkonsistente Verwendung inhaltsbeschreibender HTML-Tags (title, h1, h2, address etc.) Uneinheitliche Formatierungen inhaltsrelevanter Angaben (Schriftgrad, Fett, zentriert etc.) Fehlende Kontextinformationen (Datum, Autor, Institution u.ä.)
 Inkonsistente Verwendung inhaltsbeschreibender HTML-Tags (title, h1, h2, address etc.) Uneinheitliche Formatierungen inhaltsrelevanter Angaben (Schriftgrad, Fett, zentriert etc.) Fehlende Kontextinformationen (Datum, Autor, Institution u.ä.)")
60
Beispiel HTML-Heuristiken : Titel If ( -Tag vorhanden && -Tag vorhanden) If ( -Tag== -Tag höchst. Ord.) { Titel[3]= -Tag } elsif ( -Tag enthält -Tag höchst. Ord.) { Titel[2]= -Tag } elsif ( -Tag höchst. Ord. enthält -Tag) { Titel[2]= -Tag höchst. Ord. } sonst { Titel[2]= -Tag + -Tag } } elsif ( -Tag vorhanden) { Titel[2]= -Tag } elsif ( -Tag vorhanden) { Titel[1]= -Tag höchst. Ord. } elsif (Paragraph mit / umschlossen vorhanden) { Titel[0]= letzter Paragraph mit / umschlossen } elsif [...]
 { Titel[3]= -Tag } elsif ( -Tag enthält -Tag höchst. Ord.) { Titel[2]= -Tag } elsif ( -Tag höchst. Ord. enthält -Tag) { Titel[2]= -Tag höchst. Ord. } sonst { Titel[2]= -Tag + -Tag } } elsif ( -Tag vorhanden) { Titel[2]= -Tag } elsif ( -Tag vorhanden) { Titel[1]= -Tag höchst. Ord. } elsif (Paragraph mit / umschlossen vorhanden) { Titel[0]= letzter Paragraph mit / umschlossen } elsif [...].")
61
28.05.01Oldenburg61 Erste Ergebnisse im Bereich Mathematik unstrukturierte PostScript Dokumente Extraktor Heuristiken dc:creator Schmid, Werner www.tum.de/ preprints/... Math. Subject Classification 65N55 rdf:value rdfs:label Multigrid methods; domain decomposition rdf:type Classifi- cation further MSC dc:subject (Keywords ) Multirid Methods, Eigenvalue Problems, Multigroup Diffusion Equations dcq:abstract Safety analysis of nuclear reactors strongly relies on numerical simultation of the reactor core....
 Multirid Methods, Eigenvalue Problems, Multigroup Diffusion Equations dcq:abstract Safety analysis of nuclear reactors strongly relies on numerical simultation of the reactor core.....")
62
28.05.01Oldenburg62 Weitere Schritte: Metadaten Ständige Weiterentwicklung der Heuristiken zur Metadaten-Extraktion Versuch der Übertragung mathematischer Extraktionsregeln über unstrukturierte Dokumente auf sozialwissenschaftliche Regeln über strukturierte Internet-Quellen und umgekehrt

63
28.05.01Oldenburg63 Mögliche Transferverfahren Intellektuell erstellte Crosskonkordanzen (AP12) Deduktive Verfahren Quantitativ-statistische Verfahren Neuronale Verfahren Kookurrenzanalyse
 Deduktive Verfahren Quantitativ-statistische Verfahren Neuronale Verfahren Kookurrenzanalyse")
64
28.05.01Oldenburg64 Statistische Transferverfahren Nicht intellektuell / qualitatives, sondern Quantitatives Vorgehen (Basiert auf Kookurenzen) Wesentlich feinere Abstufung der Relationen Findet intellektuell nicht erfassbare Relationen
 Wesentlich feinere Abstufung der Relationen Findet intellektuell nicht erfassbare Relationen ")
65
28.05.01Oldenburg65 Beispiel (VibSoz) "Gysi, Jutta: Familienleben in der DDR, zum Alltag von Familien mit Kindern, Akademie Verlag Berlin, 1989, ISBN 3-05-000771-0." Corpus USB Köln IZ USB Köln 'Deutschland ', 'Familie' IZ-Sozialwissenschaften 'Arbeitsteilung', 'Ehe', 'Familie', 'DDR', 'Partnerschaft'
 Gysi, Jutta: Familienleben in der DDR, zum Alltag von Familien mit Kindern, Akademie Verlag Berlin, 1989, ISBN Corpus USB Köln IZ USB Köln Deutschland , Familie IZ-Sozialwissenschaften Arbeitsteilung , Ehe , Familie , DDR , Partnerschaft")
66
Parallelkorpus Bestand 1 a c d b Thesaurus bzw. Klassifikation dokument x y z a Abgeleitete Zuordnung von Termen dokument Bestand 2 Bekannte Zuordnung von Dokumenten

67
Ausgangslage Volltexte aus dem Internet a c d b Terme des Volltext Indexierers dokument Thesaurus bzw. Klassifikation 2,3 dokument x y z a 6,1 3,2 1,5 5,1 4,2 2,3 Bildung eines echten Parallelkorpus nicht möglich

68
Parallelkorpus Erstellung Volltexte aus dem Internet a c d b Terme des Volltext Indexierers dokument 2,3 dokument Thesaurus bzw. Klassifikation x y z a 6,1 3,2 1,5 5,1 4,2 2,3 4,7 1,8 6,3 2,7 3,4 5,2 5,3 probabilistische Suche

69
Simuliertes Parallelkorpus Volltexte aus dem Internet a c d b Terme des Volltext Indexierers dokument 2,3 dokument Thesaurus bzw. Klassifikation x y z a 6,1 3,2 1,5 5,1 4,2 2,3 4,7 1,8 6,3 2,7 3,4 5,2 5,3 Abgeleitete Zuordnung von Termen

70
Statistische Analyse - Werkzeug: Jester Java Enviroment for Statistical TransfERs

71
28.05.01Oldenburg71 AP9: Interdisziplinäre Informationssysteme Verknüpfung von Math-Net und PhysNet unter Nutzung der Software CAP7 mit einer zusätzlichen Komponente zur verteilten Suche. Nutzung und Evaluation der intellektuell erstellten Crosskonkordanz MSC PACS) Automatische Erstellung einer Crosskonkordanz zwischen MSC und PACS (zu Verbesserungszwecken)
 Automatische Erstellung einer Crosskonkordanz zwischen MSC und PACS (zu Verbesserungszwecken).")
72
28.05.01Oldenburg72 MSC PACS Quantitative Analyse zur Erstellung einer Krosskonkordanz Ausgangsmaterial 16999 Datensätze aus der Datenbank MATH bzw. INSPEC Aufbereitung Anwendung von Jester Ergebnis AP12 AP12

Ähnliche Präsentationen


>")




>")
 Anwendung Aktuelle Situation Projekte.>")





, Semesterapparate Physik Ziel: Bereitstellung einer.>")




 Dr. Heike Neuroth The Academic Subject.>")
 Michael Kranz 01.02.2001 Betreuer: Roland Haratsch.>")