Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Busqueda de Substrings
Problema: verificar si un patron (string) s aparece en un texto (string) t o no. Algoritmo de Fuerza Bruta Knuth, Morris, Pratt (1977) Boyer & Moore (1977).
 s aparece en un texto (string) t o no. Algoritmo de Fuerza Bruta. Knuth, Morris, Pratt (1977) Boyer & Moore (1977).")
2
Algoritmo de fuerza bruta
Alinear 1ª posición de patrón con 1ª posición del texto, comparar caracteres uno a uno hasta fin del patrón -> se encontró matching, o hasta que se encuentre una discrepancia.

3
Naive Algorithm // n = largo del texto // m = largo del patron
// Los indices comienzan desde 1 int k=0; while (k< =n-m ) { k++; for(int i = 1, j = k; i <=m; i++, j++) if (texto[k] !=patron[j]) break; if (i > m) return calce en k return no estaba } Costo: O( |s| • |t| )
 { k++; for(int i = 1, j = k; i <=m; i++, j++) if (texto[k] !=patron[j]) break; if (i > m) return calce en k. return no estaba. } Costo: O( |s| • |t| )")
4
The Knuth, Morris, Pratt (KMP) Algorithm
El algoritmo de fuerza bruta corre en ujn lugar la búsqueda del patron en el texto cuando no calza. KMP aprovecha algunas características del patrón para ver si se puede correr más. Cómo? Veamos las siguientes ideas Si el patrón no tiene repeticiones internas (todas las letras distintas) se puede recomenzar a partir de donde falló Si parte del comienzo del patrón calza con las ultimas letras antes de fallar, se puede „correr“ el patron hasta hacer coincidir la parte del principio con la parte del texto que se parece x x x x a b x x x x a b a b
 se puede recomenzar a partir de donde falló. Si parte del comienzo del patrón calza con las ultimas letras antes de fallar, se puede „correr el patron hasta hacer coincidir la parte del principio con la parte del texto que se parece. x. x. x. x. a. b. x. x. x. x. a. b. a. b.")
5
Generalizemos Supongamos que comparando el texto con el patron en una posicion cualquiera tenemos j caracteres que coinciden pero el de la posición j+1 no Texto : Patrón:

6
Prefijo mas largo que coincide con el sufijo
Si tenemos coincidencia de los últimos i caracteres del patron (desde el caracter j-i+1 hasta j, ambos incluidos) que coincidieron con los caracteres del texto que tambien coinciden con los i primeros caracteres del patrón entonces solo podemos mover el patrón hasta que coincidan Texto: Patron: Prefijo i
 que coincidieron con los caracteres del texto que tambien coinciden con los i primeros caracteres del patrón entonces solo podemos mover el patrón hasta que coincidan. Texto: Patron: Prefijo i.")
7
La funcion de fracaso Una característica interesante de este enfoque es que el cáculco de cuánto vamos a „correr“ el patron cuando haya una falla revisando el i-esimo caracter depende solo de la „estructura interna“ del patrón, no del texto (tiene similitudes internas?). Esto permite calcular esto una vez antes de hacer la búsqueda Definimos entonces la función fracaso Sea el patrón b1b2..bm f(j) = max( i < j, | max(b1 ... bj = bj-i bj, j = 1..m)
. Esto permite calcular esto una vez antes de hacer la búsqueda. Definimos entonces la función fracaso. Sea el patrón b1b2..bm. f(j) = max( i < j, | max(b1 ... bj = bj-i bj, j = 1..m)")
8
Algorithmus von Knuth, Morris, Pratt (5)
Luego de definir esta funcion podemos explicar el algoritmo de la manera siguiente: Empiece comparando el patron con el texto de izquierda a derecha partiendo por la posicion k = 0. Si en una posicion k no hay coinicidencia con el caracter j+1 del patron entonces se continua con la posicion f(j)+1 del patron desde la (misma) posicion k del texto (sabemos que lso anteriores coinciden) Text : Pattern :
+1 del patron desde la (misma) posicion k del texto (sabemos que lso anteriores coinciden) Text : Pattern :")
9
The Algorithm (in pseudo-JAVA) assuming f(i) already calculated
// n = length of the text // m = length of the pattern // indexes start from 1 int k=0; int j=0; while (k<n && j<m) { while (j>0 && text[k+1]!=pattern[j+1]) { j=f[j]; } if (text[k+1])==pattern[j+1])) { j++; k++; // j==m => matching k == n => failure
 { while (j>0 && text[k+1]!=pattern[j+1]) { j=f[j]; } if (text[k+1])==pattern[j+1])) { j++; k++; // j==m => matching k == n => failure.")
10
Construction of the f(i) function
// m length of the pattern // indexes begin with 1 int[] f=new int[m]; f[1]=0; int j=1; int i; while (j<m) { i=f[j]; while (i>0 && pattern[i+1]!=pattern[j+1]) { i=f[i]; } if (pattern[i+1]== pattern[j+1]) { f[j+1]=i+1; } else { f[j+1]=0; j++;
 { i=f[j]; while (i>0 && pattern[i+1]!=pattern[j+1]) { i=f[i]; } if (pattern[i+1]== pattern[j+1]) { f[j+1]=i+1; } else { f[j+1]=0; j++;")
11
Algorithmus von Boyer und Moore
Ideen: Verschiebe das Wort s allmählich von links nach rechts, aber Vergleiche Wort s mit Text t im Wort s von rechts nach links. Zwei Heuristiken zum Verschieben des Suchstrings s. Bad-Character-Heuristik Good-Suffix-Heuristik Aufwand: auch O(|t|+|s|).
.")
12
Heuristiken

13
Erläuterungen zum Bild
In a) wird der Suchstring "reminiscence" von rechts nach links mit dem Text verglichen. Das Suffix "ce" stimmt überein, aber der "Bad-Character" "i" stimmt nicht mehr mit dem korrespondierenden "n" des Suchstrings überein. In b) wird der Suchstring nach der Bad-Character-Heuristik so weit nach rechts verschoben, bis der "Bad-Character" "i" mit dem am weitesten rechts auftretenden Vorkommen von "i" im Suchstring übereinstimmt. In c) wird nach der Good-Suffix-Heuristik das gefundene "Good-Suffix" "ce" mit dem Suchstring verglichen. Kommt dieses Suffix ein weiteres Mal im Suchstring vor, so kann der Suchstring so weit verschoben werden, dass dieses erneute Auftreten mit dem Text übereinstimmt.
 wird der Suchstring reminiscence von rechts nach links. mit dem Text verglichen. Das Suffix ce stimmt überein, aber der Bad-Character i stimmt nicht mehr mit dem. korrespondierenden n des Suchstrings überein. In b) wird der Suchstring nach der Bad-Character-Heuristik so. weit nach rechts verschoben, bis der Bad-Character i mit. dem am weitesten rechts auftretenden Vorkommen von i im Suchstring übereinstimmt. In c) wird nach der Good-Suffix-Heuristik das gefundene. Good-Suffix ce mit dem Suchstring verglichen. Kommt dieses Suffix ein weiteres Mal im Suchstring vor, so kann der Suchstring so weit verschoben werden, dass. dieses erneute Auftreten mit dem Text übereinstimmt.")
14
Die "Bad-Character Heuristik"
Matchfehler an der Stelle j mit s[j] t[pos+j], 1 j d (pos ist die Stelle vor dem aktuellen Beginn des Suchstrings) 1) Das falsche Zeichen t[pos+j] tritt im Suchstring nicht auf. Nun können wir ohne Fehler den Suchstring um j weiterschieben. 2) Das falsche Zeichen t[pos+j] tritt im Suchstring auf. Sei nun k der größte Index mit 1 k d, an dem s[k]=t[pos+j] gilt. Ist dann k<j, so wollen wir den Suchstring um j-k weiterschieben. Hier haben wir dann mindestens eine Übereinstimmung im Zeichen s[k] = t[pos+j]. Man kann den Wert k im voraus für jedes verschiedene Zeichen des Suchstrings als Funktion b(a) bestimmen, wobei a aus dem erlaubten Alphabet ist. b(a) gibt die Position des am weitesten rechts stehenden Auftreten vom Zeichen a im Suchstring an. Damit ist eine Verschiebung um j - k = j - b(t[pos + j]). zu machen. 3) Gilt allerdings k>j, so liefert die Heuristik einen negativen Shift j - k, der ignoriert wird, also Verschiebung um 1.
 1) Das falsche Zeichen t[pos+j] tritt im Suchstring nicht auf. Nun können wir ohne Fehler den Suchstring um j weiterschieben. 2) Das falsche Zeichen t[pos+j] tritt im Suchstring auf. Sei nun k der. größte Index mit 1 k d, an dem s[k]=t[pos+j] gilt. Ist dann k<j, so wollen wir den Suchstring um j-k weiterschieben. Hier haben wir dann mindestens eine Übereinstimmung im Zeichen. s[k] = t[pos+j]. Man kann den Wert k im voraus für jedes verschiedene. Zeichen des Suchstrings als Funktion b(a) bestimmen, wobei a aus. dem erlaubten Alphabet ist. b(a) gibt die Position des am weitesten. rechts stehenden Auftreten vom Zeichen a im Suchstring an. Damit ist. eine Verschiebung um j - k = j - b(t[pos + j]). zu machen. 3) Gilt allerdings k>j, so liefert die Heuristik einen negativen Shift j - k, der ignoriert wird, also Verschiebung um 1.")
15
Liste des rechtesten Wiedervorkommens im blauen Suchstring
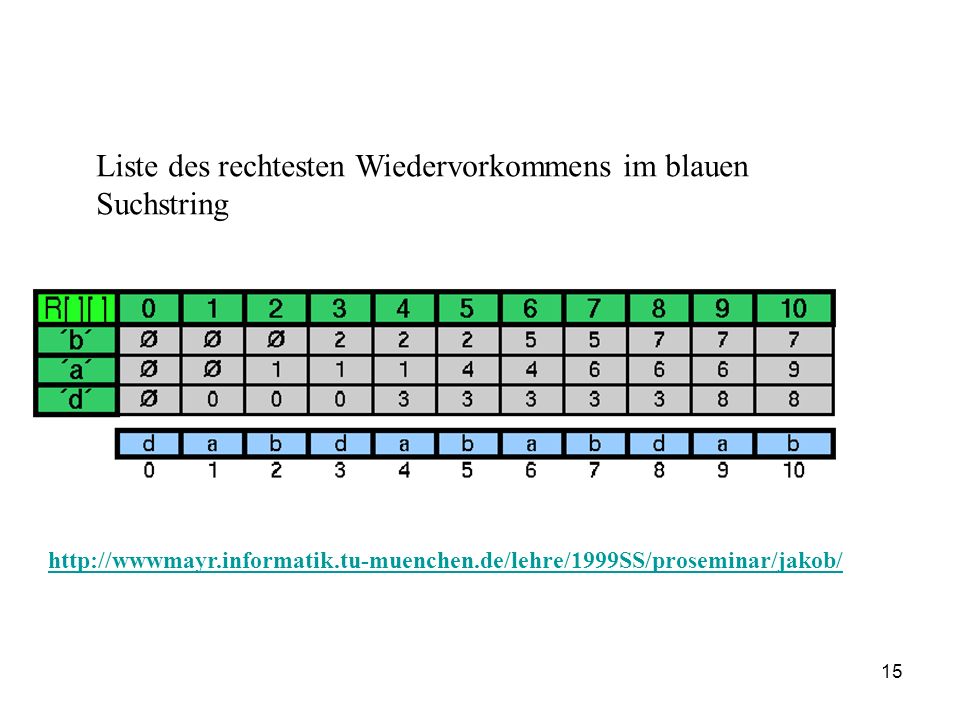
16
Beispiel BCH Rechtestes Auftreten im Suchstring finden

17
"Good-Suffix Heuristik"
Angenommen, wir haben einen Matchfehler an der Stelle j mit s[j] t[pos+j], 0 j d gefunden (die weiter rechts liegenden Zeichen stimmen also überein, pos ist die aktuelle Position in t ). Gilt j= d, so schieben wir den Suchstring einfach um eine Position weiter. Gilt jedoch j<d, so haben wir d-j Übereinstimmungen. Das Suffix des Suchstrings s der Länge d-j und der passende Textstring t von der Stelle pos+1 an stimmen links von pos+d in d-j Zeichen überein. pos s j j+1 d
. Gilt j= d, so schieben wir den Suchstring einfach um eine Position weiter. Gilt jedoch j<d, so haben wir d-j Übereinstimmungen. Das Suffix des Suchstrings s der Länge d-j und der passende Textstring t von. der Stelle pos+1 an stimmen links von pos+d in d-j Zeichen überein. pos. s. j. j+1. d.")
18
Die “Good-sufix” Funktion
Nun berechnen wir für jede Position j im Suchstring die Größe g[j] := d- max{k: 0 k < d; (s[j d] ist Suffix von sk oder sk ist Suffix von s[j d])}. g heißt dann "Good-Suffix"-Funktion und kann im Vorhinein für alle 0 j d berechnet werden. Sie gibt die kleinste Anzahl von Zeichen an, um die wir den Suchstring s nach rechts schieben können, ohne Übereinstimmungen mit dem Text zu verlieren. s=nennen s1 = n, s2 = ne, s3 = nen, s4=nenn, s5 = nenne, s6 = nennen s[6..6] =n, s[5..5] =en, s[3..5] =nen, s[2..5] =nnen, s[1..5] =ennen, g[0]= 6-max{1,3}, g[1]=3, g[2]=3, g[3]=3, g[4]=3, g[5]=6-4 s d k j j+1
}. g heißt dann Good-Suffix -Funktion und kann im Vorhinein für alle 0 j d. berechnet werden. Sie gibt die kleinste Anzahl von Zeichen an, um die wir den Suchstring s nach. rechts schieben können, ohne Übereinstimmungen mit dem Text zu verlieren. s=nennen s1 = n, s2 = ne, s3 = nen, s4=nenn, s5 = nenne, s6 = nennen. s[6..6] =n, s[5..5] =en, s[3..5] =nen, s[2..5] =nnen, s[1..5] =ennen, g[0]= 6-max{1,3}, g[1]=3, g[2]=3, g[3]=3, g[4]=3, g[5]=6-4. s. d. k. j. j+1.")
19
Good suffix alternativ
L'[ ] und l'[ ] für das Beispiel-Suchmuster: l'[pos] := Länge des längsten Suffix in Muster[pos..n], das auch Präfix ist. L'[pos] := Rechtes Ende der rechtesten Kopie von Muster[pos..n].

20
Good Suffix Beispiel Achtung – Verschiebung um 1 Länge d=11
Pos=0, j=6, g(6)=11-6=5 Pos=7, j=5, g(5)=11-3=8 k<d, g(0)=11-3=8 Fazit: 11 Gesamtlänge. Die gegebene Heuristik arbeitet gut
=11-6=5. Pos=7, j=5, g(5)=11-3=8. k<d, g(0)=11-3=8. Fazit: 11 Gesamtlänge. Die gegebene Heuristik arbeitet gut.")
21
Weitere Beispiele: Wir kennen keinen nennenswerten Fall nennen Hier ist d=6, j=4 und der Buchstabe k tritt nicht im Suchstring auf. Wir können demnach den String nach der Bad-Charakter Heuristik um 4 Plätze weiterschieben. Good-Suffix-Heuristik: Das Good-Suffix ist en; Verschiebung: um 3 Positionen Nunmehr kommt der Mismatch-Buchstabe n im Suchstring viermal vor. Das maximale Vorkommen ist k=6. Wir müssen also die Good-Suffix Heuristik anwenden. Im Vorhinein haben wir g[5] = 6-4=2 berechnet und können den Suchstring um zwei Plätze nach rechts weiterschieben: Hier ist j=1. Die Bad-Character Heuristik ermöglicht uns lediglich, den String um eine Position nach rechts zu verschieben. Das Good-Suffix ist jedoch ennen, und das Präfix nen das Suchstrings ist ein Suffix des Good-Suffix. Wir haben also vorher schon g[1]= 6-3=3 berechnet. Die Good-Suffix Heuristik erlaubt uns also, den Suchstring um drei Positionen nach rechts weiterzuschieben.

Ähnliche Präsentationen

 (2002) Methoden der Organisationsforschung.>")




>")




 Prof. Dr. Th. Ottmann.>")
 Prof. Th. Ottmann.>")
 T. Lauer.>")

 Prof. Dr. Th. Ottmann.>")


 Prof. Dr. Th. Ottmann.>")
