Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Die folgenden Folien beinhalten Erläuterungen, die einen Inhalt des Seminars ‚Fehler in der Schule – Schülerfehler‘ unterstützen sollen: Die Frage, wie sich systematisch auftretende Fehler erkennen lassen. Bei Klassengrößen zwischen 25 und 30, und vier bis sechs zu betreuenden Klassen, dürfte es kaum möglich sein, die Fehler, die jede einzelne Schülerin, jeder Schüler macht, im Blick zu behalten. Damit liegt es nahe, rechnergestützte Analyseverfahren zu nutzen und damit zugleich einen Blick auf die angewandten wissenschaftlichen Methoden psychologisch-pädagogischer Fehlerforschung zu richten. Die Folien sollen dabei behilflich sein, in Eigenarbeit die im Seminar besprochenen und erprobten Rechnen- und Analyseschritte nach zu vollziehen.

2
Ein erster, wichtiger Schritt der systematischen Analyse von Fehlern besteht in der Erfassung auftretender Fehler. Die detaillierte Feinauflösung dieser Erfassung kann nur gegenstands-, bzw. fachspezifisch diskutiert und erläutert werden. Im Prinzip gilt es, auftretende Fehler, unterschieden nach unter- schiedlichen Fehlerarten (siehe dazu Weimer 1925), möglichst genau, bezogen auf den Ort ihres Auftretens, zu erfassen. Um dies an einem einfachen Beispiel kurz zu demonstrieren, wird auf der nächsten Folie ein Text vorgestellt, der als Diktat vorgegeben wird. Die hier nicht geleistete Aufgabe bestünde bei der Konzeption des Textes darin, unterschiedliche Komma-Setz-Regeln (der aktuelle Duden behandelt dieses Thema in den § 71 bis 79) an verschiedenen Stellen des Textes, idealer Weise möglichst mehrfach, einzubauen. Das mehrfache Auftreten erlaubt Hinweise auf irrtümliche Annahmen, wenn auf inkonsistente Art und Weise mit der Kommasetzung unge- gangen wird.
 an verschiedenen Stellen des Textes, idealer Weise möglichst mehrfach, einzubauen. Das mehrfache Auftreten erlaubt Hinweise auf irrtümliche Annahmen, wenn auf inkonsistente Art und Weise mit der Kommasetzung unge- gangen wird.")
3
Beispiel für einen zu analysierenden Text; der Fokus soll hier auf der Analyse von Komma-Fehlern liegen Text eines Diktats: „Peter, ein Junge aus der Nachbarschaft, traf seine Freundin Inge. Inge war gerade auf dem Weg zum Freibad, obwohl es regnete, recht kalt war und das Wetter damit nicht gerade zum Baden einlud. Peter, der einen dicken Pullover unter einer Regenjacke trug, fand das Badengehen daher auch eine recht merkwürdige Idee. Er schlug statt dessen vor, ins Kino zu gehen. Doch er wollte, sie nicht. […..]“

4
Die im Text zu analysierenden Fehler müssen in einem ersten Schritt markiert werden. Eine Möglichkeit wäre es, einfach alle erforderlichen Kommata durchzunummerieren. Wichtig ist es, ein möglichst einfach und sicher handhabbares Verfahren anzuwenden. Im Anschluss wird eine Datenmatrix erstellt, bspw. so wie in der folgenden Tabelle dargestellt. Für jede Schülerin und jeden Schüler wird mit Hilfe einer festzulegenden Codierung eingetragen, ob das erforderliche Komma richtig oder falsch gesetzt wurde oder ob die Passage gar nicht geschrieben wurde. SchülerIn Komma_01 Komma_02 Komma_03 Komma_04 Komma_05 Komma_06 Komma_07 Komma_08 Sahra 1 2 Beate Jürgen Günther Dieter …. Codierung: 0 = Nicht bearbeitet 1 = Richtig 2 = Fehler

5
Wie lassen sich diese Daten nun auswerten?
Zunächst ist zu betonen, dass es ganz unterschiedliche Fragen gibt, die an diese Daten gestellt werden können. Entsprechend gibt es mehr als eine Antwort auf die Frage nach der Vorgehensweise einer Auswertung. Hier wird eine dieser Fragen in einem exemplarischen Sinne hervor- gehoben, um die Vorgehensweise vorzustellen und zu erläutern. Diese Frage lautet: Wie häufig tritt bei einem einzelnen Schüler/Schülerin ein bestimmter Fehler auf. Oder anders formuliert: Wie verteilen sich die Fehler- häufigkeiten bezogen auf die Schüler/Schülerinnen und die verschiedenen Anlässe, einen Fehler zu machen?

6
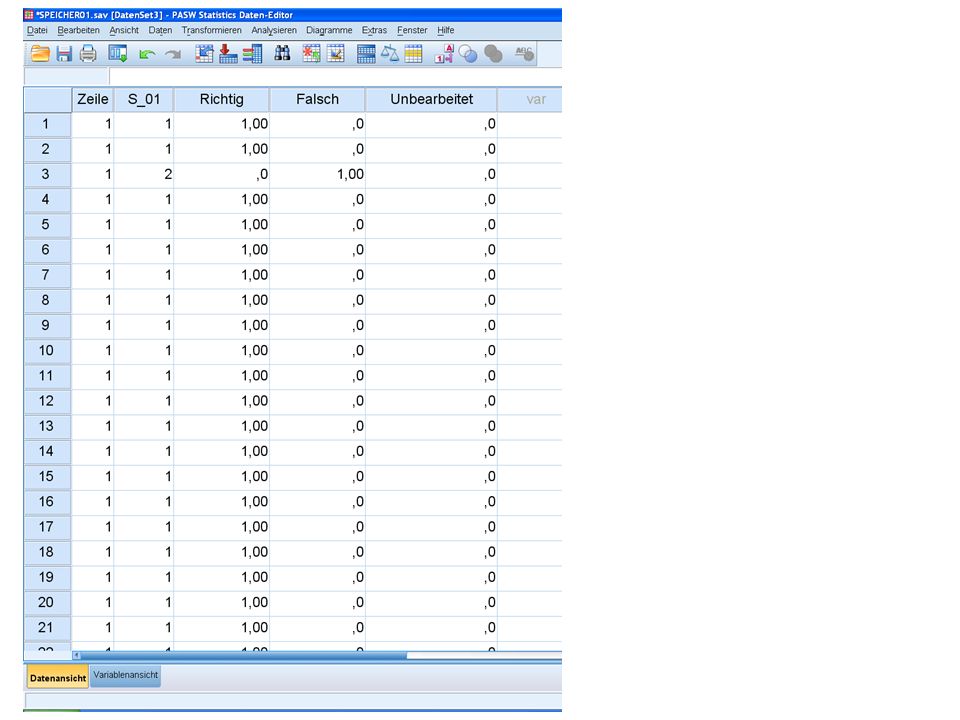
Vorgestellt wird die Vorgehensweise an einem Datensatz, der (auch) im Seminar erhoben wurde: Daten des d2 Aufmerksamkeits-Belastungstests (Brickenkamp 1981; 2002). Vereinfacht sind in diesem Satz die dabei erhobenen Daten wie folgt codiert: 0 = Nicht bearbeitet 1 = Richtig 2 = Fehler Für jede der 14 Zeilen und allen Spalten des Tests wird eingetragen, ob das Zeichen richtig (= 1), fehlerhaft (= 2) oder gar nicht (= 0) bearbeitet wurde. Wie man sieht, wurden in dem hier gezeigten Abschnitt alle Zeichen richtig angestrichen.
, fehlerhaft (= 2) oder gar nicht (= 0) bearbeitet wurde. Wie man sieht, wurden in dem hier gezeigten Abschnitt alle Zeichen richtig angestrichen.")
7
Die Daten jedes Testbogens sind hier durch eine Leerzeile vonein- ander getrennt.
Die hier gestellte Aufgaben lautet damit genauer: Wie häufig werden die Zeichen in der Zeile 1 und in der Spalte 1 fehlerhaft markiert? Wie häufig werden die Zeichen in der Zeile 2 und in der Spalte 1 fehlerhaft markiert? Etc.

8
Die Vorgehensweise zur Beantwortung dieser Frage lässt sich schematisch wie folgt darstellen:
Gesamtdatensatz Gib mir nur die Daten der zweiten Zeile, erste Spalte Gib mir nur die Daten der zweiten Zeile, erste Spalte Gib mir nur die Daten der ersten Zeile, erste Spalte Aus dem Gesamtdaten- satz werden nacheinander Teildatensätze gebildet, die jeweils nur die Daten einer Zeile und einer Spalte enthalten. Teildatensatz

9
SPSS/PASW bietet dafür unter Daten die Option Fälle auswählen

10
Klicken Sie diese Option an, öffnet sich das folgende Dialogfenster
Klicken Sie diese Option an, öffnet sich das folgende Dialogfenster. Dort klicken Sie das Feld Falls Bedingung zutrifft Falls an, worauf das nächste Dialogfenster geöffnet wird, in dem Sie Zeile = 1 eingeben.

11
Die Datei sieht nun wie folgt aus:
Es gibt nur noch die Daten aller Zeilen 1 und der Spalte 1 (S_01). Wie kann jetzt ermittel werden, wie oft in der Variable S_01 die Werte 0, 1 und 2 vorkommen? Dazu gibt es einen Befehl:
. Wie kann jetzt ermittel werden, wie oft in der Variable S_01 die Werte 0, 1 und 2 vorkommen Dazu gibt es einen Befehl:")
12
Unter Transformieren findet sich die Option Werte in Fällen zählen

15
Auf die bis zum diesem Punkt erläuterte Art und Weise ließen sich jetzt alle Spalten, aller Zeilen nacheinander analysieren. Doch: bei 14 Zeilen à 47 Spalten müsste 658 mal dieselbe Prozedur mit Mausklick und entsprechenden Eingaben durchgeführt werden — eine extrem mühsame ‚Eselsarbeit‘ . Doch SPSS/PASW bietet, wie fast alle anderen Programme auch, Automatisierungsoptionen in Form sog. Syntax-Prozeduren oder Makros. Im folgenden wird die Nutzung dieser Optionen erläutert. Kurz: für jede Spezifikation per Mausklick und Tastatur wird im Hintergrund ein Programmier-Code generiert, der für gewöhnlich ‚unsichtbar‘ bleibt. Um diesen Code zu sehen müssen folgende Einstellungen vorgenommen werden:

16
Unter Bearbeiten finden Sie ganz unter die Option Optionen.
Diese klicken Sie an.

17
Dann weiter zu Datei-Speicherstellen
Dann weiter zu Datei-Speicherstellen. Dort findet sich das Feld Sitzungs-Journal.

18
Hier kann die Option Syntax in Journal aufzeichnen aktiviert werden,
wodurch automatisch im Hintergrund der Programmier-Code (nahezu) aller Arbeitsschritte aufgezeichnet wird. Ein Stufe tiefer kann festgelegt werden, ob die Aufzeichnung jeweils an die bereits vorhandenen Auf- zeichnungen angehängt werden sollen, oder ob bei jedem Neustart des Programms die vorherigen Eintragungen gelöst und eine neue Aufzeichnung erstellt wird. Hier gilt es zu bedenken, dass bei Anhängen und komplexen Programmen relativ schnell vorhandene Speicher- kapazitäten erreicht werden können, die Software dann auf unterschied- liche Speicherorte zugreift, was die Rechengeschwindigkeit erheblich reduzieren kann. Zu guter Letzt muss der Speicherort der Datei und der Name der Journal-Datei festgelegt werden – sofern nicht die Voreinstellung akzeptiert wird.
 aller Arbeitsschritte aufgezeichnet wird. Ein Stufe tiefer kann festgelegt werden, ob die Aufzeichnung jeweils an die bereits vorhandenen Auf- zeichnungen angehängt werden sollen, oder ob bei jedem Neustart des Programms die vorherigen Eintragungen gelöst und eine neue Aufzeichnung erstellt wird. Hier gilt es zu bedenken, dass bei Anhängen und komplexen Programmen relativ schnell vorhandene Speicher- kapazitäten erreicht werden können, die Software dann auf unterschied- liche Speicherorte zugreift, was die Rechengeschwindigkeit erheblich reduzieren kann. Zu guter Letzt muss der Speicherort der Datei und der Name der Journal-Datei festgelegt werden – sofern nicht die Voreinstellung akzeptiert wird.")
19
Um alle verfügbaren Befehle und Optionen, inklusive ihrer Spezifikationen, zu sehen und erläutert zu bekommen, findet sich unter Hilfe die Rubrik Befehlssyntax-Referenz.

20
Die folgenden Seiten erläutern nun Schritt für Schritt den Inhalt einer Syntax, mit der die Berechnungen der Fehlerhäufigkeit in Prozenten aller bearbeiteten Spalten und Zeilen durchgeführt werden kann. Die Befehle können dabei a) als solche direkt in das Programm eingegeben werden – was die Kenntnis dieser Befehle und ihrer Spezifikationen erfordert, oder b) die Befehle können per Mausklick und Tastatureingaben, wie weiter oben erläutert, so lange eingegeben werden, bis das Resultat den gewünschten Zielen entspricht, um dann den Programmier-Code aus dem Journal heraus zu kopieren und in das Programm einzufügen.
 als solche direkt in das Programm eingegeben werden – was die Kenntnis dieser Befehle und ihrer Spezifikationen erfordert, oder. b) die Befehle können per Mausklick und Tastatureingaben, wie weiter oben erläutert, so lange eingegeben werden, bis das Resultat den gewünschten Zielen entspricht, um dann den Programmier-Code aus dem Journal heraus zu kopieren und in das Programm einzufügen.")
21
GET FILE='SPEICHER01.sav' /KEEP= Zeile, S_01 . EXECUTE . SELECT IF (Zeile = 1) . COUNT F_S = S_01 (2) . R_S = S_ (1) . O_S = S_ (0) . RECODE F_S R_S O_S (MISSING=0) . COMPUTE Fall = 1 . CREATE Fall = CSUM(Fall) . CREATE F_S = CSUM(F_S) . CREATE R_S = CSUM(R_S) . CREATE O_S = CSUM(O_S) . SORT CASES BY Fall (D) . SELECT IF ($casenum = 1) . COMPUTE Proz_F = (100 * F_S) / (F_S + R_S) . Dieser Befehlsbereich öffnet die in Anführungszeichen gesetzte Datei und listet dabei durch den Zusatz KEEP nur die nach dem Gleichheitszeichen aufgeführten Variablen.
 . O_S = S_01 (0) . RECODE. F_S R_S O_S (MISSING=0) . COMPUTE Fall = 1 . CREATE Fall = CSUM(Fall) . CREATE F_S = CSUM(F_S) . CREATE R_S = CSUM(R_S) . CREATE O_S = CSUM(O_S) . SORT CASES BY Fall (D) . SELECT IF ($casenum = 1) . COMPUTE Proz_F = (100 * F_S) / (F_S + R_S) . Dieser Befehlsbereich öffnet die in Anführungszeichen gesetzte Datei und listet dabei durch den Zusatz KEEP nur die nach dem Gleichheitszeichen aufgeführten Variablen.")
22
GET FILE='SPEICHER01.sav' /KEEP= Zeile, S_01 . EXECUTE . SELECT IF (Zeile = 1) . COUNT F_S = S_01 (2) . R_S = S_ (1) . O_S = S_ (0) . RECODE F_S R_S O_S (MISSING=0) . COMPUTE Fall = 1 . CREATE Fall = CSUM(Fall) . CREATE F_S = CSUM(F_S) . CREATE R_S = CSUM(R_S) . CREATE O_S = CSUM(O_S) . SORT CASES BY Fall (D) . SELECT IF ($casenum = 1) . COMPUTE Proz_F = (100 * F_S) / (F_S + R_S) . Durch diesen Befehl SELECT IF alle Fälle aus der Datei entfernt, bei denen die Variable Zeile nicht den Wert 1 aufweist.
 . O_S = S_01 (0) . RECODE. F_S R_S O_S (MISSING=0) . COMPUTE Fall = 1 . CREATE Fall = CSUM(Fall) . CREATE F_S = CSUM(F_S) . CREATE R_S = CSUM(R_S) . CREATE O_S = CSUM(O_S) . SORT CASES BY Fall (D) . SELECT IF ($casenum = 1) . COMPUTE Proz_F = (100 * F_S) / (F_S + R_S) . Durch diesen Befehl SELECT IF alle Fälle aus der Datei entfernt, bei denen die Variable Zeile nicht den Wert 1 aufweist.")
23
GET FILE='SPEICHER01.sav' /KEEP= Zeile, S_01 . EXECUTE . SELECT IF (Zeile = 1) . COUNT F_S = S_01 (2) . R_S = S_ (1) . O_S = S_ (0) . RECODE F_S R_S O_S (MISSING=0) . COMPUTE Fall = 1 . CREATE Fall = CSUM(Fall) . CREATE F_S = CSUM(F_S) . CREATE R_S = CSUM(R_S) . CREATE O_S = CSUM(O_S) . SORT CASES BY Fall (D) . SELECT IF ($casenum = 1) . COMPUTE Proz_F = (100 * F_S) / (F_S + R_S) . In diesem Block werden durch den Befehl COUNT zunächst neue Variablen generiert, die den nach COUNT eingetragenen Namen erhalten. Hier also F_S (soll für Fehler in der Spalte stehen) R_S (richtig in der Spalte) und O_S (ohne Bearbeitung). Nach dem Gleichheitszeichen wird die Variable aufgeführt, in der die in Klammern stehenden Werte gezählt werden sollen.
 . O_S = S_01 (0) . RECODE. F_S R_S O_S (MISSING=0) . COMPUTE Fall = 1 . CREATE Fall = CSUM(Fall) . CREATE F_S = CSUM(F_S) . CREATE R_S = CSUM(R_S) . CREATE O_S = CSUM(O_S) . SORT CASES BY Fall (D) . SELECT IF ($casenum = 1) . COMPUTE Proz_F = (100 * F_S) / (F_S + R_S) . In diesem Block werden durch den Befehl COUNT zunächst neue Variablen generiert, die den nach COUNT eingetragenen Namen erhalten. Hier also F_S (soll für Fehler in der Spalte stehen) R_S (richtig in der Spalte) und O_S (ohne Bearbeitung). Nach dem Gleichheitszeichen wird die Variable aufgeführt, in der die in Klammern stehenden Werte gezählt werden sollen.")
24
GET FILE='SPEICHER01.sav' /KEEP= Zeile, S_01 . EXECUTE . SELECT IF (Zeile = 1) . COUNT F_S = S_01 (2) . R_S = S_ (1) . O_S = S_ (0) . RECODE F_S R_S O_S (MISSING=0) . COMPUTE Fall = 1 . CREATE Fall = CSUM(Fall) . CREATE F_S = CSUM(F_S) . CREATE R_S = CSUM(R_S) . CREATE O_S = CSUM(O_S) . SORT CASES BY Fall (D) . SELECT IF ($casenum = 1) . COMPUTE Proz_F = (100 * F_S) / (F_S + R_S) . Der Befehl RECODE codiert in allen nachstehend aufgeführten Variablen, hier F_S, R_S und O_S, die in der nachfolgenden Klammer stehenden Werte um. In dem hier gezeigten Fall werden aus fehlenden Werten (MISSING) der Wert Null. Der Sinn dieses Befehls besteht darin, sicher zu stellen, dass keine fehlenden Werte vorliegen, weil in einem solchen Fall das gleich folgende Aufaddieren der Werte einer Spalte genau vor einem fehlenden Wert stoppen würde.
 . O_S = S_01 (0) . RECODE. F_S R_S O_S (MISSING=0) . COMPUTE Fall = 1 . CREATE Fall = CSUM(Fall) . CREATE F_S = CSUM(F_S) . CREATE R_S = CSUM(R_S) . CREATE O_S = CSUM(O_S) . SORT CASES BY Fall (D) . SELECT IF ($casenum = 1) . COMPUTE Proz_F = (100 * F_S) / (F_S + R_S) . Der Befehl RECODE codiert in allen nachstehend aufgeführten Variablen, hier F_S, R_S und O_S, die in der nachfolgenden Klammer stehenden Werte um. In dem hier gezeigten Fall werden aus fehlenden Werten (MISSING) der Wert Null. Der Sinn dieses Befehls besteht darin, sicher zu stellen, dass keine fehlenden Werte vorliegen, weil in einem solchen Fall das gleich folgende Aufaddieren der Werte einer Spalte genau vor einem fehlenden Wert stoppen würde.")
25
GET FILE='SPEICHER01.sav' /KEEP= Zeile, S_01 . EXECUTE . SELECT IF (Zeile = 1) . COUNT F_S = S_01 (2) . R_S = S_ (1) . O_S = S_ (0) . RECODE F_S R_S O_S (MISSING=0) . COMPUTE Fall = 1 . CREATE Fall = CSUM(Fall) . CREATE F_S = CSUM(F_S) . CREATE R_S = CSUM(R_S) . CREATE O_S = CSUM(O_S) . SORT CASES BY Fall (D) . SELECT IF ($casenum = 1) . COMPUTE Proz_F = (100 * F_S) / (F_S + R_S) . In diesem Block sind zwei Befehle enthalten: COMPUTE und CREATE CSUM. Mit COMPUTE wird eine neue Variable generiert, die den Namen Fall erhält. Durch das Gleichheitszeichen wird allen Fällen dieser neuen Variable der danach angegebene Wert, hier 1, zugewiesen. Mit CREATE und CSUM werden alle Werte einer Spalte auf- addiert. Direkt nach CREATE wird die Zielvariable des Aufaddierens angeben.
 . O_S = S_01 (0) . RECODE. F_S R_S O_S (MISSING=0) . COMPUTE Fall = 1 . CREATE Fall = CSUM(Fall) . CREATE F_S = CSUM(F_S) . CREATE R_S = CSUM(R_S) . CREATE O_S = CSUM(O_S) . SORT CASES BY Fall (D) . SELECT IF ($casenum = 1) . COMPUTE Proz_F = (100 * F_S) / (F_S + R_S) . In diesem Block sind zwei Befehle enthalten: COMPUTE und CREATE CSUM. Mit COMPUTE wird eine neue Variable generiert, die den Namen Fall erhält. Durch das Gleichheitszeichen wird allen Fällen dieser neuen Variable der danach angegebene Wert, hier 1, zugewiesen. Mit CREATE und CSUM werden alle Werte einer Spalte auf- addiert. Direkt nach CREATE wird die Zielvariable des Aufaddierens angeben.")
26
GET FILE='SPEICHER01.sav' /KEEP= Zeile, S_01 . EXECUTE . SELECT IF (Zeile = 1) . COUNT F_S = S_01 (2) . R_S = S_ (1) . O_S = S_ (0) . RECODE F_S R_S O_S (MISSING=0) . COMPUTE Fall = 1 . CREATE Fall = CSUM(Fall) . CREATE F_S = CSUM(F_S) . CREATE R_S = CSUM(R_S) . CREATE O_S = CSUM(O_S) . SORT CASES BY Fall (D) . SELECT IF ($casenum = 1) . COMPUTE Proz_F = (100 * F_S) / (F_S + R_S) . Nach dem Gleichheitszeichen steht CSUM für den Befehl Aufaddieren. Dahinter wird in Klammern die Variable angegeben, deren Werte auf- addiert werden sollen. Wie hier gezeigt, können die Werte einer Variable auch in derselben Variable aufaddiert werden. Zu beachten ist hier, dass dadurch die zuvor in der Variable enthaltenen Werte überschrieben werden und damit nicht mehr vorhanden sind!
 . O_S = S_01 (0) . RECODE. F_S R_S O_S (MISSING=0) . COMPUTE Fall = 1 . CREATE Fall = CSUM(Fall) . CREATE F_S = CSUM(F_S) . CREATE R_S = CSUM(R_S) . CREATE O_S = CSUM(O_S) . SORT CASES BY Fall (D) . SELECT IF ($casenum = 1) . COMPUTE Proz_F = (100 * F_S) / (F_S + R_S) . Nach dem Gleichheitszeichen steht CSUM für den Befehl Aufaddieren. Dahinter wird in Klammern die Variable angegeben, deren Werte auf- addiert werden sollen. Wie hier gezeigt, können die Werte einer Variable auch in derselben Variable aufaddiert werden. Zu beachten ist hier, dass dadurch die zuvor in der Variable enthaltenen Werte überschrieben werden und damit nicht mehr vorhanden sind!")
27
GET FILE='SPEICHER01.sav' /KEEP= Zeile, S_01 . EXECUTE . SELECT IF (Zeile = 1) . COUNT F_S = S_01 (2) . R_S = S_ (1) . O_S = S_ (0) . RECODE F_S R_S O_S (MISSING=0) . COMPUTE Fall = 1 . CREATE Fall = CSUM(Fall) . CREATE F_S = CSUM(F_S) . CREATE R_S = CSUM(R_S) . CREATE O_S = CSUM(O_S) . SORT CASES BY Fall (D) . SELECT IF ($casenum = 1) . COMPUTE Proz_F = (100 * F_S) / (F_S + R_S) . Mit SORT CASES BY werden anhand der nachfolgend genannten Variable, hier Fall, alle Fälle der Datei sortiert. Die Sortierung kann in zwei verschiedenen Richtungen Vorgenommen werden. Das in Klammern stehende D steht für descend (absteigend), ein A (arise) bewirkt eine auf- steigende Sortierung. Mit SELECT IF (siehe oben) wird hier durch $casenum auf die ganz links stehenden, automatisch generierten Zeilennummern abgehoben. Kurz: Es wir der erste, höchste Werte beibehalten.
 . O_S = S_01 (0) . RECODE. F_S R_S O_S (MISSING=0) . COMPUTE Fall = 1 . CREATE Fall = CSUM(Fall) . CREATE F_S = CSUM(F_S) . CREATE R_S = CSUM(R_S) . CREATE O_S = CSUM(O_S) . SORT CASES BY Fall (D) . SELECT IF ($casenum = 1) . COMPUTE Proz_F = (100 * F_S) / (F_S + R_S) . Mit SORT CASES BY werden anhand der nachfolgend genannten Variable, hier Fall, alle Fälle der Datei sortiert. Die Sortierung kann in zwei verschiedenen Richtungen Vorgenommen werden. Das in Klammern stehende D steht für descend (absteigend), ein A (arise) bewirkt eine auf- steigende Sortierung. Mit SELECT IF (siehe oben) wird hier durch $casenum auf die ganz links stehenden, automatisch generierten Zeilennummern abgehoben. Kurz: Es wir der erste, höchste Werte beibehalten.")
28
GET FILE='SPEICHER01.sav' /KEEP= Zeile, S_01 . EXECUTE . SELECT IF (Zeile = 1) . COUNT F_S = S_01 (2) . R_S = S_ (1) . O_S = S_ (0) . RECODE F_S R_S O_S (MISSING=0) . COMPUTE Fall = 1 . CREATE Fall = CSUM(Fall) . CREATE F_S = CSUM(F_S) . CREATE R_S = CSUM(R_S) . CREATE O_S = CSUM(O_S) . SORT CASES BY Fall (D) . SELECT IF ($casenum = 1) . COMPUTE Proz_F = (100 * F_S) / (F_S + R_S) . COMPUTE ist quasi der Universal- befehl für die unterschiedlichsten Berechnungen. Auch hier wird wieder direkt nach dem Befehl die Zielvariable angegeben, in die die zu berechnenden Werte eingetragen werden sollen (hier Proz_F). Dann wird die Berechnug nach dem Gleichheitszeichen an- gegeben: 100 mal F_S, geteilt durch F_S plus R_S. Der einfache Dreisatz zur Berechnung der Fehlerprozente.
 . O_S = S_01 (0) . RECODE. F_S R_S O_S (MISSING=0) . COMPUTE Fall = 1 . CREATE Fall = CSUM(Fall) . CREATE F_S = CSUM(F_S) . CREATE R_S = CSUM(R_S) . CREATE O_S = CSUM(O_S) . SORT CASES BY Fall (D) . SELECT IF ($casenum = 1) . COMPUTE Proz_F = (100 * F_S) / (F_S + R_S) . COMPUTE ist quasi der Universal- befehl für die unterschiedlichsten Berechnungen. Auch hier wird wieder direkt nach dem Befehl die Zielvariable angegeben, in die die zu berechnenden Werte eingetragen werden sollen (hier Proz_F). Dann wird die Berechnug nach dem Gleichheitszeichen an- gegeben: 100 mal F_S, geteilt durch F_S plus R_S. Der einfache Dreisatz zur Berechnung der. Fehlerprozente.")
29
Die Lösung: Nutzung von Makros
GET FILE='SPEICHER01.sav' /KEEP= Zeile, S_01 . EXECUTE . SELECT IF (Zeile = 1) . COUNT F_S = S_01 (2) . R_S = S_ (1) . O_S = S_ (0) . RECODE F_S R_S O_S (MISSING=0) . COMPUTE Fall = 1 . CREATE Fall = CSUM(Fall) . CREATE F_S = CSUM(F_S) . CREATE R_S = CSUM(R_S) . CREATE O_S = CSUM(O_S) . SORT CASES BY Fall (D) . SELECT IF ($casenum = 1) . COMPUTE Proz_F = (100 * F_S) / (F_S + R_S) . Auf Basis der bisherigen Erklärungen könnten jetzt für jede einzelne Berechnung die jeweils zu verändernden Werte – per Hand! – eingesetzt werden. Bspw. an diesen Stellen. Dies wäre etwas komfortabler, als mit Maus und Tastatur, aber immer noch recht mühsam. Die Lösung: Nutzung von Makros
 . COUNT. F_S = S_01 (2) . R_S = S_01 (1) . O_S = S_01 (0) . RECODE. F_S R_S O_S (MISSING=0) . COMPUTE Fall = 1 . CREATE Fall = CSUM(Fall) . CREATE F_S = CSUM(F_S) . CREATE R_S = CSUM(R_S) . CREATE O_S = CSUM(O_S) . SORT CASES BY Fall (D) . SELECT IF ($casenum = 1) . COMPUTE Proz_F = (100 * F_S) / (F_S + R_S) . Auf Basis der bisherigen Erklärungen könnten jetzt für jede einzelne Berechnung die jeweils zu verändernden Werte – per Hand! – eingesetzt werden. Bspw. an diesen Stellen. Dies wäre etwas komfortabler, als mit Maus und Tastatur, aber immer noch recht mühsam. Die Lösung: Nutzung von Makros.")
31
SPSS Makros Struktur Makro(grob)struktur Bedeutung, Funktion DEFINE !freq1 () . Anfang der Makrodefinition mit Name „!FREQ1“ und Argument „()“ . descriptives Makroinhalt var = alter fameink . !ENDDEFINE . Ende der Makrodefinition !freq Makroaufruf
 . Anfang der Makrodefinition mit Name „!FREQ1 und Argument „() . descriptives Makroinhalt var = alter fameink . !ENDDEFINE . Ende der Makrodefinition !freq1 . Makroaufruf.")
32
Die variablen Teile des Programms werden in einem Makro durch „Platzhalter“ markiert und am Ende des Programms wird in der sog. Makroexpansion festgelegt, welche Werte die „Platzhalter“ in dem jeweiligen Programmdurchlauf annehmen sollen. /* MAKRO zum Einlesen der Beispieldateien DEFINE !EINLESENUEBUNGSTXT (PFAD = !charend ('§')/KLASSE = !charend('§')/PLATZ = !charend ('§') ) . GET DATA /TYPE = TXT /FILE = !QUOTE (!PFAD) /DELCASE = LINE /DELIMITERS = "\t " /ARRANGEMENT = DELIMITED /FIRSTCASE = 1 /IMPORTCASE = ALL /VARIABLES = V1 F7.2 … Name des Makros: MAKRO_Einlesen_UebungsDateien.sps
/KLASSE = !charend( § )/PLATZ = !charend ( § ) ) . GET DATA /TYPE = TXT. /FILE = !QUOTE (!PFAD) /DELCASE = LINE. /DELIMITERS = \t /ARRANGEMENT = DELIMITED. /FIRSTCASE = 1. /IMPORTCASE = ALL. /VARIABLES = V1 F7.2. … Name des Makros: MAKRO_Einlesen_UebungsDateien.sps.")
33
An Ende des Programmaufrufs werden die Werte, die durch „Platzhalter“ beim Programmdurchlauf einnehmen sollen definiert. !ENDDEFINE . !EINLESENUEBUNGSTXT PFAD = C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\SE_Komplexe_Daten\School performance_Klasse_A.txt § KLASSE = 'A' § PLATZ = C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\SE_Komplexe_Daten\School performance_Klasse_A.sav § . Name des Makros: MAKRO_Einlesen_UebungsDateien.sps

34
Was bedeutet „TOKENS“? (engl. „Zeichen)
Mit der Option !TOKENS werden die nächsten n Tokens im Makroaufruf dem Argument bzw. den Argumenten zugewiesen. Als Elemente zählen Variablen, Zahlen, Strings usw.: Beschreibung Beispiele Anzahl Tokens und Erläuterungen Variablenliste Var1 Var2 Var3 3 (jeder Variablenname zählt als ein einzelnes Token) Werteliste 4 (jede Zahl zählt als einzelnes Token) Zeichenliste und Kommas A , b 3 (ein Komma wird als separates Token gezählt; Groß-/Kleinschreibung ist unerheblich)
 Werteliste (jede Zahl zählt als einzelnes Token) Zeichenliste und Kommas. A , b. 3 (ein Komma wird als separates Token gezählt; Groß-/Kleinschreibung ist unerheblich)")
35
Bei !TOKENS sind das Ausrufezeichen und die Anzahl n in einer Klammer wichtig. n entspricht positiven ganzzahligen Werten. Die Option !TOKENS-Option ist also nützlich, wenn die Anzahl der Token bekannt und konstant ist. Bei der Festlegung der Anzahl der Token sind Besonderheiten bei der „Zählweise“ von Token zu berücksichtigen: Beschreibung Beispiele Anzahl Tokens und Erläuterungen Anführungs-zeichen „Alter ..“ ‚cc 00 cd‘ 2 (Inhalte zwischen paarigen Anführungszeichen bzw. Hoch-kommatas zählen als ein Token) Zeichen-kombinationen 11A 2 (Zahl vor String) A11 1 (String vor Zahl)
 Zeichen-kombinationen. 11A. 2 (Zahl vor String) A11. 1 (String vor Zahl)")
36
In dem Beispiel Makro MACRO_Einfaches_Beispiel wird nach den Namensargumenten Var1 und Var2 unmittelbar nach einem notwendigen =-Zeichen die Option !TOKENS(1) angegeben. Während der sog. Makro- expansion greift !AUSWERTUNG auf die Vorgaben zurück, die durch dieses Argument festgelegt wurden, nämlich eine Variable Var1 und eine Variable Var2 bereitzustellen. Die Information „ein Zeichen“ wird daher mit der Zu- weisung zur gleichen Anzahl an Variablen zum Argument im Makroaufruf für die Analyse verknüpft.

37
Ein Beispiel: Name des Macros: MACRO_Einfaches_Beispiel
/* Einfaches erstes Beispiel für eine Makro-Programmierung DEFINE !Auswertung (VAR1 = !TOKENS(1)/ VAR2 = !TOKENS(1)) . GET FILE='C:\Programme\SPSS\1993 US Sozialerhebung (Teilmenge).sav'. EXECUTE . GRAPH /SCATTERPLOTT(BIVAR)= !VAR1 WITH !VAR2 . !ENDDEFINE . !AUSWERTUNG VAR1=alter VAR2= kinder . !AUSWERTUNG VAR1=alter VAR2= zeitung . !AUSWERTUNG VAR1=einkom91 VAR2= alter . /* GRAPH /* /SCATTERPLOT(BIVAR)=alter WITH kinder /* /MISSING=LISTWISE . Name des Macros: MACRO_Einfaches_Beispiel
/ VAR2 = !TOKENS(1)) . GET. FILE= C:\Programme\SPSS\1993 US Sozialerhebung (Teilmenge).sav . EXECUTE . GRAPH. /SCATTERPLOTT(BIVAR)= !VAR1 WITH !VAR2 . !ENDDEFINE . !AUSWERTUNG VAR1=alter VAR2= kinder . !AUSWERTUNG VAR1=alter VAR2= zeitung . !AUSWERTUNG VAR1=einkom91 VAR2= alter . /* GRAPH. /* /SCATTERPLOT(BIVAR)=alter WITH kinder. /* /MISSING=LISTWISE . Name des Macros: MACRO_Einfaches_Beispiel.")
38
In diesem Makro „MACRO_Einfaches_Beispiel“ wird oben fest- gelegt, dass den beiden Platzhaltern VAR1 und VAR2 Zeichen im Umfang von einem Zeichen zugeordnet werden. In den Befehl zum Erstellen eines Scatterplotts werden dann keine Variablennamen, sondern nur die Platzhalter gesetzt. /* Einfaches erstes Beispiel für eine Makro-Programmierung DEFINE !Auswertung (VAR1 = !TOKENS(1)/ VAR2 = !TOKENS(1)) . GET FILE='C:\Programme\SPSS\1993 US Sozialerhebung (Teilmenge).sav'. EXECUTE . GRAPH /SCATTERPLOTT(BIVAR)= !VAR1 WITH !VAR2 . !ENDDEFINE . !AUSWERTUNG VAR1=alter VAR2= kinder . !AUSWERTUNG VAR1=alter VAR2= zeitung . !AUSWERTUNG VAR1=einkom91 VAR2= alter . /* GRAPH /* /SCATTERPLOT(BIVAR)=alter WITH kinder /* /MISSING=LISTWISE . Was an Stelle der Platzhalter bei jedem Durchlauf gesetzt werden soll, wird an dieser Stelle fest- gelegt.
/ VAR2 = !TOKENS(1)) . GET. FILE= C:\Programme\SPSS\1993 US Sozialerhebung (Teilmenge).sav . EXECUTE . GRAPH. /SCATTERPLOTT(BIVAR)= !VAR1 WITH !VAR2 . !ENDDEFINE . !AUSWERTUNG VAR1=alter VAR2= kinder . !AUSWERTUNG VAR1=alter VAR2= zeitung . !AUSWERTUNG VAR1=einkom91 VAR2= alter . /* GRAPH. /* /SCATTERPLOT(BIVAR)=alter WITH kinder. /* /MISSING=LISTWISE . Was an Stelle der Platzhalter bei jedem Durchlauf gesetzt werden soll, wird an dieser Stelle fest- gelegt.")
39
!CHAREND („Zeichen“) – Listen durch ein einzelnes Zeichen
Mittels !CHAREND werden alle Tokens bis zu einem explizit festzulegenden Zeichen in einem Makroaufruf dem Argument zugewiesen und ausgeführt. Bei diesem Zeichen muss es sich um ein einzelnes Zeichen (String mit der Länge 1) handeln, das zwischen Hochkommata und in Klammern steht. Im Prinzip kann jedes beliebige Zeichen als Trennzeichen eingesetzt werden. Die SPSS Command Syntax Reference (2004) verwendet z.B. einen sog. Slash ‚/‘, um eine Trennung zu signalisieren. Dieser Slash hat also nichts mit dem Trennungszeichen zu tun, das zwischen zwei Argumentdefinitionen stehen muss; um eine Verwechslung zu vermeiden, wird empfohlen, als Zeichen keinen Slash, sondern ein beliebiges anderes Zeichen zu nehmen, bspw. ‚§‘.
 handeln, das zwischen Hochkommata und in Klammern steht. Im Prinzip kann jedes beliebige Zeichen als Trennzeichen eingesetzt werden. Die SPSS Command Syntax Reference (2004) verwendet z.B. einen sog. Slash ‚/‘, um eine Trennung zu signalisieren. Dieser Slash hat also nichts mit dem Trennungszeichen zu tun, das zwischen zwei Argumentdefinitionen stehen muss; um eine Verwechslung zu vermeiden, wird empfohlen, als Zeichen keinen Slash, sondern ein beliebiges anderes Zeichen zu nehmen, bspw. ‚§‘.")
40
Bei !CHAREND-Trennungszeichen ist ihre richtige Position absolut entscheidend. Eine falsche Position führt dazu, dass diese Positions- oder auch Namensargumente beim Aufruf des Makros falsche Token-Zusammenstellungen an SPSS über- geben. !CHAREND-Optionen sind v.a. bei positionalen Argumenten nützlich, können jedoch auch bei Namens- argumenten eingesetzt werden. DEFINE !Beispiel1 (key1 = !CHAREND (‚§‘) / key2 = !CHAREND (‚§‘) ). frequencies var = !key1 . descriptives var = !key2 . !ENDDEFINE . !Beispiel1 KEY1=familienstand ausbild abschluss geschl § KEY2=alter § .
 / key2 = !CHAREND (‚§‘) ). frequencies var = !key1 . descriptives var = !key2 . !ENDDEFINE . !Beispiel1 KEY1=familienstand ausbild abschluss geschl § KEY2=alter § .")
41
Ein Beispiel dazu: Name des Macros: MACRO_Einfaches_Beispiel2
/* Einfaches zweites Beispiel für eine Makro-Programmierung DEFINE !Auswertung1 (VAR1 = !TOKENS(1)/ VAR2 = !TOKENS(1)/VAR3 =TOKENS(1)) . GET FILE='C:\Programme\SPSS\1993 US Sozialerhebung (Teilmenge).sav'. EXECUTE . CROSSTABS /TABLES= !VAR1 BY !VAR2 BY !VAR3 /FORMAT= AVALUE TABLES /CELLS= COUNT EXPECTED ROW COLUMN TOTAL /COUNT ROUND CELL . !ENDDEFINE . !AUSWERTUNG1 VAR1= famstand VAR2 = leben VAR3 = ethgr . Name des Macros: MACRO_Einfaches_Beispiel2
/ VAR2 = !TOKENS(1)/VAR3 =TOKENS(1)) . GET. FILE= C:\Programme\SPSS\1993 US Sozialerhebung (Teilmenge).sav . EXECUTE . CROSSTABS. /TABLES= !VAR1 BY !VAR2 BY !VAR3. /FORMAT= AVALUE TABLES. /CELLS= COUNT EXPECTED ROW COLUMN TOTAL. /COUNT ROUND CELL . !ENDDEFINE . !AUSWERTUNG1 VAR1= famstand VAR2 = leben VAR3 = ethgr . Name des Macros: MACRO_Einfaches_Beispiel2.")
42
Eine weitere Möglichkeit die hier Erwähnung finden soll ist die Verwendung sog. positionaler Argumente. Dabei wird, wie in dem folgenden Beispiel gezeigt, durch den Befehl !POS und dem Zusatz !TOKENS die Möglichkeit geschaffen, durch die Benennung der Platzhalter in Form von !1 oder !2 etc. das Programm anzuweisen, den ersten Wert (durch !1), den zweiten Wert (durch !2) etc. aus der Reihe der aufgelisteten Tokens in das Programm aufzunehmen.
, den zweiten Wert (durch !2) etc. aus der Reihe der aufgelisteten Tokens in das Programm aufzunehmen.")
43
Name des Macros: MACRO_Einfaches_Beispiel3
/* Ein drittes Beispiel für eine Makro-Programmierung DEFINE !Auswertung1 (!POS = !TOKENS(1)/ !POS = !TOKENS(1)/!POS = !TOKENS(1)) . GET FILE='C:\Programme\SPSS\1993 US Sozialerhebung (Teilmenge).sav'. EXECUTE . CROSSTABS /TABLES= !1 BY !2 BY !3 /FORMAT= AVALUE TABLES /CELLS= COUNT EXPECTED ROW COLUMN TOTAL /COUNT ROUND CELL . !ENDDEFINE . !AUSWERTUNG1 famstand leben ethgr . !AUSWERTUNG1 famstand todesstr ethgr . !AUSWERTUNG1 famstand todesstr sternzei . Name des Macros: MACRO_Einfaches_Beispiel3
/ !POS = !TOKENS(1)/!POS = !TOKENS(1)) . GET. FILE= C:\Programme\SPSS\1993 US Sozialerhebung (Teilmenge).sav . EXECUTE . CROSSTABS. /TABLES= !1 BY !2 BY !3. /FORMAT= AVALUE TABLES. /CELLS= COUNT EXPECTED ROW COLUMN TOTAL. /COUNT ROUND CELL . !ENDDEFINE . !AUSWERTUNG1 famstand leben ethgr . !AUSWERTUNG1 famstand todesstr ethgr . !AUSWERTUNG1 famstand todesstr sternzei . Name des Macros: MACRO_Einfaches_Beispiel3.")
44
Die bislang vorgestellten Optionen erforderten es, dass die Anzahl und/oder Stellung der Platzhalter in der Definition festlag und bekannt war. Eine oft sehr nützliche Alternative zu dieser Option stellt der Befehl !CHAREND dar. Ein Beispiel für diesen bereits erläuterten Befehls folgt in dem nächsten Makro. Das besondere und neue an diesem nächsten Beispiel ist jedoch die Einführung von einer Schleife, einem sog. Loop. Was bewirken bzw. können solche Loops? Während in den bisherigen Beispielen für jeden Durchlauf des gestarteten Makros die dabei einzusetzenden Variablenwerte festgelegt werden mussten, werden bei einem Loop, genauer mit Hilfe eines sog. List-Processing-Loops eine (nahezu unbegrenzte) Menge von Werten vorgegeben, die dann auto- matisch der Reihe nach eingesetzt werden.
 Menge von Werten vorgegeben, die dann auto- matisch der Reihe nach eingesetzt werden.")
45
Schematisch lässt sich das Ganze so darstellen: Am Anfang eines solchen Loops steht der Befehl !DO gefolgt von der Bezeichnung des Platzhalters der einzusetzenden Variablen, bspw. !VAR, dann folgt der Befehl !IN und schließ- lich wird der Platz angegeben, an dem die einzusetzenden Werte oder Zeichen stehen, bspw. (LISTE). Das Ende der Schleife, des Loops wird durch den Befehl !DOEND ange- geben: !DO !VAR !IN (LISTE) Befehle – !DOEND
 Befehle – !DOEND.")
46
!DO !VAR !IN (LISTE) Select if (ALTER > !VAR) CROSSTABS /TABLES= Gehalt BY Hausbesitz /FORMAT= AVALUE TABLES /CELLS= COUNT EXPECTED ROW COLUMN TOTAL /COUNT ROUND CELL . !DOEND LISTE = In dieser schematischen Darstellung würden also alle vier Werte aus der „Liste“ automatisch nacheinander in die Berechnung ein- gesetzt werden.

47
/* Ein fünftes Beispiel für eine Makro-Programmierung mit einer Schleife
/* SET PRINTBACK=ON MPRINT=ON . DEFINE !Auswertung3 (LISTE1 = !CHAREND ('/')/ VAR1 = !TOKENS(1)) . GET FILE='C:\Programme\SPSS\1993 US Sozialerhebung (Teilmenge).sav'. EXECUTE . !DO !WERT1 !IN (!LISTE1) . CROSSTABS /TABLES= !WERT1 BY !VAR1 /FORMAT= AVALUE TABLES /CELLS= COUNT EXPECTED ROW COLUMN TOTAL /COUNT ROUND CELL . !DOEND . !ENDDEFINE . !AUSWERTUNG3 LISTE1 = famstand beschäft partei sternzei / VAR1 = todesstr . Name des Macros: MACRO_Einfaches_Beispiel5
/ VAR1 = !TOKENS(1)) . GET. FILE= C:\Programme\SPSS\1993 US Sozialerhebung (Teilmenge).sav . EXECUTE . !DO !WERT1 !IN (!LISTE1) . CROSSTABS. /TABLES= !WERT1 BY !VAR1. /FORMAT= AVALUE TABLES. /CELLS= COUNT EXPECTED ROW COLUMN TOTAL. /COUNT ROUND CELL . !DOEND . !ENDDEFINE . !AUSWERTUNG3 LISTE1 = famstand beschäft partei sternzei / VAR1 = todesstr . Name des Macros: MACRO_Einfaches_Beispiel5.")
48
Name des Macros: MACRO_Einfaches_Beispiel5a
/* Ein fünftes Beispiel für eine Makro-Programmierung mit einer Schleife /* SET PRINTBACK=ON MPRINT=ON . DEFINE !Auswertung3 (LISTE1 = !CHAREND ('/')/ VAR1 = !TOKENS(1)) . GET FILE='C:\Programme\SPSS\1993 US Sozialerhebung (Teilmenge).sav'. EXECUTE . !DO !WERT1 !IN (!LISTE1) . CROSSTABS /TABLES= !WERT1 BY !VAR1 /FORMAT= AVALUE TABLES /CELLS= COUNT EXPECTED ROW COLUMN TOTAL /COUNT ROUND CELL . !DOEND . !ENDDEFINE . !AUSWERTUNG3 LISTE1 = famstand beschäft partei sternzei alterhei geschw kinder alter gebmonat sternzei ausbild abschlus vaterab mutterab geschl ethgr einkom91 einkbefr region ort einwohn partei wahl92 einstell todesstr waffen gras religion leben kindid pille sexualkd prügel sterbehi zeitung tvstunde bigband blugrass country blues musicals klassik folk jazz opern rap hvymetal sport kultur tvshows tvnews tvpbs wissen4 partner sexfreq wohnen soi gebjahr fameink schulab altergr politik region4 verheira classic3 jazz3 rap3 blues3 /VAR1 = todesstr . Name des Macros: MACRO_Einfaches_Beispiel5a
/ VAR1 = !TOKENS(1)) . GET. FILE= C:\Programme\SPSS\1993 US Sozialerhebung (Teilmenge).sav . EXECUTE . !DO !WERT1 !IN (!LISTE1) . CROSSTABS. /TABLES= !WERT1 BY !VAR1. /FORMAT= AVALUE TABLES. /CELLS= COUNT EXPECTED ROW COLUMN TOTAL. /COUNT ROUND CELL . !DOEND . !ENDDEFINE . !AUSWERTUNG3 LISTE1 = famstand beschäft partei sternzei alterhei. geschw kinder alter gebmonat sternzei ausbild abschlus vaterab mutterab geschl ethgr einkom91 einkbefr region. ort einwohn partei wahl92 einstell todesstr waffen gras religion leben kindid pille sexualkd prügel sterbehi zeitung. tvstunde bigband blugrass country blues musicals klassik folk jazz opern rap hvymetal sport kultur tvshows tvnews. tvpbs wissen4 partner sexfreq wohnen soi gebjahr fameink schulab altergr politik region4 verheira classic3 jazz3 rap3 blues3. /VAR1 = todesstr . Name des Macros: MACRO_Einfaches_Beispiel5a.")
49
Was zunächst sehr kompliziert zu klingen scheint ist jedoch in den meisten Fällen eher einfach und sehr nützlich: Es lassen sich (nahezu) unbegrenzt viele Schleifen miteinander verschachteln: Das nächste Makro demonstriert diese Möglichkeit. Zuerst wird das erste Zeichen der Liste1 eingesetzt, dann das erste Zeichen der Liste2, dann das zweite Zeichen der Liste2 usw. Sind alle Zeichen der Liste2 durch, wird das zweite Zeichen der Liste1 eingesetzt usw. usw. LOOP II LOOP I

50
Name des Macros: MACRO_Einfaches_Beispiel4
/* Ein viertes Beispiel für eine Makro-Programmierung mit zwei ineinander /* verschachtelten Schleifen /* SET PRINTBACK=ON MPRINT=ON . DEFINE !Auswertung3 (LISTE1 = !CHAREND ('/')/ LISTE2 = !CHAREND ('§')) . GET FILE='C:\Programme\SPSS\1993 US Sozialerhebung (Teilmenge).sav' . EXECUTE . !DO !WERT1 !IN (!LISTE1) . !DO !WERT2 !IN (!LISTE2) . CROSSTABS /TABLES= !WERT1 BY !WERT2 /FORMAT= AVALUE TABLES /CELLS= COUNT EXPECTED ROW COLUMN TOTAL /COUNT ROUND CELL . !DOEND . !DOEND . !ENDDEFINE . !AUSWERTUNG3 LISTE1 = famstand beschäft partei / LISTE2 = todesstr sternzei § . Name des Macros: MACRO_Einfaches_Beispiel4
/ LISTE2 = !CHAREND ( § )) . GET. FILE= C:\Programme\SPSS\1993 US Sozialerhebung (Teilmenge).sav . EXECUTE . !DO !WERT1 !IN (!LISTE1) . !DO !WERT2 !IN (!LISTE2) . CROSSTABS. /TABLES= !WERT1 BY !WERT2. /FORMAT= AVALUE TABLES. /CELLS= COUNT EXPECTED ROW COLUMN TOTAL. /COUNT ROUND CELL . !DOEND . !DOEND . !ENDDEFINE . !AUSWERTUNG3 LISTE1 = famstand beschäft partei / LISTE2 = todesstr sternzei § . Name des Macros: MACRO_Einfaches_Beispiel4.")
51
Eine weitere Möglichkeit der Schleifenkonstruktion ist die eines sog
Eine weitere Möglichkeit der Schleifenkonstruktion ist die eines sog. Index-Loop. Beim Index-Loop wird bei einem Zähler mit dem Wert 1 gestartet und im Allgemeinen in n+1-Schritten solange wiederholt, bis ein bestimmter (Index-) Wert erreicht ist. !DO !var = (Anfang) !TO (Ende) [optional: !BY (Schritt)] Befehle - !DOEND Das folgende Makro zeigt ein Beispiel für einen solchen Index- Loop, mit dem sechs zusätzliche Variablen mit den Namen neu1var bis neu6var generiert werden: Im Anschluss an dieses Beispiel wird der bislang noch nicht eingeführte Befehl !CONCAT erläutert.
 Wert erreicht ist. !DO !var = (Anfang) !TO (Ende) [optional: !BY (Schritt)] Befehle - !DOEND. Das folgende Makro zeigt ein Beispiel für einen solchen Index- Loop, mit dem sechs zusätzliche Variablen mit den Namen neu1var bis neu6var generiert werden: Im Anschluss an dieses Beispiel wird der bislang noch nicht eingeführte Befehl !CONCAT erläutert.")
52
/* Ein sechstes Beispiel für eine Makro-Programmierung mit einer Index-Schleife
/* SET PRINTBACK=ON MPRINT=ON . DEFINE !LOOP1 (key1 = !TOKENS(1)/key2 = !TOKENS(1)) . !DO !i = !KEY1 !TO !KEY2 . COMPUTE !CONCAT (neu, !i, var) = normal (1) . !DOEND . !ENDDEFINE . !LOOP1 Key1 = 1 Key2 = 6 . Name des Macros: MACRO_Einfaches_Beispiel6
/key2 = !TOKENS(1)) . !DO !i = !KEY1 !TO !KEY2 . COMPUTE !CONCAT (neu, !i, var) = normal (1) . !DOEND . !ENDDEFINE . !LOOP1 Key1 = 1 Key2 = 6 . Name des Macros: MACRO_Einfaches_Beispiel6.")
53
Stringfunktionen und einige ihrer Variationsmöglichkeiten
Syntax für Strings Funktion, Rückmeldung und Beispiel !LENGTH (String) Länge des angegebenen Strings. Bsp.: !LENGTH(Hello). Ergebnis: 5 !CONCAT (String1, String2, …) Aneinanderkettung der zusammenzu- führenden Strings. Bsp.: !CONCAT(hel, lo). Ergebnis: Hello !QUOTE (String) Das Argument wird in Anführungs- zeichen gesetzt. Bsp.: !QUOTE(Hello). Ergebnis: „Hello“ !SUBSTR (String, FROM, [Länge]) Abschnitt des Strings, der ab FROM startet und bei nicht festgelegter Länge bis zum Stringende geht Bsp.: !SUBSTR(Hello, 3) Ergebnis: „LLO“
 Länge des angegebenen Strings. Bsp.: !LENGTH(Hello). Ergebnis: 5. !CONCAT (String1, String2, …) Aneinanderkettung der zusammenzu- führenden Strings. Bsp.: !CONCAT(hel, lo). Ergebnis: Hello. !QUOTE (String) Das Argument wird in Anführungs- zeichen gesetzt. Bsp.: !QUOTE(Hello). Ergebnis: „Hello !SUBSTR (String, FROM, [Länge]) Abschnitt des Strings, der ab FROM startet und bei nicht festgelegter Länge bis zum Stringende geht. Bsp.: !SUBSTR(Hello, 3) Ergebnis: „LLO")
54
Das Zusammenführen von ausgesuchten Variablen
Eine weitere Anwendung von Makros: Das Zusammenführen von ausgesuchten Variablen aus verschiedenen Dateien: Dazu müssen die einzelnen Dateien nacheinander aufgerufen werden Dabei werden nur die Variablen geladen, die von Interesse sind Die Auswahl der Variablen wird in einer (Zwischen-)Datei abgelegt Der nächste Datensatz wird aufgerufen, die Variablen ausgesucht etc. Der Datensatz wird mit den Daten in der Zwischendatei verbunden Wenn alle Datei „durchkämmt“ sind, ist der Datensatz „fertig“ Beispiel:
Datei abgelegt. Der nächste Datensatz wird aufgerufen, die Variablen ausgesucht etc. Der Datensatz wird mit den Daten in der Zwischendatei verbunden. Wenn alle Datei „durchkämmt sind, ist der Datensatz „fertig Beispiel:")
55
Name des Macros: MACRO_Einfaches_Beispiel7
/* Ein siebentes Beispiel für eine Makro-Programmierung zum Zusammenfügen verschiedener Datensätze /* SET PRINTBACK=ON MPRINT=ON . GET FILE='C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\SE_Komplexe_Daten\1991 US Sozialerhebung.sav' /KEEP = kinder . EXECUTE . COMPUTE YEAR = FORMATS YEAR (F 1.0) . SAVE OUTFILE='C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\SE_Komplexe_Daten\SPEICHER01.sav' . DEFINE !Zusammen1 (PFAD = !CHAREND ('/')/ WERT1 = !CHAREND ('§')) . FILE= !QUOTE(!PFAD) COMPUTE YEAR = !WERT1 . ADD FILES /FILE=* /* Alternative: MATCH /FILE='C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\SE_Komplexe_Daten\SPEICHER01.sav' . SAVE OUTFILE='C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\SE_Komplexe_Daten\SPEICHER01.sav' . !ENDDEFINE . !Zusammen1 PFAD = C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\SE_Komplexe_Daten\1993 US Sozialerhebung (Teilmenge).sav / WERT1 = 1993 § . PFAD = C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\SE_Komplexe_Daten\Mehl Fake.sav / WERT1 = 2000 § . Name des Macros: MACRO_Einfaches_Beispiel7
 . SAVE OUTFILE= C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\SE_Komplexe_Daten\SPEICHER01.sav . DEFINE !Zusammen1 (PFAD = !CHAREND ( / )/ WERT1 = !CHAREND ( § )) . FILE= !QUOTE(!PFAD) COMPUTE YEAR = !WERT1 . ADD FILES /FILE=* /* Alternative: MATCH. /FILE= C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\SE_Komplexe_Daten\SPEICHER01.sav . SAVE OUTFILE= C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\SE_Komplexe_Daten\SPEICHER01.sav . !ENDDEFINE . !Zusammen1. PFAD = C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\SE_Komplexe_Daten\1993 US Sozialerhebung (Teilmenge).sav / WERT1 = 1993 § . PFAD = C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\SE_Komplexe_Daten\Mehl Fake.sav / WERT1 = 2000 § . Name des Macros: MACRO_Einfaches_Beispiel7.")
56
/* Ein achtes Beispiel für eine Makro-Programmierung zum Berechnen des Mittelwertes
/* SET PRINTBACK=ON MPRINT=ON . GET FILE='C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\SE_Komplexe_Daten\SPEICHER01.sav' . EXECUTE . SELECT IF (YEAR = 2000) . COMPUTE Fall = 1 . CREATE SUMFall = CSUM(Fall) . CREATE SUMChild = CSUM(Kinder) . SORT CASES BY SUMfall (D) . SELECT IF ($casenum = 1) . COMPUTE MEANChild = SUMChild/SUMFall . RENAME VARIABLES (MEANChild = MEANChild2000) . SAVE OUTFILE='C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\SE_Komplexe_Daten\SPEICHER02.sav' / KEEP= MEANChild /* HIER BEGINNT DAS MAKRO !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! Name des Macros: MACRO_Einfaches_Beispiel8; Fortsetzung nächste Seite ↓
 . COMPUTE Fall = 1 . CREATE SUMFall = CSUM(Fall) . CREATE SUMChild = CSUM(Kinder) . SORT CASES BY SUMfall (D) . SELECT IF ($casenum = 1) . COMPUTE MEANChild = SUMChild/SUMFall . RENAME VARIABLES (MEANChild = MEANChild2000) . SAVE OUTFILE= C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\SE_Komplexe_Daten\SPEICHER02.sav / KEEP= MEANChild /* HIER BEGINNT DAS MAKRO !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! Name des Macros: MACRO_Einfaches_Beispiel8; Fortsetzung nächste Seite ↓")
57
DEFINE !Mittelwerte1 (LISTE1 = !CHAREND ('/')) .
!DO !Jahr !IN (!LISTE1) . GET FILE='C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\SE_Komplexe_Daten\SPEICHER01.sav' . EXECUTE . SELECT IF (YEAR = !Jahr) . COMPUTE Fall = 1 . CREATE SUMFall = CSUM(Fall) . CREATE SUMChild = CSUM(Kinder) . SORT CASES BY SUMFall (D) . SELECT IF ($casenum = 1) . COMPUTE MEANChild = SUMChild/SUMFall . RENAME VARIABLES (MEANChild = !CONCAT(MEANChild, !Jahr)) . MATCH FILES /FILE=* /FILE='C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\SE_Komplexe_Daten\SPEICHER02.sav' /DROP = Fall, SUMFall, SUMChild, YEAR, Kinder . SAVE OUTFILE='C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\SE_Komplexe_Daten\SPEICHER02.sav' . !DOEND . !ENDDEFINE . !Mittelwerte1 LISTE1 = / .
 . GET. FILE= C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\SE_Komplexe_Daten\SPEICHER01.sav . EXECUTE . SELECT IF (YEAR = !Jahr) . COMPUTE Fall = 1 . CREATE SUMFall = CSUM(Fall) . CREATE SUMChild = CSUM(Kinder) . SORT CASES BY SUMFall (D) . SELECT IF ($casenum = 1) . COMPUTE MEANChild = SUMChild/SUMFall . RENAME VARIABLES (MEANChild = !CONCAT(MEANChild, !Jahr)) . MATCH FILES /FILE=* /FILE= C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\SE_Komplexe_Daten\SPEICHER02.sav /DROP = Fall, SUMFall, SUMChild, YEAR, Kinder . SAVE OUTFILE= C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\SE_Komplexe_Daten\SPEICHER02.sav . !DOEND . !ENDDEFINE . !Mittelwerte1 LISTE1 = / .")
58
Ursprungs-Datei Ziel-Datei Datei als Zwischenablage Match Add
Die schematische Logik dieser Variante: Ursprungs-Datei Auswahl relevanter Variablen Berechnungen Auswahl relevanter Variablen Berechnungen Auswahl relevanter Variablen Berechnungen Match Datei als Zwischenablage Add Ziel-Datei

59
∑ aller Werte : Anzahl der Werte
Wie lassen sich nun aus diese Art und Weise zusammengestellte Dateien weiterverarbeiten? Eine Möglichkeit, die ausführlicher, d.h. nicht mit der maximal möglichen Eleganz vorgestellt wird (weil noch zu komplex), ist das Berechnen von Mittelwerten: ∑ aller Werte : Anzahl der Werte Dazu ist es wichtig, die Funktionen Lag und Lead einzuführen: X Lag Lead 198 . 220 305 470
, ist das Berechnen von Mittelwerten: ∑ aller Werte : Anzahl der Werte. Dazu ist es wichtig, die Funktionen Lag und Lead einzuführen: X. Lag. Lead")
60
Name der Syntax: Syntaxbeispiel_Zählen_Sortieren_Auswählen
Anmerkungen: Bitte vergleichen mit „create“ „$casenum“ verweist auf die Fallnummern am linken Rand der Datenmaske Lag(XYZ, 1) = die Zahl gibt den Abstand an: 1 = nächste Zeile; 2 = übernächste Zeile „D“ = down „A“ = up Setzt in eine Variable Anzahl_2 die Anzahl der Werte ‚2‘ der Variable var001 ein (siehe auch Syntax Befehlsdefinitionen) COMPUTE Fall = 1 . EXECUTE . /* ALTERNATIVE: COMPUTE Fall = $casenum . /* SELECT IF (Kinder = 4) . IF ($casenum >1) Fall = Lag(Fall, 1) + Fall . SORT CASES BY Fall (D) . /* ALTERNATIV: (A) SELECT IF ($casenum = 1) . COUNT Anzahl_2 = var (2) .
 = die Zahl gibt den Abstand an: 1 = nächste Zeile; 2 = übernächste Zeile. „D = down „A = up. Setzt in eine Variable Anzahl_2 die Anzahl der Werte ‚2‘ der Variable var001. ein. (siehe auch Syntax Befehlsdefinitionen) COMPUTE Fall = 1 . EXECUTE . /* ALTERNATIVE: COMPUTE Fall = $casenum . /* SELECT IF (Kinder = 4) . IF ($casenum >1) Fall = Lag(Fall, 1) + Fall . SORT CASES BY Fall (D) . /* ALTERNATIV: (A) SELECT IF ($casenum = 1) . COUNT. Anzahl_2 = var001 (2) .")
61
Häufigkeiten zählen mit dem Befehl „COUNT“:
Allgemeine Syntax: COUNT Zielvariable = Quellvariable(n) (Werteliste) Zu zählende Werte Beschreibung Einzelwerte Alle fehlenden Werte missing Systemdefinierte fehlende Werte sysmis Wertebereiche: … bis … 5 thru 10 Wertebereiche: kleinster bis … lowest thru 0 Wertebereiche: … bis größter Wert 100 thru highest
 (Werteliste) Zu zählende Werte. Beschreibung. Einzelwerte Alle fehlenden Werte. missing. Systemdefinierte fehlende Werte. sysmis. Wertebereiche: … bis … 5 thru 10. Wertebereiche: kleinster bis … lowest thru 0. Wertebereiche: … bis größter Wert. 100 thru highest.")
62
ACHTUNG, ganz WICHTIG!!! CREATE bezieht sich wie folgt auf die Spalten: CREATE Function keywords: CSUM Cumulative sum DIFF Difference FFT Fast Fourier transform IFFT Inverse fast Fourier transform LAG Lag LEAD Lead MA Centered moving averages PMA Prior moving averages RMED Running medians SDIFF Seasonal difference T4253H Smoothing

63
Befehl COMPUTE ACHTUNG, ganz WICHTIG!!!
COMPUTE bezieht sich dagegen fast – aber leider nicht immer – wie folgt auf die Zeilen: Befehl COMPUTE

64
COMPUTE target variable=expression Example COMPUTE newvar1=var1+var2.
ABS(arg) Absolute value. ABS(SCALE) is 4.7 when SCALE equals 4.7 or –4.7. RND(arg) Round the absolute value to an integer and reaffix the sign. RND(SCALE) is –5 when SCALE equals –4.7. TRUNC(arg) Truncate to an integer. TRUNC(SCALE) is –4 when SCALE equals –4.7. MOD(arg,arg) Remainder (modulo) of the first argument divided by the second. When YEAR equals 1983, MOD(YEAR,100) is 83. SQRT(arg) Square root. SQRT(SIBS) is 1.41 when SIBS equals 2. EXP(arg) Exponential. e is raised to the power of the argument. EXP(VARA) is 7.39 when VARA equals 2. LG10(arg) Base 10 logarithm. LG10(VARB) is 0.48 when VARB equals 3. LN(arg) Natural or Naperian logarithm (base e). LN(VARC) is 2.30 when VARC equals 10. LNGAMMA(arg) Logarithm (base e) of complete Gamma function. ARSIN(arg) Arcsine. (Alias ASIN.) The result is given in radians. ARSIN(ANG) is 1.57 when ANG equals 1. ARTAN(arg) Arctangent. (Alias ATAN.) The result is given in radians. ARTAN(ANG2) is 0.79 when ANG2 equals 1. SIN(arg) Sine. The argument must be specified in radians. SIN(VARD) is 0.84 when VARD equals 1. COS(arg) Cosine. The argument must be specified in radians. COS(VARE) is 0.54 when VARE equals 1. COMPUTE COMPUTE target variable=expression Example COMPUTE newvar1=var1+var2. COMPUTE newvar2=RND(MEAN(var1 to var4). COMPUTE logicalVar=(var1>5). STRING newString (A10). COMPUTE newString=CONCAT((RTRIM(stringVar1), stringVar2). Functions and operators available for COMPUTE are described in “Transformation Expressions” on p. 44.
 Absolute value. ABS(SCALE) is 4.7 when SCALE equals 4.7 or –4.7. RND(arg) Round the absolute value to an integer and reaffix the sign. RND(SCALE) is. –5 when SCALE equals –4.7. TRUNC(arg) Truncate to an integer. TRUNC(SCALE) is –4 when SCALE equals –4.7. MOD(arg,arg) Remainder (modulo) of the first argument divided by the second. When YEAR. equals 1983, MOD(YEAR,100) is 83. SQRT(arg) Square root. SQRT(SIBS) is 1.41 when SIBS equals 2. EXP(arg) Exponential. e is raised to the power of the argument. EXP(VARA) is when VARA equals 2. LG10(arg) Base 10 logarithm. LG10(VARB) is 0.48 when VARB equals 3. LN(arg) Natural or Naperian logarithm (base e). LN(VARC) is 2.30 when VARC equals. 10. LNGAMMA(arg) Logarithm (base e) of complete Gamma function. ARSIN(arg) Arcsine. (Alias ASIN.) The result is given in radians. ARSIN(ANG) is when ANG equals 1. ARTAN(arg) Arctangent. (Alias ATAN.) The result is given in radians. ARTAN(ANG2) is when ANG2 equals 1. SIN(arg) Sine. The argument must be specified in radians. SIN(VARD) is 0.84 when. VARD equals 1. COS(arg) Cosine. The argument must be specified in radians. COS(VARE) is 0.54 when. VARE equals 1. COMPUTE. COMPUTE target variable=expression. Example. COMPUTE newvar1=var1+var2. COMPUTE newvar2=RND(MEAN(var1 to var4). COMPUTE logicalVar=(var1>5). STRING newString (A10). COMPUTE newString=CONCAT((RTRIM(stringVar1), stringVar2). Functions and operators available for COMPUTE are described in Transformation Expressions on p. 44.")
65
The following arithmetic operators are available: + Addition
COMPUTE - Befehle SUM(arg list) Sum of the nonmissing values across the argument list. MEAN(arg list) Mean of the nonmissing values across the argument list. SD(arg list) Standard deviation of the nonmissing values across the argument list. VARIANCE(arg list) Variance of the nonmissing values across the argument list. CFVAR(arg list) Coefficient of variation of the nonmissing values across the argument list. The coefficient of variation is the standard deviation divided by the mean. MIN(arg list) Minimum nonmissing value across the argument list. MAX(arg list) Maximum nonmissing value across the argument list. The following arithmetic operators are available: + Addition – Subtraction * Multiplication / Division ** Exponentiation
 Sum of the nonmissing values across the argument list. MEAN(arg list) Mean of the nonmissing values across the argument list. SD(arg list) Standard deviation of the nonmissing values across the argument list. VARIANCE(arg list) Variance of the nonmissing values across the argument list. CFVAR(arg list) Coefficient of variation of the nonmissing values across the argument list. The coefficient of variation is the standard deviation divided by the mean. MIN(arg list) Minimum nonmissing value across the argument list. MAX(arg list) Maximum nonmissing value across the argument list. The following arithmetic operators are available: + Addition. – Subtraction. * Multiplication. / Division. ** Exponentiation.")
66
1993 US Sozialerhebung (Teilmenge).sav Mehl Fake.sav
Aufgabe 1: Stellen Sie eine neue Datei zusammen, die Variablen enthält, die die Anzahl von 1, 2 und 3 Kindern in den Dateien 1991 US Sozialerhebung.sav 1993 US Sozialerhebung (Teilmenge).sav Mehl Fake.sav wiedergeben: oder: Ein_Kind_1991 Zwei_Kind_1991 Drei_Kind_1991 …. 29 4 34 Jahr Ein_Kind Zwei_Kinder Drei_Kinder 1991 29 4 34 1993
.sav. Mehl Fake.sav. wiedergeben: oder: Ein_Kind_1991. Zwei_Kind_1991. Drei_Kind_1991. … Jahr. Ein_Kind. Zwei_Kinder. Drei_Kinder")
67
Probleme: Wie muss die Grobstruktur des Programms aussehen?
Makrodefinition (2 Loops) Erste Schleife (Jahr) Adden (cases hinzufügen) Um cases erweiterte Datei ablegen Ende der zweiten Schleife Zweite Schleife (Anzahl Kinder) Variablenauswahl, Werteselektion Berechnen Sortieren Renamen Matchen (Variablen hinzufügen) Im Zwischenspeicher ablegen Ende der ersten Schleife Makroende
 Erste Schleife (Jahr) Adden (cases hinzufügen) Um cases erweiterte Datei ablegen. Ende der zweiten Schleife. Zweite Schleife (Anzahl Kinder) Variablenauswahl, Werteselektion. Berechnen. Sortieren. Renamen. Matchen (Variablen hinzufügen) Im Zwischenspeicher ablegen. Ende der ersten Schleife. Makroende.")
68
Regeln für die Vergabe von Variablennamen:
Variablennamen können aus Buchstaben und Ziffern gebildet werden. Erlaubt sind ferner die Sonderzeichen _ (underscore), . (Punkt) sowie die #, $ Nicht erlaubt sind Leerzeichen sowie spezifische Zeichen, wie !, ?, » und *. Der Variablenname muss mit einem Buchstaben beginnen. Erlaubt ist ferner das Das letzte Zeichen darf kein Punkt und sollte kein _ (underscore) sein, um Konflikte mit speziellen Variablen, die von SPSS-Prozeduren angelegt werden, zu vermeiden. Der Variablenname darf (ab der Version 12) max 64 Zeichen lang sein. Variablennamen sind nicht case-sensitive, d.h. die Groß- und Kleinschreibung ist nicht relevant. Variablennamen dürfen nicht doppelt vergeben werden. Reservierte Schlüsselwörter können nicht als Variablennamen verwendet werden. Zu den reservierten Schlüsselwörtern zählen: ALL, AND, BY, EQ, GE, GT, LE, LT, NE, NOT, OR, TO, WITH. Beispiele für ungültige Variablennamen: 1mal1 Bühl&Zöfel Stand 94 Wagen!
, . (Punkt) sowie die #, $ Nicht erlaubt sind Leerzeichen sowie spezifische Zeichen, wie !, , » und *. Der Variablenname muss mit einem Buchstaben beginnen. Erlaubt ist ferner das Das letzte Zeichen darf kein Punkt und sollte kein _ (underscore) sein, um Konflikte mit speziellen Variablen, die von SPSS-Prozeduren angelegt werden, zu vermeiden. Der Variablenname darf (ab der Version 12) max 64 Zeichen lang sein. Variablennamen sind nicht case-sensitive, d.h. die Groß- und Kleinschreibung ist nicht relevant. Variablennamen dürfen nicht doppelt vergeben werden. Reservierte Schlüsselwörter können nicht als Variablennamen verwendet werden. Zu den reservierten Schlüsselwörtern zählen: ALL, AND, BY, EQ, GE, GT, LE, LT, NE, NOT, OR, TO, WITH. Beispiele für ungültige Variablennamen: 1mal1 Bühl&Zöfel Stand 94 Wagen!")
69
Kommen wir jetzt auf das Eingangs-Beispiel d² - Test zurück:
Wie lässt sich für jedes Feld der %-Anteil einer fehlerhaften Bearbeitung berechnen? Ein erster Schritt wäre es, eine Datei mit allen Fällen der einzelnen Dateien zusammenzustellen, die vollständige Id‘s enthält Dann, Spalte für Spalte, alle Zeilen einzeln aller Bearbeitungen zu betrachten und zusammenzuzählen, wie oft dort eine 1 (fehlerfrei) oder eine 2 (Fehler) ein- getragen wurde. Schließlich wird die Summe aller Werte > 1 und die Summe aller Werte = 2 ermittelt Auf dieser Grundlage ergibt sich dann der %-Anteil
 oder eine 2 (Fehler) ein- getragen wurde. Schließlich wird die Summe aller Werte > 1 und die Summe aller Werte = 2 ermittelt. Auf dieser Grundlage ergibt sich dann der %-Anteil.")
70
/* Makro zum Ersetzen/Ausfüllen der Id-Nummern
/* SET PRINTBACK=ON MPRINT=ON . CD 'C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\D_Zwei' . ERASE FILE = 'SPEICHER01.sav' . DEFINE !Vervollstaendigen (LISTE = !CHAREND ('/')) . !DO !Datei !IN (!LISTE) . GET FILE= !Datei . EXECUTE . RECODE ID (MISSING=0) . IF ((Zeile > 0) & ($casenum > 1)) Id = Id + Lag(Id, 1) . ADD FILES /FILE=* /FILE='SPEICHER01.sav' . SAVE OUTFILE= 'SPEICHER01.sav' . !DOEND . !ENDDEFINE . !Vervollstaendigen Liste = 'Daten-Mi-10.sav' 'Daten-Mi-11.sav' 'Daten-Mi-12.sav' 'Daten-Mi-13.sav' 'Daten-Mi-14.sav' 'Daten-Mi-15.sav' 'Daten-Mi-16.sav' 'Daten-Mi-17.sav' 'Daten-Mi-18.sav' 'Daten-Mo-01.sav' 'Daten-Mo-02.sav' / .
) . !DO !Datei !IN (!LISTE) . GET. FILE= !Datei . EXECUTE . RECODE. ID (MISSING=0) . IF ((Zeile > 0) & ($casenum > 1)) Id = Id + Lag(Id, 1) . ADD FILES /FILE=* /FILE= SPEICHER01.sav . SAVE OUTFILE= SPEICHER01.sav . !DOEND . !ENDDEFINE . !Vervollstaendigen. Liste = Daten-Mi-10.sav Daten-Mi-11.sav Daten-Mi-12.sav Daten-Mi-13.sav Daten-Mi-14.sav Daten-Mi-15.sav Daten-Mi-16.sav Daten-Mi-17.sav Daten-Mi-18.sav Daten-Mo-01.sav Daten-Mo-02.sav / .")
71
Datei der Daten aller Bearbeitungen
Anhand dieser Datei aller Bearbeitungen gilt es jetzt eine Struktur wie die folgende zu erstellen: Spalte S_01, Zeile 1 des ersten Testteilnehmers Spalte S_01, Zeile 1 des zweiten Testteilnehmers Datei der Daten aller Bearbeitungen Spalte S_01, Zeile 1 des letzten Testteilnehmers

72
Sind auf diese Art und Weise die Werte Zeile 1, Spalte S_01 zusammengestellt, gilt es die Werte ‚1‘ und ‚2‘ zu erfassen und zusammenzuzählen, etwa auf diesem Weg: COUNT F_S = S_01 (2) . EXECUTE . R_S = S_ (1) . O_S = S_ (0) . S_01 F_S R_S O_S . 1 2
 . EXECUTE . R_S = S_01 (1) . O_S = S_01 (0) . S_01. F_S. R_S. O_S")
73
Um die Summe der F_S, R_S und O_S zusammenzuaddieren gibt es – wie immer – verschiedene Wege. Zunächst müssen die Missing Values in die Werte ‚0‘ umkodiert werden: RECODE F_S R_S O_S (MISSING=0) . EXECUTE . Dann kann mit dem Befehl: CREATE Fall = CSUM(Fall) . CREATE F_S = CSUM(F_S) . CREATE R_S = CSUM(R_S) . CREATE O_S = CSUM(O_S) . oder
 . EXECUTE . Dann kann mit dem Befehl: CREATE Fall = CSUM(Fall) . CREATE F_S = CSUM(F_S) . CREATE R_S = CSUM(R_S) . CREATE O_S = CSUM(O_S) . oder.")
74
IF ($casenum > 1) F_S = LAG(F_S, 1) + F_S . EXECUTE .
Mit der Anweisung: IF ($casenum > 1) F_S = LAG(F_S, 1) + F_S . EXECUTE . gearbeitet werden. Ihnen ist sicher das Aufaddieren einer Variablen ‚Fall‘ aufgefallen – die zuvor auf den Wert ‚1‘ gesetzt wurde. Diese Variable dient dazu, die letzte Zeile in der Datei zu bestimmen, um den Sortierbefehl richtig anwenden zu können. Dieser Befehl lautet: S_01 F_S R_S O_S . 1 2
 F_S = LAG(F_S, 1) + F_S . EXECUTE . gearbeitet werden. Ihnen ist sicher das Aufaddieren einer Variablen ‚Fall‘ aufgefallen – die zuvor auf den Wert ‚1‘ gesetzt wurde. Diese Variable dient dazu, die letzte Zeile in der Datei zu bestimmen, um den Sortierbefehl richtig anwenden zu können. Dieser Befehl lautet: S_01. F_S. R_S. O_S")
75
SORT CASES BY Fall (D) . SELECT IF ($casenum = 1) . EXECUTE . Mit der ersten Zeile werden die Werte von Fall absteigend (D) sortiert, so dass die höchsten Werte alle in der ersten Zeile stehen. Dann wird die erste Zeile ausgewählt – die anderen sind in diesem Moment verschwunden! Die gewünschte Berechnung erfolgt durch diesen Befehl: COMPUTE Proz_F = (100 * F_S) / (F_S + R_S) . Damit haben wir den Prozentanteil der Fehler beim Bearbeiten der ersten Zeile der Spalte S_01 berechnet.
 sortiert, so dass die höchsten Werte alle in der ersten Zeile stehen. Dann wird die erste Zeile ausgewählt – die anderen sind in diesem Moment verschwunden! Die gewünschte Berechnung erfolgt durch diesen Befehl: COMPUTE Proz_F = (100 * F_S) / (F_S + R_S) . Damit haben wir den Prozentanteil der Fehler beim Bearbeiten der ersten Zeile der Spalte S_01 berechnet.")
76
Damit ist aber noch nicht das Ende erreicht
Damit ist aber noch nicht das Ende erreicht. Um zu markieren, welchen Wert wir jetzt berechnet haben, nennen wir die Variable Proz_F um in die Variable ProzF_S_01 – die Variable Proz_F ist damit nicht mehr im Bestand der Datei!! Schließlich speichern wir in einer Zwischendatei den berechneten Wert und werfen mit DROP alle Variablen raus, die wir nicht benötigen: RENAME VARIABLES (Proz_F = !CONCAT(ProzF_, !Spalte)) . EXECUTE . MATCH FILES /FILE=* /FILE='SPEICHER02.sav' /DROP = Id, Fall, R_S, O_S, F_S, !Spalte . SAVE OUTFILE='SPEICHER02.sav' .
) . EXECUTE . MATCH FILES /FILE=* /FILE= SPEICHER02.sav /DROP = Id, Fall, R_S, O_S, F_S, !Spalte . SAVE OUTFILE= SPEICHER02.sav .")
Ähnliche Präsentationen








>")

>")




 mit unterschiedlichen Datentypen (im Gegensatz zu Feldern) zusammengefaßt.>")

 Prof. Th. Ottmann.>")



