Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Referentin: Stefanie Jahn SS 2007
Clusteranalyse Referentin: Stefanie Jahn SS 2007

2
1. Problemstellung Analyse einer heterogenen Gesamtheit von Objekten
Ziel: homogene Teilmengen von Objekten aus der Objektgesamtheit identifizieren Clusteranalyse verfügt über verschiedene Verfahren zur Gruppenbildung

3
Vorüberlegungen Anzahl der Objekte muss bei Stichproben repräsentativ sein Ausreißer ausschließen/ eliminieren nur relevante Merkmale berücksichtigen Gleichgewichtung der Merkmale -> Korrelationen wegen Verzerrungsgefahr ausschließen keine konstanten Merkmale in der Ausgangsmatrix -> Verzerrungsgefahr Vergleichbarkeit durch Standardisierung der Variablen bei unterschiedl. Skalenniveaus der Ausgangsdaten

4
Fehlende Werte Datensatz sollte von fehlenden Werten bereinigt sein Ausschluß von: - Variablen mit großer Anzahl fehlender Werte - Fällen mit fehlenden Werten für Variablen -> Problem: Reduktion der Fallzahl fehlende Werte durch Mittelwert ersetzen -> Problem: Ereignisverzerrung bei zu häufigem Auftreten

5
2. Vorgehensweise 2.1. Ähnlichkeitsermittlung
Binäre Variablenstruktur Metrische Variablenstruktur Gemischt skalierte Variablenstruktur 2.2. Auswahl des Fusionierungsalgorithmus Partitionierende Verfahren Hierarchische Verfahren 2.3. Bestimmung der Clusterzahl

6
2.1. Ähnlichkeitsermittlung
Ausgangspunkt: Rohdatenmatrix mit K Objekten, die durch J Variablen beschrieben werden Matrix enthalt Proximitätsmaße (= Ähnlichkeits- und Unähnlichkeits-maße)
")
7
2.1.1. Binäre Variablenstruktur
Paarvergleich: für 2 Objekte werden Eigenschaftsausprägungen miteinander verglichen

8
Tanimoto-, RR- und M-Koeffizient

9
Verwendung: wenn das Nichtvorhandensein eines Merkmals relevant ist (z.B. bei Geschlecht: 1=männlich, 0=weiblich), dann Verwendung von z.B. M-Koeffizient wenn das Nichtvorhandensein eines Merkmals nicht relevant ist, dann eher Tendenz zu Tanimoto- bzw. Jaccard-Koeff.
, dann Verwendung von z.B. M-Koeffizient. wenn das Nichtvorhandensein eines Merkmals nicht relevant ist, dann eher Tendenz zu Tanimoto- bzw. Jaccard-Koeff.")
10
Verwendung der Ähnlichkeitskoeffizienten bei mehrstufigen Variablen:

11
2.1.2. Metrische Variablenstruktur
Minkowski-Metriken bzw. L-Normen weit verbreitete Distanzmaße Differenz zwischen den Eigenschaften der Objektpaare dividiert durch absolute Differenzwerte

12
r=1 - City-Block-Metrik: = I1-2I+I2-3I+I1-3I = 1+1+2 = 4
bei der L1-Norm gehen alle Differenzwerte gleichgewichtig in die Berechnung ein = größte Ähnlichkeit; = größte Unähnlichkeit

13
r=2 - Euklidische Distanz: = I1-2I2+I2-3I2+I1-3I2 = 12+12+22 = 6
stärkere Berücksichtigung großer Differenzwerte durch das Quadrieren

14
Resultat: Wahl des Distanzmaßes beeinflusst Ähnlichkeitsreihenfolge der Untersuchungsobjekte
wichtig: vergleichbare Maßeinheiten müssen zugrunde liegen -> sonst Standardisierung!

15
Q-Korrelations-koeffizient
berechnet die Ähnlichkeit zwischen 2 Objekten unter Berücksichtigung aller Variablen eines Objektes = größte Ähnlichkeit; = größte Unähnlichkeit

16
Warum ist Rama und Weihnachtsbutter nach der Minkowski-Metrik am unähnlichsten, aber nach dem Q-Korrelationskoeffizienten am ähnlichsten? Verwendung von Distanzmaßen, wenn der absolute Abstand zw. Objekten interessiert und Unähnlichkeit steigt mit der zunehmenden Distanz -> z.B. ähnliche Umsatzgröße/-höhe im Zeitverlauf Verwendung von Ähnlichkeitsmaßen, wenn es um den Ähnlichkeitsaspekt im Gleichlauf zweier Profile geht, unabhängig vom Niveau -> z.B. ähnliche Umsatzentwicklungen im Zeitverlauf

17
2.1.3. Gemischt skalierte Variablenstruktur
A) für die metrischen und nicht-metrischen Variablen werden die Ähnlichkeitskoeffizienten bzw. Distanzen getrennt berechnet Gesamtähnlichkeit = ungewichteter oder gewichteter Mittelwert der berechneten Größen
 für die metrischen und nicht-metrischen Variablen werden die Ähnlichkeitskoeffizienten bzw. Distanzen getrennt berechnet. Gesamtähnlichkeit = ungewichteter oder gewichteter Mittelwert der berechneten Größen.")
18
z.B.: Rama und Flora: M-Koeffizient Distanz = 1-0,7 = 0,3 bei den metr. Eigenschaften quadrierte euklidische Distanz = 4 => ungewichtetes arithmet. Mittel: 2,15 => Gewichtung nach metr. und nicht-metr. Abstand

19
B) Transformation von einem höheren in ein niedrigeres Skalenniveau
Dichotomisierung: Preis bis zu 1,59€ = 0, ab 1,60€ = 1 = hoher Info-verlust, willkürl. Festlegung der Schnittstelle? Intervalle bilden oder: Preis teurer als 1,40 €? ja = 1, nein = 0 Preis teurer als 1,70 €? ja = 1, nein = 0… je kleiner die Klassenspanne, desto geringer der Info-verlust Verzerrungsgefahr durch falsche Gewichtung

20
2.2. Auswahl des Fusionierungsalgorithmus
Zusammenfassung zu Gruppen aufgrund der Ähnlichkeitswerte die (agglomerative) Clusteranalyse fasst die betrachteten Fälle so lange zusammen, bis alle Fälle am Ende in einer Gruppe enthalten sind mögliche Unterscheidung von partitionierenden Verfahren hierarchische Verfahren
 Clusteranalyse fasst die betrachteten Fälle so lange zusammen, bis alle Fälle am Ende in einer Gruppe enthalten sind. mögliche Unterscheidung von. partitionierenden Verfahren. hierarchische Verfahren.")
21
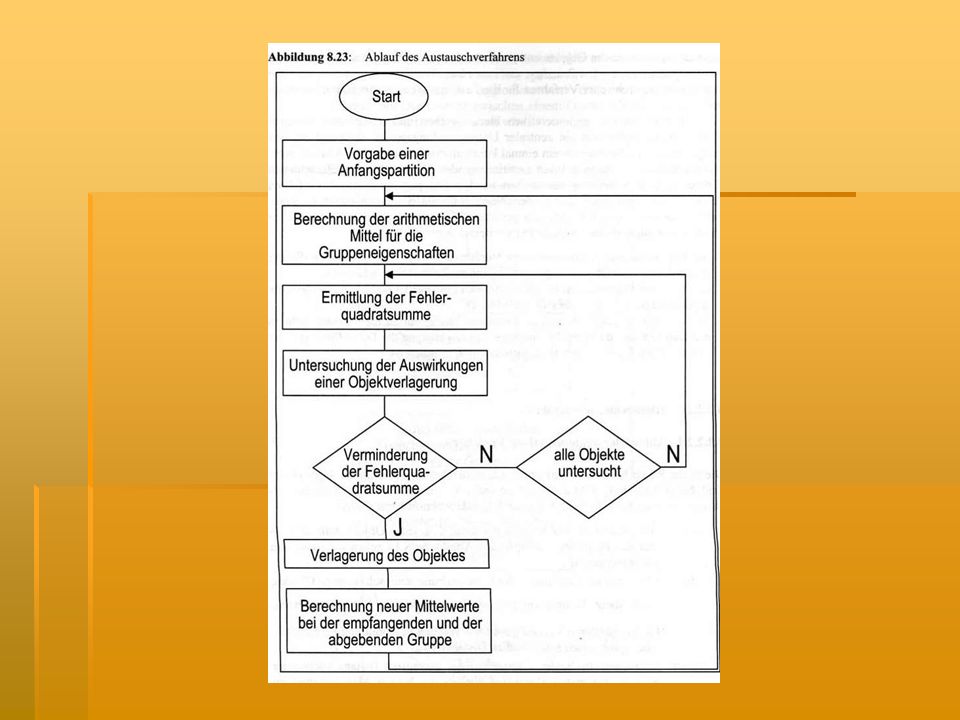
2.2.1. Partitionierende Verfahren
vorgegebene Gruppeneinteilung gehen von einer gegebenen Gruppierung der Objekte aus Umordnung mit Hilfe eines Austauschalgorithmus zwischen den Gruppen bis zum Optimum

23
Beenden der Clusterung, wenn alle Objekte bezügl
Beenden der Clusterung, wenn alle Objekte bezügl. ihrer Verlagerung untersucht wurden und sich keine Verbesserung des Varianzkriteriums mehr erreichen lässt -> Abbruch muss erfolgen, sonst zu viele Möglichkeiten -> lokales Optima erreicht statt globales Optima 2 Entscheidungsprobleme bei „Veränderung der Startpartition“: 1. Festlegen, auf wie viele Gruppen die Objekte verteilt werden sollen 2. Festlegen des Modus, nach dem die Objekte auf die Startgruppen zu verteilen sind (per Zufallszahlentabelle, entsprechend der Reihenfolge ihrer Nummerierung,…)
")
24
partitionierende Verfahren zeichnen sich durch größere Variabilität aus gegenüber agglomerativen hierarchischen Verfahren partitionierende Verfahren sind in praktischen Anwendungen geringer verbreitet Gründe: - Ergebnisse werden verstärkt durch die Zielfunktion beeinflusst - die häufig subjektive Begründung der Wahl der Startposition kann Ergebnis beeinflussen - nur lokales Optima erreichbar

25
2. 2. 2. Hierarchische Verfahren 2. 2. 2. 1
Hierarchische Verfahren Ablauf der agglomerativen Verfahren agglomerative Verfahren - feinste Partition ist Ausgangspunkt -> Zusammenfassung von Gruppen

26
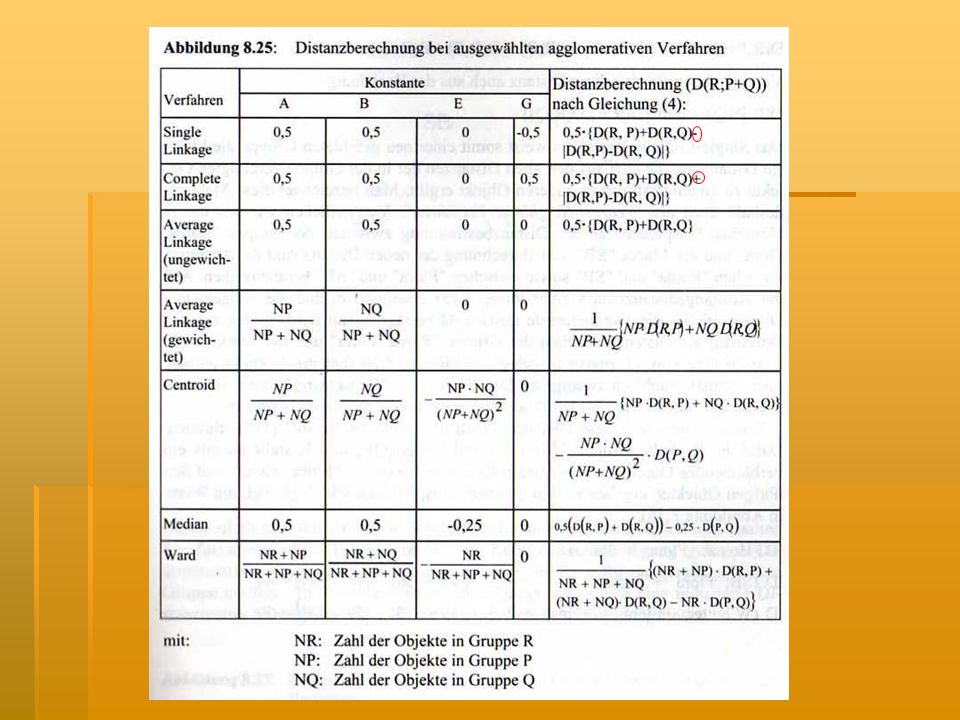
Unterschiede zw. den aggl
Unterschiede zw. den aggl. Verfahren ergeben sich nur daraus, wie Distanzen ermittelt werden Distanz zw. Objekten P+Q zu irgendeiner Gruppe R: D(R,P+Q) = A * D(R,P) + B * D(R,Q) + E * D(P,Q) + G * ID(R;P)-D(R,Q)I mit: D(R,P): Distanz zwischen den Gruppen R und P D(R,Q): Distanz zwischen den Gruppen R und Q D(P,Q): Distanz zwischen den Gruppen P und Q
 = A * D(R,P) + B * D(R,Q) + E * D(P,Q) + G * ID(R;P)-D(R,Q)I mit: D(R,P): Distanz zwischen den Gruppen R und P D(R,Q): Distanz zwischen den Gruppen R und Q D(P,Q): Distanz zwischen den Gruppen P und Q.")
28
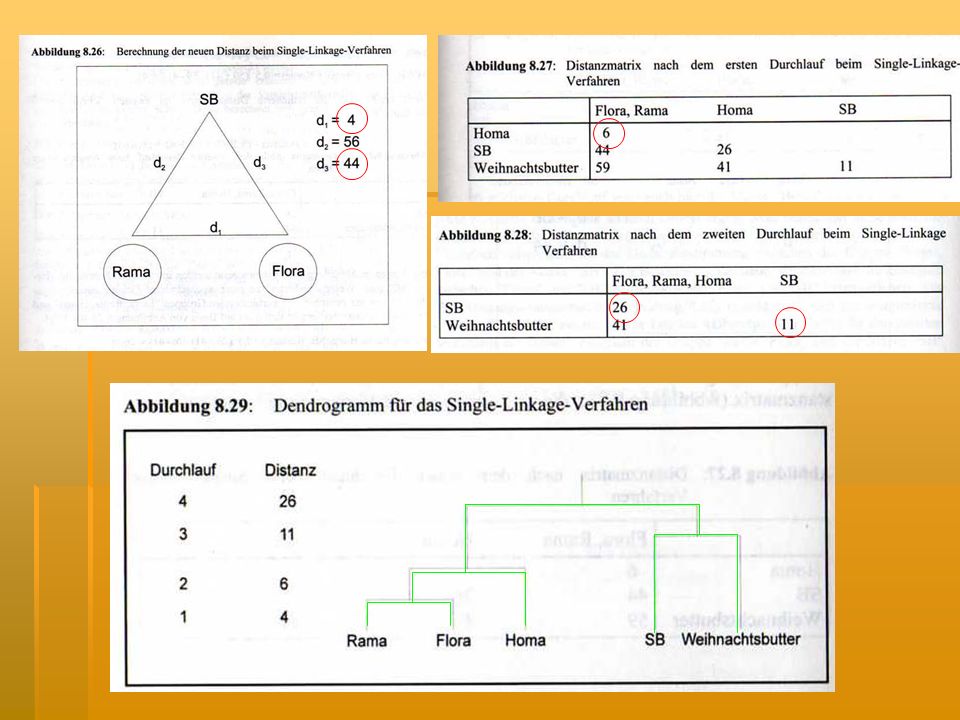
vereinigt die Objekte, die die kleinste Distanz aufweisen
Vorgehensweise der Verfahren „Single-Linkage“, „Complete-Linkage“ und „Ward“ Single-Linkage-Verfahren vereinigt die Objekte, die die kleinste Distanz aufweisen Nearest-Neighbour-Verfahren SLV zieht als neue Distanz zwischen zwei Gruppen immer den kleinsten Wert der Einzeldistanzen heran -> ist dadurch geeignet, „Ausreißer“ zu erkennen neigt dazu, viele kleine und wenig große Gruppen zu bilden -> Tendenz zur Kettenbildung

30
Complete-Linkage-Verfahren
die größten Abstände werden als Distanzen herangezogen = Furthest-Neighbour-Verfahren Abstand entspricht jetzt dem größten Einzelabstand

31
tendiert eher zur Bildung kleiner Gruppen
nicht zur Entdeckung von „Ausreißern“ geeignet, aufgrund der Verwendung der größten Distanzen der Einzelwerte

32
Ward-Verfahren Ziel: Vereinigung derjenigen Objekte, die die Streuung einer Gruppe möglichst wenig erhöhen -> dadurch Bildung möglichst homogener Cluster als Heterogenitätsmaß wird Varianzkriterium verwendet = Fehlerquadratsumme (FQS) Berechnung der quadr. euklid. Distanz zwischen allen Objekten FQS im ersten Schritt = 0, da jedes Obj. eigene Gruppe -> noch keine Streuung
 Berechnung der quadr. euklid. Distanz zwischen allen Objekten. FQS im ersten Schritt = 0, da jedes Obj. eigene Gruppe -> noch keine Streuung.")
33
4*0,5 = 2 (=FQS) 6,667*0,5 = 3,333 3,333+2 = 5,333 11*0,5 = 5,5 5,5+5,333 = 10,833
 6,667*0,5 = 3,333 3,333+2 = 5,333 11*0,5 = 5,5 5,5+5,333 = 10,833")
34
Ward-Verfahren verwendet ein Distanzmaß Variablen müssen metrisch sein keine Ausreißer unkorrelierte Variablen wichtig Erwartung gleich großer Gruppen !!! lang gestreckte Gruppen oder Gruppen mit kleiner Elementzahl nicht erkennbar !!! Empfehlung: - zuerst SLV zum Finden von Ausreißern - Ausreißer „eliminieren“ - reduzierte Objektmenge erneut untersuchen mit einem anderen agglomerativen Verfahren - Auswahl des Verfahrens hat vor dem Hintergrund der jew. Anwendungssituation zu erfolgen

35
2.3. Bestimmung der Clusterzahl
Entscheidung, welche Clusteranzahl „beste“ Lösung ist und verwendet werden soll Lösen des Zielkonflikts zwischen Handhabbarkeit und Homogenitätsanforderung Bestimmung der Clusterzahl sollte nach statistischen Kriterien erfolgen, nicht nach sachlogischen Überlegungen zur Unterstützung der Entscheidung kann die Entwicklung des Heterogenitätsmaßes betrachtet werden (-> ist beim Ward-Verfahren die Fehlerquadratsumme) graphische Verdeutlichung liefert Dendrogramm
 graphische Verdeutlichung liefert Dendrogramm.")
36
Heterogenitätsentwicklung wird gegen die zugehörige Clusterzahl in einem Koordinatensystem abgetragen -> 4-Cluster-Lösung

37
Literatur Backhaus, Klaus u.a. (2003): Multivriate Analysemethoden. Eine Anwendungsorientierte Einführung, Berlin. Jahnke, Hermann: Clusteranalyse als Verfahren der schließenden Statistik, Göttingen. Bacher, J. (1994): Clusteranalyse. Anwendungsorientierte Einführung, München Wien.
: Clusteranalyse. Anwendungsorientierte Einführung, München Wien.")
Ähnliche Präsentationen






 Prof. Th. Ottmann.>")










 findet heute um 14:30 Uhr im Hörsaal Loefflerstraße 70 statt.>")
 (hier z. B. die Klausur-Noten von 50 Studenten) 3 3 4 5 2 1 3 3 4 3 2 3 4 4 4 5 2 1 3 3 3 3 4 4 4 5.>")
