Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Volltextsuchmaschinen, © Till Hänisch 2001 Altavista, Google & Co Volltextsuche im Großen, aber wie ?

2
Volltextsuchmaschinen, © Till Hänisch 2001 So ? Wo wird gesucht ? lokal Wie wird gesucht ? sequentiell Suche wird Datei für Datei durchgeführt, jeweils Wort für Wort durchsucht Sinnvoll wenn: - schneller Zugriff (Festplatte) - Wenige Daten (Megabyte)
 - Wenige Daten (Megabyte).")
3
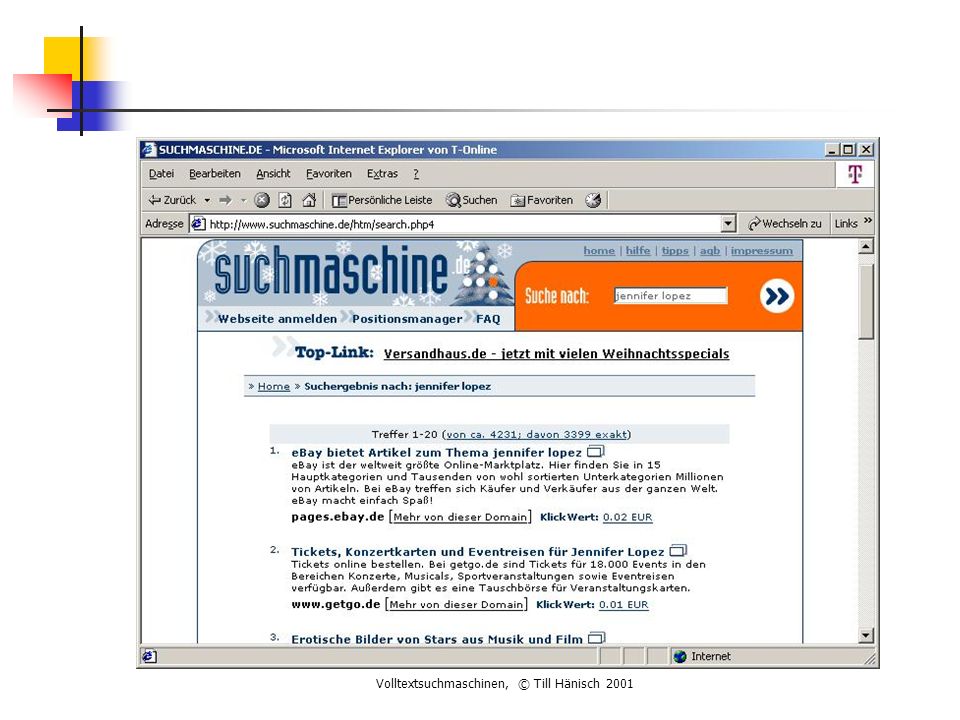
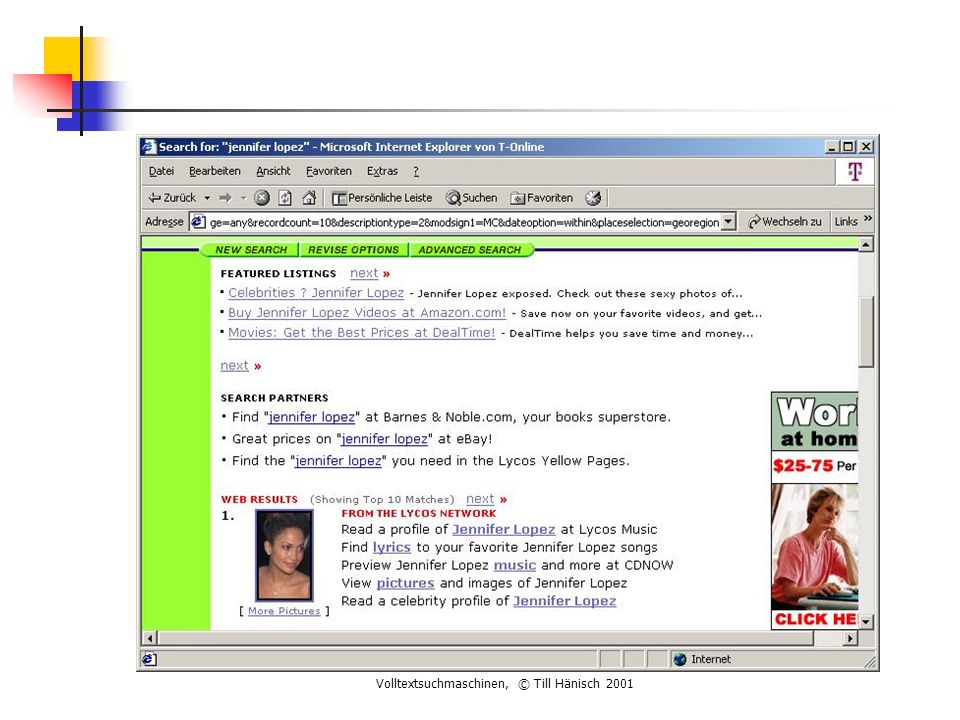
Volltextsuchmaschinen, © Till Hänisch 2001 Funktioniert nicht, weil.... Netzverbindung viel zu langsam Lokale Kopie aller Seiten Speicherplatz Datenbestand viel zu groß Viele GB bis TB Sequentielle Suche selbst auf extrem schnellem Rechner viel zu langsam (viele Anfragen,...) Index (analog Buch) Sortierung der Treffer (Ranking) Suche nach z.B. Jennifer Lopez liefert mehrere hunderttausend Treffer, welche sollen als erste dargestellt werden ?
 Index (analog Buch) Sortierung der Treffer (Ranking) Suche nach z.B. Jennifer Lopez liefert mehrere hunderttausend Treffer, welche sollen als erste dargestellt werden .")
4
Volltextsuchmaschinen, © Till Hänisch 2001 Architektur Internet Spider/ Crawler/ Gatherer IndexProzessor Browser Lädt Seiten von (allen) Webservern in regelmäßigen Abständen, z.B. monatlich Wie ? Analog Buch, Suchzeit steigt nicht linear, sondern logarith- misch mit der Größe des Daten- bestands Anfragebearbeitung, Ranking, Caching,...

5
Volltextsuchmaschinen, © Till Hänisch 2001 Crawler Auch Gatherer, Spider, Robot Wie kommen die Seiten zur Suchmaschine ? Manuell: Anmeldung von Seiten Automatisch: Crawler „durchsucht“ das Web Woher kennt die Suchmaschine die Webserver ? Links DNS Ausgehend von Startpunkt(en) folgt der Crawler allen Links (netio + HTML-Parser + DB mit bisher besuchten Links) Einfach ? For example, our system tried to crawl an online game,... Simple to solve... But this problem had not come up until we had downloaded tens of millions of pages
 folgt der Crawler allen Links (netio + HTML-Parser + DB mit bisher besuchten Links) Einfach . For example, our system tried to crawl an online game,... Simple to solve... But this problem had not come up until we had downloaded tens of millions of pages.")
6
Volltextsuchmaschinen, © Till Hänisch 2001 Metadaten Was wird indiziert ? Zunächst nur erste paar hundert Byte (Titel,...) Volltext Enthält alle Informationen Aber auch viel „Rauschen“ Große Datenmenge Metadaten (Titel, Autor, Stichworte,...) Sind meist relevanter Weniger Daten Wie erkennt der Crawler die Metadaten in den HTML- Seiten ? Dublin Core Meta-Tags
 Volltext Enthält alle Informationen Aber auch viel „Rauschen Große Datenmenge Metadaten (Titel, Autor, Stichworte,...) Sind meist relevanter Weniger Daten Wie erkennt der Crawler die Metadaten in den HTML- Seiten . Dublin Core Meta-Tags.")
7
Volltextsuchmaschinen, © Till Hänisch 2001 Index Text1.txt Der Mond ist aufgegangen Text2.txt Festgemauert in der Erden Text Index aufgegangenText1 derText1, Text2 ErdenText2 festgemauertText2 inText2 MondText1 Der Index enthält (in geeigneter Weise sortiert) alle vorkommenden Wörter sowie Verweise, in welchen Dokumenten diese vorkommen (ggf. auch, an welcher Stelle) Real: Index ist nicht sortierte Liste (schlechte Performance beim Einfügen/Löschen von Einträgen) sondern i.A. Baum, Hash,... (siehe Datenstrukturen)
 Real: Index ist nicht sortierte Liste (schlechte Performance beim Einfügen/Löschen von Einträgen) sondern i.A. Baum, Hash,... (siehe Datenstrukturen).")
8
Volltextsuchmaschinen, © Till Hänisch 2001 Index contd. Schreibweise I.a. normalisierte Schreibweise (nur Kleinbuchstaben, Umlaute auf ASCII abgebildet,...) Ggf. zweiter Index mit exakter Scheibweise Organisation in Baumstruktur Sortierte Liste Binäre Suche: effizient, aber hoher Speicherbedarf, wenn nicht im RAM langsam Baum bleibt effizient, auch wenn nur Teil (obere Ebenen) im RAM Vereinfacht Implementierung von Transaktionen (da – meistens - nur jeweils ein Knoten geändert wird) Platzbedarf Index belegt – je nach Implementierung – etwa 5-200% des Volumens des Originals Kompression (z.B. Frontcoding,...)
 Ggf. zweiter Index mit exakter Scheibweise Organisation in Baumstruktur Sortierte Liste Binäre Suche: effizient, aber hoher Speicherbedarf, wenn nicht im RAM langsam Baum bleibt effizient, auch wenn nur Teil (obere Ebenen) im RAM Vereinfacht Implementierung von Transaktionen (da – meistens - nur jeweils ein Knoten geändert wird) Platzbedarf Index belegt – je nach Implementierung – etwa 5-200% des Volumens des Originals Kompression (z.B. Frontcoding,...).")
9
Volltextsuchmaschinen, © Till Hänisch 2001 Indexarchitektur in real life Lexikon enthält Begriffe und Verweis auf Liste der zugehörigen URLs Diese (Barrels) sind (Ranking) vorsortiert
 sind (Ranking) vorsortiert")
10
Volltextsuchmaschinen, © Till Hänisch 2001 Wildcards Index aufgegangenText1 derText1, Text2 ErdenText2 festgemauertText2 inText2 MondText1 Suche nach auf* mit sortiertem Index kein Problem Suche nach *gegangen ? Mehrere Lösungen (zusätzliche Indices): N-Gram, rotierter Index Digram: Wort wird in zwei-Buchstaben-Paare zerlegt, z.B. Erden Er,rd,de,en (zus. evtl noch $E,n$ für Wortbeginn und Ende), diese werden indiziert. Suchbegriff wird ebenfalls zerlegt, bei Suche nach Erd* wird nach „$e AND er AND rd“ gesucht (Achtung: Falsche Treffer (z.B. „Elenderdepp“ müssen aussortiert werden) Rotierter Index: Es wird nicht nur $Erden$, sondern auch rden$$E, den$$Er, en$$Erd, n$$Erde indiziert. Suche nach *rden, oder auch Er*en möglich (Erlaubt aber nur ein Wildcard – manche Suchmaschinen unterstützen deshalb nicht Queries mit mehreren Wildcards)
: N-Gram, rotierter Index Digram: Wort wird in zwei-Buchstaben-Paare zerlegt, z.B. Erden Er,rd,de,en (zus. evtl noch $E,n$ für Wortbeginn und Ende), diese werden indiziert. Suchbegriff wird ebenfalls zerlegt, bei Suche nach Erd* wird nach „$e AND er AND rd gesucht (Achtung: Falsche Treffer (z.B. „Elenderdepp müssen aussortiert werden) Rotierter Index: Es wird nicht nur $Erden$, sondern auch rden$$E, den$$Er, en$$Erd, n$$Erde indiziert. Suche nach *rden, oder auch Er*en möglich (Erlaubt aber nur ein Wildcard – manche Suchmaschinen unterstützen deshalb nicht Queries mit mehreren Wildcards).")
11
Volltextsuchmaschinen, © Till Hänisch 2001 Bool‘sche Suchen AND OR Implementierung: Für jeden Term wird eine Query ausgeführt, die Ergebnislisten werden verknüpft z.B. Text AND Suche AND Index Liefert Ergebnisse (Dokumentnummern) Text(2,47,568,1324,34567) Suche(3,32,568,2456,21347,34567) Index(124,178,3124,11111,34567,67892) In allen dreien kommt nur Dokument 34567 vor Performance: Je Term eine Query, Verknüpfung bei vielen Treffern, „Text AND Retrieval AND Index“ würde evtl. mehr Dokumente liefern, die auch passen, besser Text AND (Suche OR Retrieval) AND Index,...
 Text(2,47,568,1324,34567) Suche(3,32,568,2456,21347,34567) Index(124,178,3124,11111,34567,67892) In allen dreien kommt nur Dokument vor Performance: Je Term eine Query, Verknüpfung bei vielen Treffern, „Text AND Retrieval AND Index würde evtl. mehr Dokumente liefern, die auch passen, besser Text AND (Suche OR Retrieval) AND Index,....")
12
Volltextsuchmaschinen, © Till Hänisch 2001 Recall/Precision Recall: Sind alle relevanten Dokumente in der Ergebnismenge ? Precision: Sind alle Dokumente der Ergebnismenge relevant ? Widerspruch, hoher Recall niedrige Precision u.U. 100 % Recall Precision z.B. boolean queries: Text AND Suche AND Index: Hohe Precision, niedriger recall...(Suche OR Retrieval OR Treffer)...: recall höher, precision niedriger Bei bool‘schen Queries binäre Logik (Treffer oder nicht) relevante Ergebnisse nicht im Ergebnis (z.B. ein Term fehlt) recall immer < 100 % (Precision optimiert)
...: recall höher, precision niedriger Bei bool‘schen Queries binäre Logik (Treffer oder nicht) relevante Ergebnisse nicht im Ergebnis (z.B. ein Term fehlt) recall immer < 100 % (Precision optimiert).")
13
Volltextsuchmaschinen, © Till Hänisch 2001 Ranking Ergebnis enthält immer alle Dokumente Recall == 100 % Die meisten sind irrelevant Precision 0 % Gut oder schlecht ? Gut, wenn Ergebnisse nach Relevanz sortiert (Benutzer kann Precision einstellen – die ersten Ergebnisse haben hohe Precision, liest er alle, hat er hohen recall) Aber wie ? Maß für Relevanz nötig z.B. Coordinate matching: Anzahl der im Dokument enthaltenen Terme dient als Maß (enthält ein Dokument alle gesuchten Terme, erscheint es „oben“, enthält es nur einen, dann „unten“ in Liste (analog etwa: oben AND, unten OR) Formal: Inneres Produkt zwischen Query- und Dokument-Vektor
 Aber wie . Maß für Relevanz nötig z.B. Coordinate matching: Anzahl der im Dokument enthaltenen Terme dient als Maß (enthält ein Dokument alle gesuchten Terme, erscheint es „oben , enthält es nur einen, dann „unten in Liste (analog etwa: oben AND, unten OR) Formal: Inneres Produkt zwischen Query- und Dokument-Vektor.")
14
Volltextsuchmaschinen, © Till Hänisch 2001 Vektorraummodelle DocaufgegangenDerErdenfestgemauertinMond 1110001 2011110 Q010001 R 1 =2, R 2 =1 Probleme: „Der“ (kommt in praktisch jedem Dokument vor) ist genauso wichtig wie „Mond“ (ziemlich selten) Terme, die in einem Dokument mehrfach vorkommen, werden nur einmal gezählt Lange Dokumente, die viele Terme enthalten (Bibel, Wörterbuch,...) werden immer ziemlich hoch gewichtet Lösung: Gewichtung mit z.B. Anzahl im Dokument f d,t, Gesamt- häufigkeit des Terms 1/f t (in allen Dokumenten oder in einem)
.")
15
Volltextsuchmaschinen, © Till Hänisch 2001 Vektorraummodelle contd. z.B. Viele komplexe Verfahren (in der Literatur), gemeinsam: 1.Term, der in wenigen Dokumenten auftaucht, ist wichtiger als einer, der in vielen auftaucht 2.Dokument, das Term mehrfach enthält, ist wichtiger, als eines, das den Term nur einmal enthält Dokument(e) und Query sind Vektoren, allg. Maß für Ähnlichkeit ? Richtung !! Aber wie ?
, gemeinsam: 1.Term, der in wenigen Dokumenten auftaucht, ist wichtiger als einer, der in vielen auftaucht 2.Dokument, das Term mehrfach enthält, ist wichtiger, als eines, das den Term nur einmal enthält Dokument(e) und Query sind Vektoren, allg. Maß für Ähnlichkeit . Richtung !. Aber wie .")
16
Volltextsuchmaschinen, © Till Hänisch 2001 Implementierungen Details werden i.A. nicht publiziert !! Indextechnologie oft ähnlich (Lexikon+Dokumentliste), Unterschiede bei Erstellung, Ranking,... Altavista Erste "große" Suchmaschine Optimiert auf Geschwindigkeit klass. Volltextretrieval von Digital finanziert (Eigenwerbung für Hardware) Details nicht publiziert heute auch "intelligenteres" ranking lucene Doug Cutting (Xerox, Excite) Open source Volltextretrieval, Bool'sche Queries
, Unterschiede bei Erstellung, Ranking,... Altavista Erste große Suchmaschine Optimiert auf Geschwindigkeit klass. Volltextretrieval von Digital finanziert (Eigenwerbung für Hardware) Details nicht publiziert heute auch intelligenteres ranking lucene Doug Cutting (Xerox, Excite) Open source Volltextretrieval, Bool sche Queries.")
17
Volltextsuchmaschinen, © Till Hänisch 2001 Google Vor google und seit google Precision optimiertes Ranking Suche im Volltext, Ranking nach Links Wieviele Links verweisen auf eine Seite Was steht im Anchor Text drin ? PageRank We assume page A has pages T1...Tn which point to it (i.e., are citations). The parameter d is a damping factor which can be set between 0 and 1. We usually set d to 0.85. There are more details about d in the next section. Also C(A) is defined as the number of links going out of page A. The PageRank of a page A is given as follows: PR(A) = (1-d) + d (PR(T1)/C(T1) +... + PR(Tn)/C(Tn)) Note that the PageRanks form a probability distribution over web pages, so the sum of all web pages' PageRanks will be one.
. The parameter d is a damping factor which can be set between 0 and 1. We usually set d to There are more details about d in the next section. Also C(A) is defined as the number of links going out of page A. The PageRank of a page A is given as follows: PR(A) = (1-d) + d (PR(T1)/C(T1) PR(Tn)/C(Tn)) Note that the PageRanks form a probability distribution over web pages, so the sum of all web pages PageRanks will be one..")
18
Volltextsuchmaschinen, © Till Hänisch 2001

25
Tricks of the trade Caching Großer Teil der Anfragen betrifft nur wenige Queries („leer“ (!), Tagesgeschehen, „Sex“,..) Query wird einmal durchgeführt und immer wieder ausgegeben Werbung Wer finanziert die Suchmaschinen ? Werbekunden Hersteller von Hard- und Software (z.B. AltaVista) Sollen „gute“ Kunden immer unten in Trefferlisten auftauchen ? Wie funktioniert Ranking ? Häufigkeiten, Gewichtung (Metadaten,...) Was tut Webmaster, der weit oben plaziert werden möchte ? Tricks und Gegentricks
 Sollen „gute Kunden immer unten in Trefferlisten auftauchen . Wie funktioniert Ranking . Häufigkeiten, Gewichtung (Metadaten,...) Was tut Webmaster, der weit oben plaziert werden möchte . Tricks und Gegentricks.")
26
Volltextsuchmaschinen, © Till Hänisch 2001 Zusammenfassung Information retrieval (60'er Jahre) Volltext, Bool'sche Queries typ. (hundert) tausende Dokumente, Gigabytes Web-Suchmaschinen (ca. 1995) Volltext, Bool'sche Queries (viele) Millionen Dokumente Ranking nach klass. Verfahren (Coordinate matching, Vektorraummodelle,...) "Intelligente" Suchmaschinen (1997) Volltext, Web-spezifische Ranking Verfahren (Page rank) Zukunft ?
 tausende Dokumente, Gigabytes Web-Suchmaschinen (ca. 1995) Volltext, Bool sche Queries (viele) Millionen Dokumente Ranking nach klass. Verfahren (Coordinate matching, Vektorraummodelle,...) Intelligente Suchmaschinen (1997) Volltext, Web-spezifische Ranking Verfahren (Page rank) Zukunft .")
27
Volltextsuchmaschinen, © Till Hänisch 2001 And beyond Literatur Witten, Moffat, Bell, „Managing Gigabytes“, Morgan Kaufmann, 1999 Sergey Brin, Lawrence Page, „The Anatomy of a search engine“, http://www7.scu.edu.au/programme/fullpapers/1921/com1921.htm http://www7.scu.edu.au/programme/fullpapers/1921/com1921.htm Textmining Bayes Netze bedingte Wahrscheinlichkeiten Autonomy, Office-Assistent, Smart Tags,.net Agenten

Ähnliche Präsentationen