Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
DATA WAREHOUSE Oracle Data Warehouse Mit Big Data neue Horizonte für das Data Warehouse ermöglichen Alfred Schlaucher, Detlef Schroeder DATA WAREHOUSE

2
Themen Big Data Buzz Word oder eine neue Dimension und Möglichkeiten
Oracles Technologie zu Speichern von unstrukturierten und teilstrukturierten Massendaten Cloudera Framwork „Connectors“ in die neue Welt Oracle Loader for Hadoop und HDFS Big Data Appliance Mit Oracle R Enterprise neue Analyse-Horizonte entdecken Big Data Analysen mit Endeca

3
Themen Anforderungen Warum R Die R-Entwicklungsumgebung
Oracle R- Enterprise Der transparente Tabellen-Zugriff Statistische Analysen mit R in der Datenbank Visualisierung von Ergebnissen (Plotting) Visualisierung von Ergebnissen (OBIEE) Einbinden in umfangreiche Analyse-Szenarien
 Visualisierung von Ergebnissen (OBIEE) Einbinden in umfangreiche Analyse-Szenarien.")
4
Anforderungen: Schnellere und elegantere Analyse-Abläufe
Ressourcen Geringere Latenzen bei der Datenbereitstellung Linerare Skalierung Vorhersehbare Aufwände und Durchsatz The solution for these challenges is a nosql db. Is a key value store. These have been around for 40 years. Were isam on mainframe. Give key value example – give customer key and return customer profile. Nosql database good for app’s where just need simple db requests (key/value lookup, no join’s) [not new: m/f isam, BDB], use a schema defined dynamically at runtime by the application itself, and have extreme scalability requirements What’s new: instead of just creating one index, create many indexes and hash to appropriate one.
 [not new: m/f isam, BDB], use a schema defined dynamically at runtime by the application itself, and have extreme scalability requirements. What’s new: instead of just creating one index, create many indexes and hash to appropriate one.")
5
Anforderungen: Effizienterer und leichterer Umgang mit Daten und Informationen
Leichte Zugänge Mehr Informa- tionen Weniger Datenbewegung Flexiblere Tools und flexibler Datenaustausch Mehr Gesamtunternehmens- daten in der Analyse Ressourcen

6
Versteckte Beziehungen entdecken R Statistische Programmiersprache
users sales history returns online PCA 5 Factor 3 Factor 1 Clustering 4 Groups 28 16 2 1 80 60 40 20 OPEN SOURCE Sprache und Umgebung STATISTISCHE BERECHNUNGEN und Graphik STÄRKE liegt in der schnellen graphischen Aufbereitung (Plots) >5,300 statistische Packages LEICHT ERWEITERBAR durch Open Source Community
 >5,300 statistische Packages. LEICHT ERWEITERBAR durch Open Source Community.")
7
Anforderungen: Flexibles Arbeiten
Analysieren integrierter Data Interaktives Arbeiten, Erstellen von Ergebnissen und Weiterverarbeiten Ad Hoc Analysieren Mehr Möglich-keiten Leichte Zugänge User Facts Ressourcen Mehr Informa- tionen

8
Warum nutzen immer mehr Anwender R
Warum R Oft mehr Funktionen, als in klassischen Tools Kann mehr Neue Funktionen, sind oft in R als erstes implemtiert Ist schnell Point Die Entwickler der Funktionen sind oft per Mail direkt erreichbar Ist ansprechbar - offene Kommunikation Weltweit wird mit R gearbeitet “Schläft nicht” Was kosten die übrigen Tools? Ist günstiger

9
Warum sollte man sich für R interessieren
Gehört zu den neuen aufkommenden Trends Next “big thing” in Avanced Analytics Moderne statistische Programmiersprache Ausbildungsinstitute und Universitäten nutzen R für die Ausbildung (Sie ersetzen traditionelle Tools) Advanced Analytics ist zunehmend kritisches Unterscheidungsmerkmal im DWH Technologie Stack R wird durch Oracle R Enterprise skalierbar Kostengünstige Alternative zu SAS
 Advanced Analytics ist zunehmend kritisches Unterscheidungsmerkmal im DWH Technologie Stack. R wird durch Oracle R Enterprise skalierbar. Kostengünstige Alternative zu SAS.")
10
Graphische Bediener-Oberflächen
Live Live Graphische Bediener-Oberflächen Auswahl bei den GUIs Bereiche: R Console Plot-Bereich Ergebnis-Bereich Messages Standard GUI / Rstudio / Rcommander/.../...

11
Daten und Objekte

12
Einfache Beispiele zur Darstellung der Sprachmimik
Live Live Einfache Beispiele zur Darstellung der Sprachmimik > alter <- c(19,20,20,19,25,26,22,25,29) Vektor > geschl <- c(1,2,2,1,2,2,2,1,2) > geschl.faktor <- factor(geschl) Faktor > bsp.data.frame <- data.frame(alter,geschl.faktor) Data-Frame round(tapply(alter ,geschl,mean,na.rm=TRUE),0)
 Vektor. > geschl <- c(1,2,2,1,2,2,2,1,2) > geschl.faktor <- factor(geschl) Faktor. > bsp.data.frame <- data.frame(alter,geschl.faktor) Data-Frame. round(tapply(alter ,geschl,mean,na.rm=TRUE),0)")
13
Daten-Handling Lokale Daten Datenbank class(df)
Live Live Daten-Handling Lokale Daten Datenbank R Engine df <-read.csv(file.choose()) class(df) names(df) objects() dim(df)
) class(df) names(df) objects() dim(df)")
14
Daten-Visualisierung mit R
Live Live Daten-Visualisierung mit R gallery.r-enthusiasts.com/

15
Oracle R Enterprise Oracle Advanced Analytics - Oracle R Enterprise and Oracle Data Mining
R code und/oder SQL Modelle laufen “In-Database” Große Datenmengen Built-in security Schneller The solution for these challenges is a nosql db. Is a key value store. These have been around for 40 years. Were isam on mainframe. Give key value example – give customer key and return customer profile. Nosql database good for app’s where just need simple db requests (key/value lookup, no join’s) [not new: m/f isam, BDB], use a schema defined dynamically at runtime by the application itself, and have extreme scalability requirements What’s new: instead of just creating one index, create many indexes and hash to appropriate one. Sicher Skalierbar
 [not new: m/f isam, BDB], use a schema defined dynamically at runtime by the application itself, and have extreme scalability requirements. What’s new: instead of just creating one index, create many indexes and hash to appropriate one. Sicher. Skalierbar.")
16
Oracle R-Angebote Oracle R Distribution ROracle Oracle R Enterprise
Free download, pre-installed on Oracle Big Data Appliance, bundled with Oracle Linux Enterprise support for customers of Oracle R Enterprise, Big Data Appliance, and Oracle Linux Contribute bug fixes and enhancements to open source R ROracle Open source Oracle database interface driver for R based on OCI Maintainer is Oracle – rebuilt from the ground up Many bug fixes and optimizations Oracle R Enterprise Transparent access to database-resident data from R Embedded R script execution through database managed R engines Statistics engine Oracle R Connector for Hadoop R interface to Oracle Hadoop Cluster on BDA Access and manipulate data in HDFS, database, and file system Write MapReduce functions using R and execute through natural R interface

17
Mögliche Szenarien mit Oracle R-Enterprise
RAM R Engine Direkten Zugriff auf alle Tabellen in der Datenbank RAM File System RAM R Engine Auslagern der Analysen in die Datenbank Zurückholen der Ergebnisse Anlegen neuer Objekte in der Datenbank Parallelisierung durch die Datenbank File System RAM RAM RAM R-Analysen über SQL-Funktionen (Batch) Parallelisierung durch die Datenbank R Engine R Engine SQL R Engine File System R Engine R Engine RAM
 Parallelisierung. durch die Datenbank. R Engine. R Engine. SQL. R Engine. File System. R Engine. R Engine. RAM.")
18
Oracle R Enterprise – Data Sources
R user on desktop R Engine Oracle R Enterprise packages Andere R Packages Direkter Zugriff Direkter Zugriff RODBC, DBI, etc Andere Datenbanken Import / Load Data File systems Push Pull Results SQL R Engine Other R packages Oracle R Enterprise packages Andere R Packages Transparent Layer Parallel Aufrufe Select ...Fro ..Table(....) begin Create Function end User tables Oracle Datenbank Database Links Bulk import External Tables Andere Datenbanken File systems
 begin Create Function end. User tables. Oracle Datenbank. Database Links. Bulk import. External Tables. Andere Datenbanken. File systems.")
19
Transparency Layer Support
ORE bietet eine “in-database execution” – Funktionalität als transparente Schicht an What’s transparent about it? R Benutzte benötigen nur R Syntax Benutzer sehen Datenbank-Objecke as spezielle R Objekte Unterstützt weden fast alle R-Funktionen des Basis-Pakets Unterstützt R's Statistik und Graphik-Pakete Funktional vergleichbar mit SAS DATA STEP, läuft allerdings in- Datenbank!

20
ORE Packages Package Description ORE
Top Level Package for Oracle R Enterprise OREbase Corresponds to R’s base package OREstat Corresponds to R’s stat package OREgraphics Corresponds to R’s graphics package OREeda ORE’s exploratory data analysis package containing SAS PROC-equivalent functionality ORExml ORE’s package supporting XML translation between R and Oracle Database - internal ORHC Oracle R Hadoop Connector ©2012 Oracle – All Rights Reserved

21
Funktionen und Methoden

22
Funktions- und Methodenübersicht
Live Live Funktions- und Methodenübersicht Mathematische Funktionen: abs, sign, sqrt, ceiling, floor, trunc, cummax, cummin, cumprod, cumsum, log, log10, log2, log1p, acos, acosh, asin, asinh, atan, atanh, exp, expm1, cos, cosh, sin, sinh, tan, tanh, gamma, lgamma, digamma, trigamma, round, signif, pmin, pmax, zapsmall Basis Statistik: mean, summary, min, max, sum, any, all, median, range, IQR, fivenum, mad, quantile, sd, var, table, rowSums, colSums, rowMeans, colMeans Rechnen: +, -, *, /, ^, %%, %/% Vergleichen: ==, >, <, !=, <=, >= Logik: &, |, xor Mengenbezogene Abgleiche: unique, %in% Zuweisungen: <-, =, ->

23
Funktions- und Methodenübersicht
Live Live Funktions- und Methodenübersicht Strings: tolower, toupper, casefold, toString, chatr, sub, gsub, substr, substring, paste, nchar Data Frames Kombinieren / Ergänzen: cbind, rbind, merge Combine vectors: append Vector creation: ifelse Subset: [, [[, $, head, tail, window, subset, Filter, na.omit, na.exclude, complete.cases Daten umgruppieren: split, unlist Datenverwalten: eval, with, within, transform Apply Varianten: tapply, aggregate, by Regression: ore.lm() - a variant of lm() Werte-Checks: is.na, is.finite, is.infinite, is.nan Metadaten Funktionen: attributes, nrow, NROW, ncol, NCOL, nlevels, names, row, col, dimnames, dim, length, row.names, col.names, levels, reorder
 - a variant of lm() Werte-Checks: is.na, is.finite, is.infinite, is.nan. Metadaten Funktionen: attributes, nrow, NROW, ncol, NCOL, nlevels, names, row, col, dimnames, dim, length, row.names, col.names, levels, reorder.")
24
Funktions- und Methodenübersicht
Live Live Funktions- und Methodenübersicht Graphik: hist, boxplot, plot, smoothScatter Garbage collection: gc (Löschen von temp. tabellen) Konvertierungen: as.ore.{character, factor, integer, logical, numeric, vector} Test Funktionen: is.ore.{character, factor, integer, logical, numeric, vector} Save: ore.push (table is automatically refreshed in R memory) Hypothesen-Test: wilcox.test, ks.test, var.test, binom.test, chisq.test, t.test, bartlett.test Bessel Funktionen: Bessel(I,J,K,Y) Gamma Funktionen: gamma, lgamma, digamma, trigamma (part of mathematical functions group) Verteilungen: Density, cumulative distribution, and quantile functions for standard distributions Matrix: %*% (matrix multiplication), crossprod (matrix cross-product), tcrossprod (matrix cross-product A times transpose of B)
 Konvertierungen: as.ore.{character, factor, integer, logical, numeric, vector} Test Funktionen: is.ore.{character, factor, integer, logical, numeric, vector} Save: ore.push (table is automatically refreshed in R memory) Hypothesen-Test: wilcox.test, ks.test, var.test, binom.test, chisq.test, t.test, bartlett.test. Bessel Funktionen: Bessel(I,J,K,Y) Gamma Funktionen: gamma, lgamma, digamma, trigamma (part of mathematical functions group) Verteilungen: Density, cumulative distribution, and quantile functions for standard distributions. Matrix: %*% (matrix multiplication), crossprod (matrix cross-product), tcrossprod (matrix cross-product A times transpose of B)")
25
Arbeiten mit Tabellen in der Datenbank

26
Beispiele für den transparenten Zugriff
Live Live Beispiele für den transparenten Zugriff Connect to a specific schema and database One connection active at a time library(ORE) ore.connect("RQUSER","SID","HOST", "PASSWORD",1521) ore.create( ONTIME_S, table = "NEW_ONTIME_S") ore.create( ONTIME_S, view = "NEW_ONTIME_S_VIEW") ore.drop(table="NEW_ONTIME_S") ore.drop(view="NEW_ONTIME_S_VIEW") t <- ore.get("ONTIME_S","RQUSER") ore.attach() v <- ore.push(c(1,2,3,4,5)) ore.sync() ore.sync("RQUSER") ore.sync(table=c("ONTIME_S", "NARROW")) ore.sync("RQUSER", table=c("ONTIME_S", "NARROW")) ore.exists("ONTIME_S", "RQUSER") ore.exec("create table F2 as select * from ONTIME_S") Create a database table from a data.frame, ore.frame. Create a view from an ore.frame. Drop table or view in database Store R object in database as temporary object, returns handle to object. Data frame, matrix, and vector to table, list/model/others to serialized object Synchronize ORE proxy objects in R with tables/views available in database, on a per schema basis Returns TRUE if named table or view exists in schema
 ore.connect( RQUSER , SID , HOST , PASSWORD ,1521) ore.create( ONTIME_S, table = NEW_ONTIME_S ) ore.create( ONTIME_S, view = NEW_ONTIME_S_VIEW ) ore.drop(table= NEW_ONTIME_S ) ore.drop(view= NEW_ONTIME_S_VIEW ) t <- ore.get( ONTIME_S , RQUSER ) ore.attach() v <- ore.push(c(1,2,3,4,5)) ore.sync() ore.sync( RQUSER ) ore.sync(table=c( ONTIME_S , NARROW )) ore.sync( RQUSER , table=c( ONTIME_S , NARROW )) ore.exists( ONTIME_S , RQUSER ) ore.exec( create table F2 as select * from ONTIME_S ) Create a database table from a data.frame, ore.frame. Create a view from an ore.frame. Drop table or view in database. Store R object in database as temporary object, returns handle to object. Data frame, matrix, and vector to table, list/model/others to serialized object. Synchronize ORE proxy objects in R with tables/views available in database, on a per schema basis. Returns TRUE if named table or view exists in schema.")
27
Zugriff auf Datenbank-Tabellen
ore.connect(user = "RU",sid = "ORCL",host = "localhost",password = "RU",port = 1521) ore.sync() ore.ls() class(GESAMTSICHT)
 ore.sync() ore.ls() class(GESAMTSICHT)")
28
Orientierung über die Struktur der Tabellen
dim(GESAMTSICHT) names(GESAMTSICHT)
 names(GESAMTSICHT)")
29
Orientierung über die Struktur der Tabellen
str(GESAMTSICHT)
")
30
Ausschnitt der Daten anzeigen lassen
head(GESAMTSICHT)
")
31
Durchschnittliche Bewertung Berechnen
tapply(NUTZ_NR,PRODUKT_NR,mean)
")
32
Einfache visuelle Darstellung Welche Produkte zeigen auffälliges Verhalten?
plot(round(tapply(NUTZ_NR,PRODUKT_NR,mean),2),type="h",xlab = "Produktnummern", ylab ="Bewertungsindex") Produkte mit schlechten Bewertungen
,2),type= h ,xlab = Produktnummern , ylab = Bewertungsindex ) Produkte mit schlechten Bewertungen.")
33
Histogram hist(round(tapply(NUTZ_NR,PRODUKT_NR,mean),2),ylab = "Produktnummern", xlab ="Bewertungsindex") Die meisten Produkte haben gute Bewertungen im Bereich von 4 - 6

34
Neue Datenstrukturen erstellen Durchschnittliche Bewertungen pro Produkt
bew_prod <- aggregate(GESAMTSICHT$NUTZ_NR, by=GESAMTSICHT$PRODUKT_NR, FUN = mean) Spaltennamen ungeschickt PRODUKT_NR <- c(bew_prod$Group.1) BEWERTUNG <- c(bew_prod$x) df_bew_prod <- data.frame(PRODUKT_NR,BEWERTUNG) Neue Spaltennamen erstellt
 Spaltennamen ungeschickt. PRODUKT_NR <- c(bew_prod$Group.1) BEWERTUNG <- c(bew_prod$x) df_bew_prod <- data.frame(PRODUKT_NR,BEWERTUNG) Neue Spaltennamen erstellt.")
35
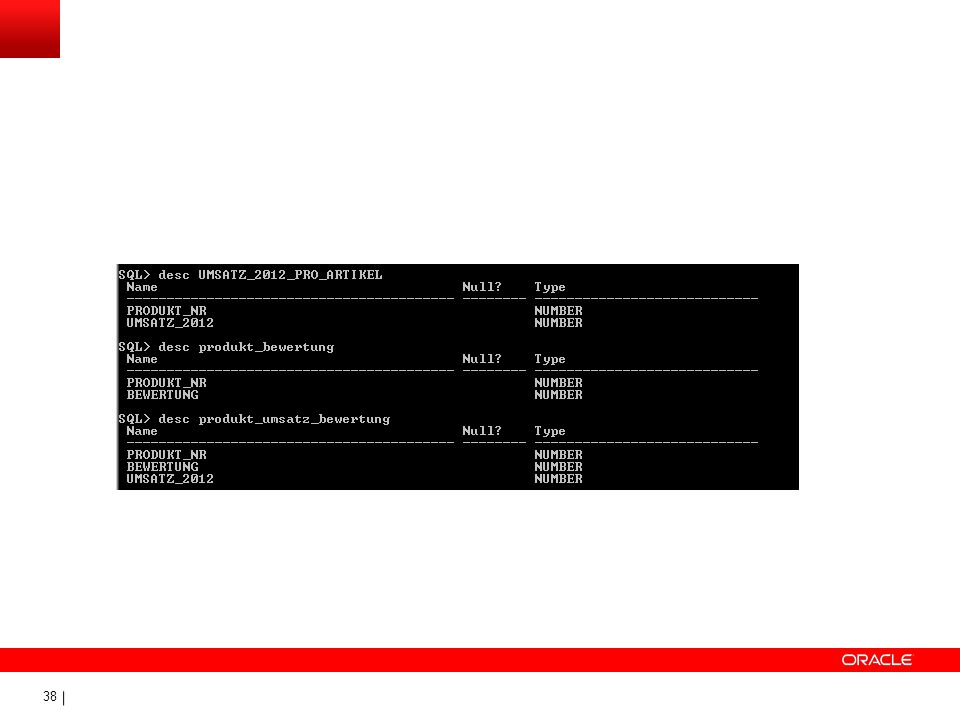
Neue Datenbanktabelle anlegen
ore.create(df_bew_prod,table = "PRODUKT_BEWERTUNG") Über die R-Engine erstellt CREATE table UMSATZ_2012_PRO_ARTIKEL as SELECT a.artikel_id PRODUKT_NR,sum(U.umsatz) UMSATZ_2012 FROM f_Umsatz_range U, D_zeit z, D_artikel a WHERE U.zeit_id = z.zeit_id AND U.artikel_id = a.artikel_id and z.jahr_nummer = 2012 GROUP by a.artikel_id ; In der Datenbank erstellt produkt_umsatz_bewertung <- merge(PRODUKT_BEWERTUNG,UMSATZ_2012_PRO_ARTIKEL, by="PRODUKT_NR",all=FALSE) Das Objekt produkt_umsatz_bewertung ist neu erstellt worden und könnte auch in die Datenbank gebracht werden.
 Über die R-Engine erstellt. CREATE table UMSATZ_2012_PRO_ARTIKEL as. SELECT a.artikel_id PRODUKT_NR,sum(U.umsatz) UMSATZ_2012. FROM f_Umsatz_range U, D_zeit z, D_artikel a. WHERE. U.zeit_id = z.zeit_id. AND U.artikel_id = a.artikel_id. and z.jahr_nummer = GROUP by a.artikel_id ; In der Datenbank erstellt. produkt_umsatz_bewertung <- merge(PRODUKT_BEWERTUNG,UMSATZ_2012_PRO_ARTIKEL, by= PRODUKT_NR ,all=FALSE) Das Objekt produkt_umsatz_bewertung ist neu erstellt worden und könnte auch in die Datenbank gebracht werden.")
36
Neue Strukturen aufbauen Gibt es eine Korrelation zwischen Bewertung und Umsatz?
Die neue Tabelle enthält die Spalten Umsatz und Bewertung. Gibt es dazwischen einen Zusammenhang. > names(produkt_umsatz_bewertung) [1] "PRODUKT_NR" "BEWERTUNG" "UMSATZ_2012„ > attach(produkt_umsatz_bewertung) > df_bewertung_umsatz <- data.frame(BEWERTUNG,UMSATZ_2012)
 [1] PRODUKT_NR BEWERTUNG UMSATZ_2012„ > attach(produkt_umsatz_bewertung) > df_bewertung_umsatz <- data.frame(BEWERTUNG,UMSATZ_2012)")
37
Neue Strukturen aufbauen Gibt es eine Korrelation zwischen Bewertung und Umsatz
Umsatz pro Produkt in create table Umsatz_2012_pro_Artikel as select distinct Produkt_nr, umsatz_2012 from gesamtsicht;

39
intersect(colnames(GESAMTSICHT), colnames(UMSATZ_2012_PRO_ARTIKEL))
, colnames(UMSATZ_2012_PRO_ARTIKEL))")
40
Invoke in-database aggregation function
aggdata <- aggregate(ONTIME_S$DEST, by = list(ONTIME_S$DEST), FUN = length) class(aggdata) head(aggdata) R user on desktop Source data is an ore.frame ONTIME_S, which resides in Oracle Database The aggregate() function has been overloaded to accept ORE frames aggregate() transparently switches between code that works with standard R data.frames and ore.frames Returns an ore.frame select DEST, count(*) from ONTIME_S group by DEST Client R Engine Other R packages Transparency Layer Oracle R package Oracle Database In-db stats User tables ©2012 Oracle – All Rights Reserved
, FUN = length) class(aggdata) head(aggdata) R user on desktop. Source data is an ore.frame ONTIME_S, which resides in Oracle Database. The aggregate() function has been overloaded to accept ORE frames. aggregate() transparently switches between code that works with standard R data.frames and ore.frames. Returns an ore.frame. select DEST, count(*) from ONTIME_S. group by DEST. Client R Engine. Other R packages. Transparency Layer. Oracle R package. Oracle Database. In-db stats. User tables. ©2012 Oracle – All Rights Reserved.")
41
ks.test ks.test – tests for the equality of continuous (numeric) vector probability distributions Compares… a sample with a reference probability distribution (one-sample KS test) Two samples (two-sample KS test) x <- ore.push(rnorm(500)) y <- ore.push(runif(300)) # Do x and y come from the same distribution? ks.test(x, x) ks.test(x, y) x <- ONTIME_S$ARRDELAY y <- ONTIME_S$DEPDELAY
 Two samples (two-sample KS test) x <- ore.push(rnorm(500)) y <- ore.push(runif(300)) # Do x and y come from the same distribution ks.test(x, x) ks.test(x, y) x <- ONTIME_S$ARRDELAY y <- ONTIME_S$DEPDELAY")
42
Gezielte Steuerung von Scripten innerhalb der Datenbank
Oracle Datenbank with(ERSTIS,split(alter,geschl)) Lokale R-Engine auf PC DB-Server-Maschine erstis Tabelle wird in den lokalen Speicher kopiert und lokal analysiert mod <- ore.doEval( function(param) { library(ORE) ore.connect(user="RQUSER", password="RQUSER", sid="ORCL", host=" ",port=1521) ore.sync() ore.attach() mod <- with(ERSTIS,split(alter,geschl)) }); Oracle Datenbank Lokale R-Engine auf PC erstis DB-Server-Maschine Tabelle bleibt in der DB. Analyse findet im Speicher des DB-Servers statt Das Ergebnis wird zurückgeliefert R-Engine auf DB-Server R-Engine auf DB-Server R-Engine auf DB-Server
) Lokale R-Engine. auf PC. DB-Server-Maschine. erstis. Tabelle wird in den. lokalen Speicher kopiert und lokal. analysiert. mod <- ore.doEval( function(param) { library(ORE) ore.connect(user= RQUSER , password= RQUSER , sid= ORCL , host= ,port=1521) ore.sync() ore.attach() mod <- with(ERSTIS,split(alter,geschl)) }); Oracle. Datenbank. Lokale R-Engine. auf PC. erstis. DB-Server-Maschine. Tabelle bleibt in der DB. Analyse findet im Speicher des. DB-Servers statt. Das Ergebnis wird zurückgeliefert. R-Engine auf DB-Server. R-Engine auf DB-Server. R-Engine auf DB-Server.")
43
OREeda Package Functions spezielle Funktionen (SAS analog)
ore.corr ore.crosstab ore.freq ore.lm ore.rank ore.sort ore.summary ore.univariate Oracle Datenbank DB Memory Lokale R-Engine auf PC erstis DB-Server-Maschine R Memory R-Engine auf DB-Server R-Engine auf DB-Server R-Engine auf DB-Server Die Abarbeitung im Memory der Datenbank ist schneller als im Memory der R Engine auf dem Server

44
Gezieltes Ansteuern einer Verarbeitungsvariante (Beispiel Regressions Modell)
mod <- ore.doEval( function(param) { library(ORE) ore.connect(user="RQUSER", password="RQUSER„, sid="ORCL", host=" ",port=1521) ore.sync() ore.attach() mod <- ore.lm(lz.1 ~ zuf.inh.1,ERSTIS) mod }); mod_local <- ore.pull(mod) class(mod_local) summary(mod_local) mod <- ore.doEval( function(param) { dat <- ore.pull(ONTIME_S) mod <- lm(ARRDELAY ~ DISTANCE DEPDELAY, dat) mod }); mod_local <- ore.pull(mod) class(mod_local) summary(mod_local) Daten bleiben im Memory Der Oracle Datenbank Daten im Memory der R-Engine auf dem DB-Server Laufzeit: 3 Sekunden Laufzeit: 110 Sekunden
 { library(ORE) ore.connect(user= RQUSER , password= RQUSER„, sid= ORCL , host= ,port=1521) ore.sync() ore.attach() mod <- ore.lm(lz.1 ~ zuf.inh.1,ERSTIS) mod. }); mod_local <- ore.pull(mod) class(mod_local) summary(mod_local) mod <- ore.doEval( function(param) { dat <- ore.pull(ONTIME_S) mod <- lm(ARRDELAY ~ DISTANCE + DEPDELAY, dat) mod. }); mod_local <- ore.pull(mod) class(mod_local) summary(mod_local) Daten bleiben im Memory. Der Oracle Datenbank. Daten im Memory. der R-Engine auf dem DB-Server. Laufzeit: 3 Sekunden. Laufzeit: 110 Sekunden.")
45
Funktionen und Prozeduren in der Datenbank

46
Aufrufen von R-Scripten über SQL-Statements komplett in der Datenbank
(sys.rqScriptCreate) Oracle Datenbank DB Memory select * from table(rqEval(NULL, 'select 1 id, 1 res from dual', 'Example1')); Select * from Table() DB-Server-Maschine R Memory R-Engine auf DB-Server R-Engine auf DB-Server R-Engine auf DB-Server begin sys.rqScriptCreate('Example1‘, 'function() { ID <- 1: res <- data.frame(ID = ID, RES = ID / 100) res}'); end; /
 Oracle. Datenbank. DB Memory. select * from table(rqEval(NULL, select 1 id, 1 res from dual , Example1 )); Select * from Table() DB-Server-Maschine. R Memory. R-Engine auf DB-Server. R-Engine auf DB-Server. R-Engine auf DB-Server. begin sys.rqScriptCreate( Example1‘, function() { ID <- 1:10 res <- data.frame(ID = ID, RES = ID / 100) res} ); end; /")
47
Visualisieren von Ergebnissen (Plotting)
")
52
Visualisieren von Ergebnissen (OBIEE)
")
53
Anzeige über Business Intelligence Als Funktion oder gespeicherte Ergebnisse
Das Kundenranking wird mit in den Berichten angezeigt Copyright 2011 Oracle Corporation

54
Einbindung von R-Grafiken in OBIEE Mit Parametern

55
Einbinden von R in umfangreichere Analyse-Szenarien

56
Cluster-Analyse Baum - Darstellung

57
Cluster-Analyse library(cluster)
")
58
Integrierte R Umgebung Oracle R Connector for Hadoop
ORE Client Host R Engine Hadoop Cluster Software MapReduce Nodes HDFS Oracle Big Data Appliance Oracle Exadata ORHC Native R MapReduce Native R HDFS Zugriff Mehr Produktivität

59
Big Data Connectors Oracle 11.2 HDFS Oracle R Connector
R-Package R-Package R Environment Oracle R Connector for Hadoop Oracle R Enterprise (Advanced Analytics) HDFS Cluster-Machines Oracle Server-Machine Oracle 11.2 hdfs_stream HDFS Oracle Direct Connector for HDFS External Table Preprocessor: hdfs_stream Target Table Hive Table CSV + / n CSV Data pump Offline Mode direct path convential path Parallel Execution Oracle Loader for Hadoop OCI Online Mode LoaderMap JDBC Partitioned + sorted MapReduce Job Framework
 HDFS Cluster-Machines. Oracle Server-Machine. Oracle hdfs_stream. HDFS. Oracle Direct Connector. for HDFS. External Table. Preprocessor: hdfs_stream. Target Table. Hive. Table. CSV + / n. CSV. Data pump. Offline. Mode. direct path. convential path. Parallel Execution. Oracle Loader for Hadoop. OCI. Online Mode. LoaderMap. JDBC. Partitioned. + sorted. MapReduce Job Framework.")
Ähnliche Präsentationen