Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Datenanalyse und Visualisierung in der Bioinformatik
Lehrveranstaltung Sommersemester 2006 W. Kurth, G. H. Buck-Sorlin, O. Kniemeyer Datenanalyse und Visualisierung in der Bioinformatik Praktikum, ca. 1 SWS Präsenzveranstaltung + ca. 4 SWS praktische Tätigkeit (betreutes Arbeiten)
")
2
Was ist Bioinformatik?

3
“Bioinformatik ist die Entwicklung und Anwendung von
Was ist Bioinformatik? “Bioinformatik ist die Entwicklung und Anwendung von Computeranwendungen für die Analyse, Interpretation, Simulation und Vorhersage von biologischen Systemen und korrespondierenden experimentellen Methoden in den Naturwissenschaften”. Steffen Schulze-Kremer (RZPD Dt. Ressourcenzentrum für Genomforschung GmbH) "Bioinformatik ist die computerunterstützte Analyse biologischer Systeme." Thomas Dandekar (EMBL Heidelberg) "Bioinformatik besteht darin, biologische Gesetzmäßigkeiten der Entwicklung neuer Algorithmen zugrunde zu legen und auf diese Weise zu synergistischen Effekten zu kommen, die weder in der Biologie noch in der Informatik alleine möglich wären." Thomas Werner (CEO Genomatix Software GmbH München) aus Hofestädt & Schnee (2002)
 Bioinformatik ist die computerunterstützte Analyse biologischer Systeme. Thomas Dandekar (EMBL Heidelberg) Bioinformatik besteht darin, biologische Gesetzmäßigkeiten der Entwicklung neuer Algorithmen zugrunde zu legen und auf diese Weise zu synergistischen Effekten zu kommen, die weder in der Biologie noch in der Informatik alleine möglich wären. Thomas Werner (CEO Genomatix Software GmbH München) aus Hofestädt & Schnee (2002)")
4
Was ist Bioinformatik? 1. Bio-Informatik = Probleme aus der Biologie + Methoden aus der Informatik; 2. Bio-Informatik = Probleme aus der Informatik + Methoden aus der Biologie. Rolf Backofen (Institut für Informatik, LMU München) aus Hofestädt & Schnee (2002) a. Schwerpunkt auf biologischer Fragestellung, Informatikwerkzeuge nach Bedarf eingesetzt b. Schwerpunkt auf Informatikmethoden, Biologie nur entfernte Motivation für untersuchte Probleme c. wirklich interdisziplinärer Ansatz: untersuchte Fragestellung und verwendete Informatikmethoden werden in ständigem Prozess adaptiert. Notwendig, da die Problemformalisierung nur eine Abstraktion des ursprünglichen Problems sein kann. Feinunterscheidung (nach Michael Waterman):
 aus Hofestädt & Schnee (2002) a. Schwerpunkt auf biologischer Fragestellung, Informatikwerkzeuge nach Bedarf eingesetzt. b. Schwerpunkt auf Informatikmethoden, Biologie nur entfernte Motivation für untersuchte Probleme. c. wirklich interdisziplinärer Ansatz: untersuchte Fragestellung und verwendete Informatikmethoden werden in ständigem Prozess adaptiert. Notwendig, da die Problemformalisierung nur eine Abstraktion des ursprünglichen Problems sein kann. Feinunterscheidung (nach Michael Waterman):")
5
aus Hofestädt & Schnee (2002)
")
8
Quelle: DKFZ Abteilung Bioinformatik und Funktionelle Genomik

9
Drei Integrationsachsen in der Computerbiologie
Gen Protein Makromolekularer Komplex Organelle Zelle Netzwerk Gewebe Organ System Organismus Drei Integrationsachsen in der Computerbiologie Empirische Daten Ontologien Statistische Modellierung System- analyse Vorhersagende Physiko-chemische erste Prinzipien Mathematische Theorie funktional regulatorisch Wachs- tum Metabolik elektrisch mechanisch Transport strukturell zwischen Daten und Theorie nach McCULLOCH & HUBER (2002), verändert
, verändert.")
10
Herausforderungen: funktional Systembiologie
nach McCULLOCH & HUBER (2002), verändert
, verändert.")
11
Herausforderungen: Zentrales Ziel der Systembiologie:
Funktional integrierte biologische Modellierung datenbezogen datenintensiv funktional nach McCULLOCH & HUBER (2002), verändert
, verändert.")
12
Herausforderungen: funktional Systembiologie Computational Biology
strukturell nach McCULLOCH & HUBER (2002), verändert
, verändert.")
13
Herausforderungen: funktional Systembiologie Computational Biology:
strukturell integriert (z.B. Molekulare Dynamik, Vorhersage der Proteinstruktur) gesteuert durch physiko- chemische 1. Prinzipien berechnungsintensiv - Ziel: Skalenintegration strukturell nach McCULLOCH & HUBER (2002), verändert
 gesteuert durch physiko- chemische 1. Prinzipien. berechnungsintensiv. - Ziel: Skalenintegration. strukturell. nach McCULLOCH & HUBER (2002), verändert.")
14
Physiko-chemische Erste Prinzipien:
z.B. Massenerhaltung, Minimierung mechanischer Spannungen Problem der Proteinfaltung Massengleichgewicht bei Analysen metabolischer Flüsse (auch bei sink-source-Modellen) nach McCULLOCH & HUBER (2002), verändert
 nach McCULLOCH & HUBER (2002), verändert.")
15
Beispiele für Schnittstellen zwischen strukturell und funktionell
integrierter Computational Biology: Kopplung zwischen biochemischen Netzwerken und räumlich gekoppelten Netzwerken Nutzung physiko-chemischer Beschränkungen zur Optimierung genomischer Systemmodelle des Zellmetabolismus Entwicklung kinetischer Modelle der Zellsignalübertragung in Verbindung mit physiologischen Targets wie z.B. Energiestoff- wechsel, Ionenflüsse oder Zellmotilität Nutzung empirischer Beschränkungen zur Optimierung von Vorhersagen der Proteinfaltung Integration von Systemmodellen der Zelldynamik in Kontinuum- modelle der Gewebe- und Organphysiologie nach McCULLOCH & HUBER (2002), verändert
, verändert.")
16
Hintergrund:

17
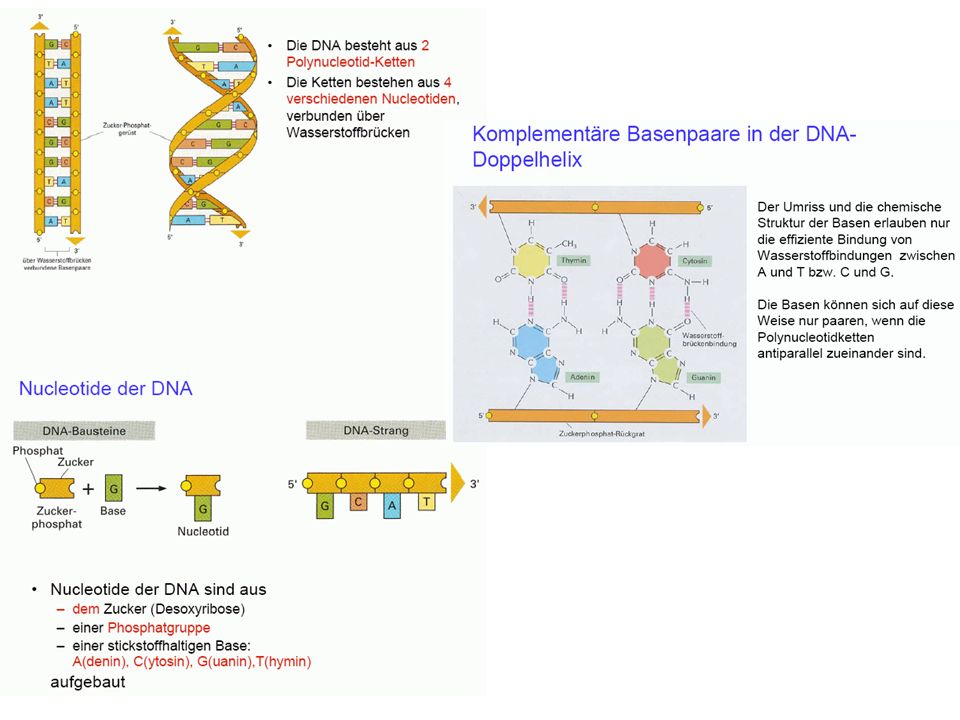
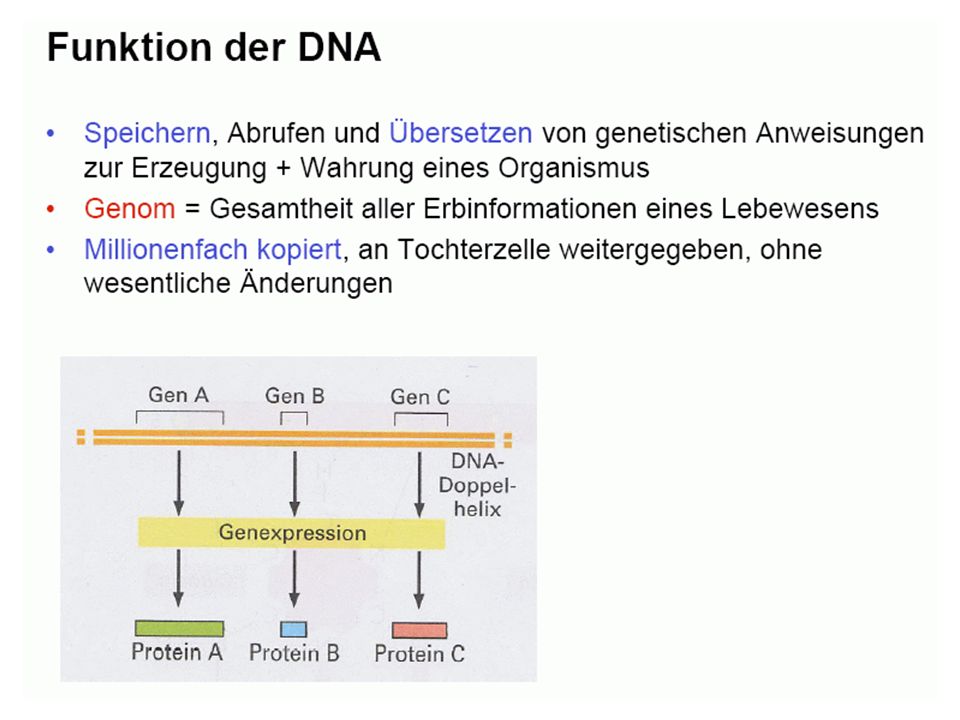
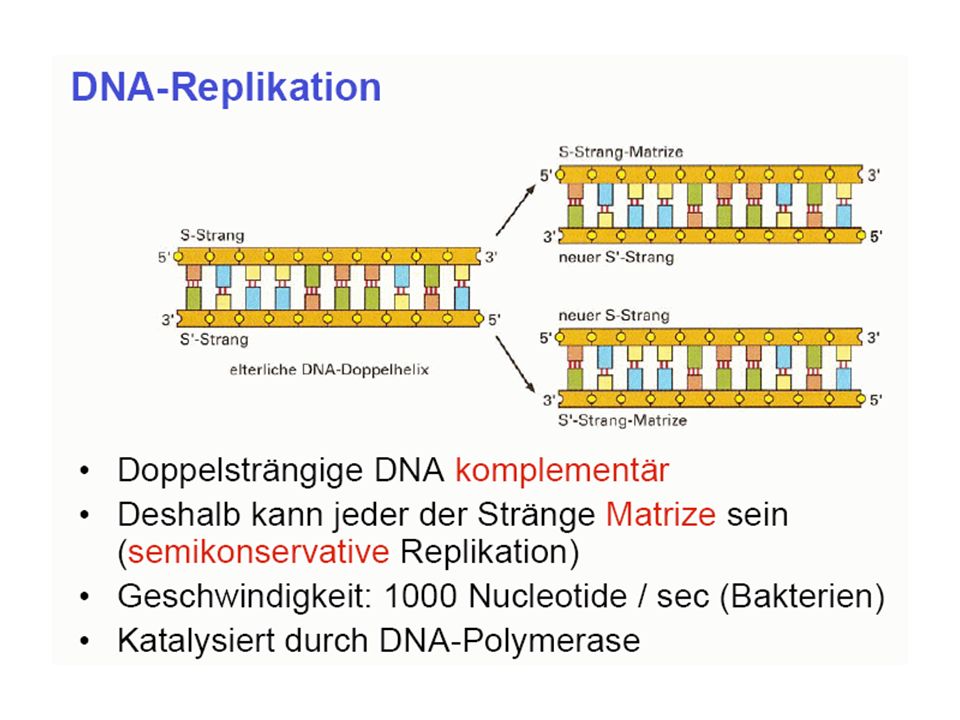
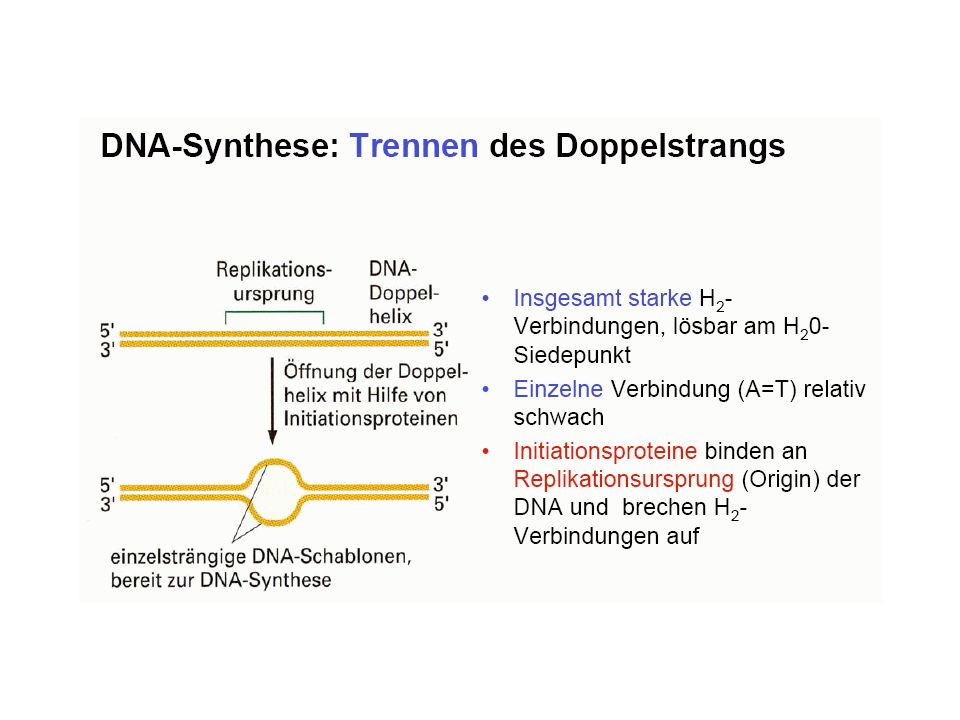
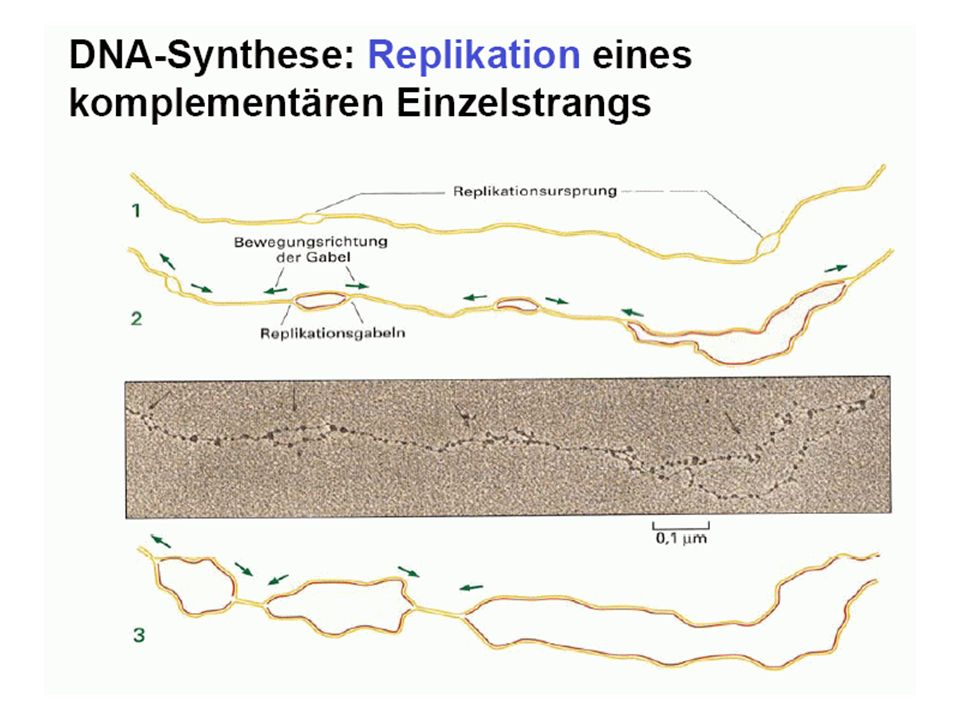
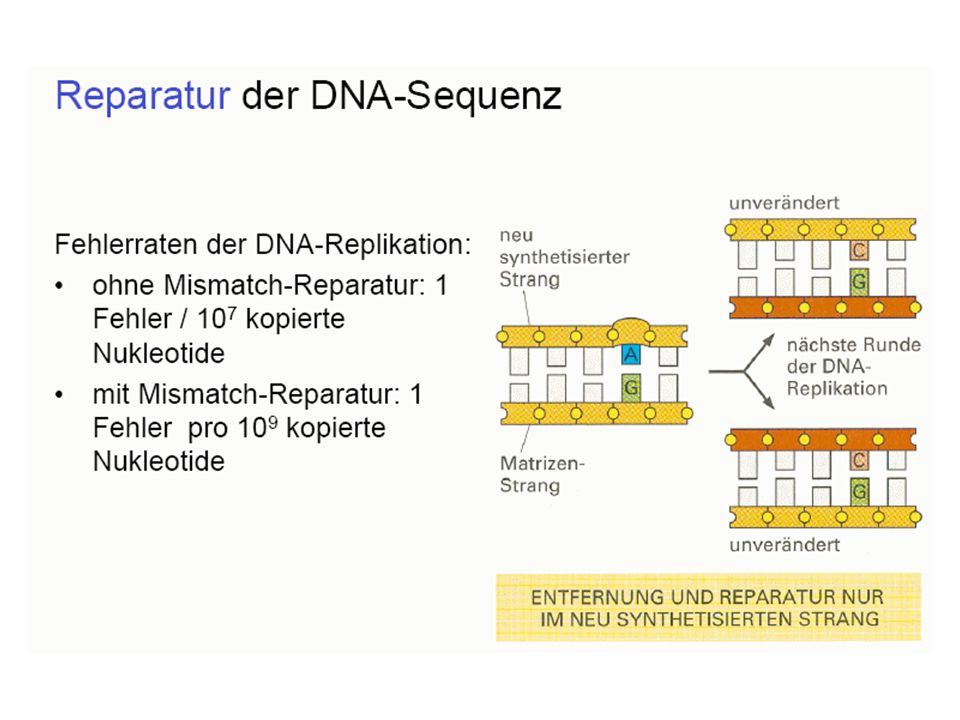
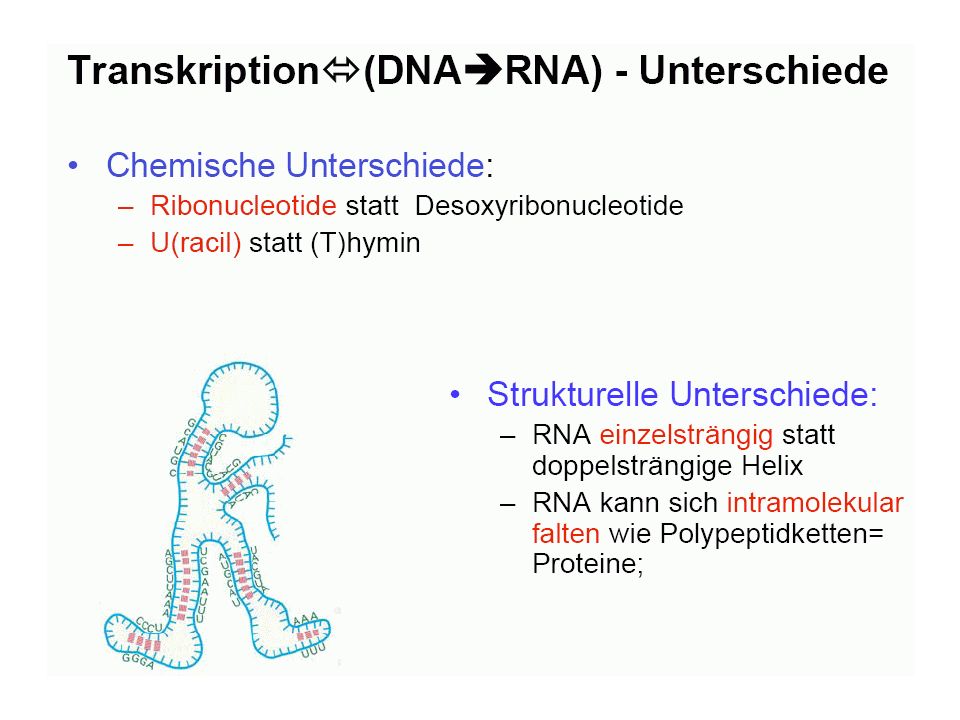
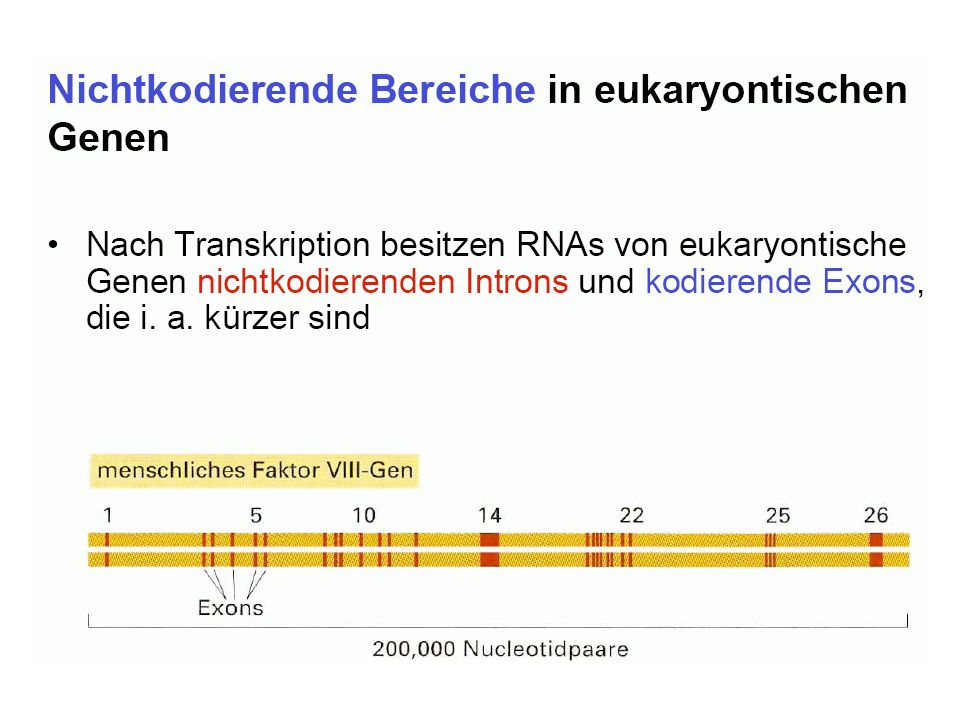
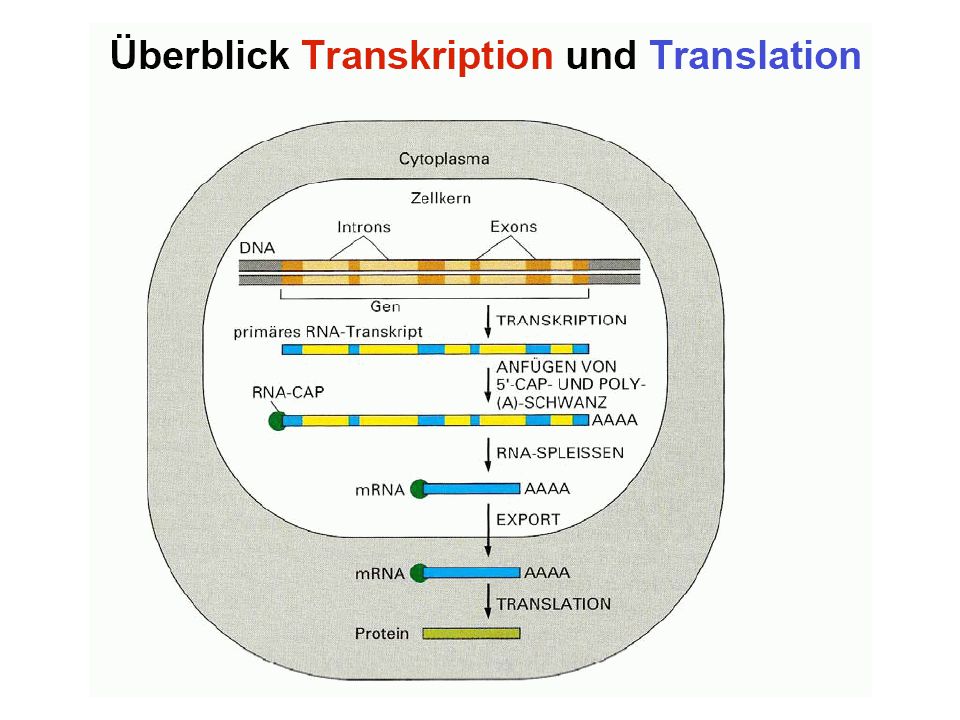
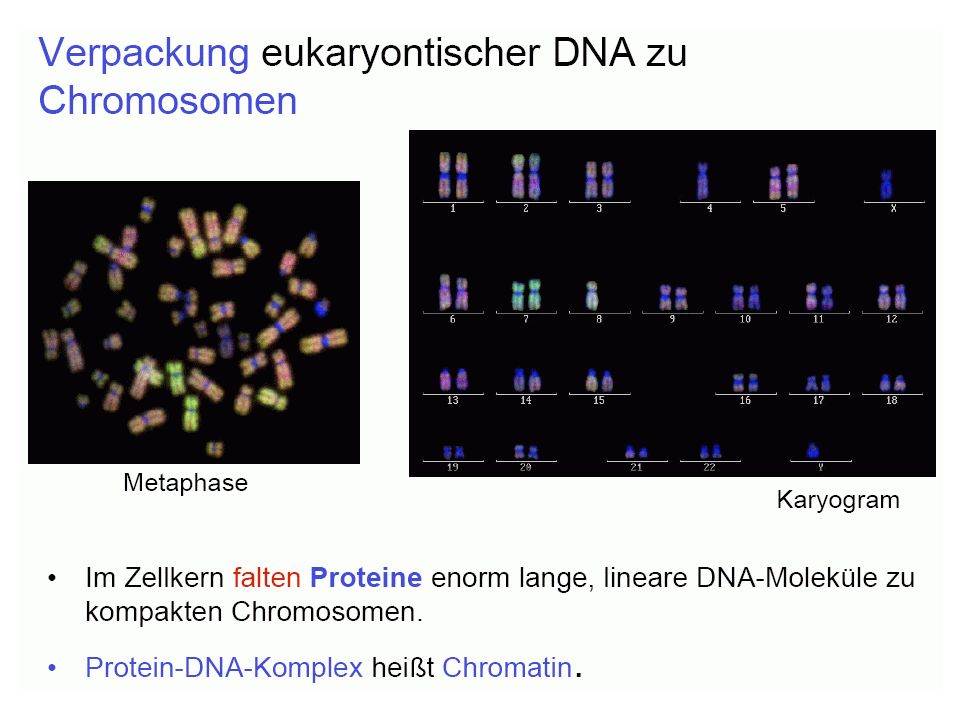
Grundvorstellung: Bauplan und Funktionsmöglichkeiten des Organismus gespeichert in DNA-Molekülen, diese werden repliziert DNA als Träger der genetischen Information (Erbinformation; Genom) (DNA = desoxyribonucleic acid = Desoxyribonukleinsäure = DNS)
 (DNA = desoxyribonucleic acid = Desoxyribonukleinsäure = DNS)")
25
Zum Begriff des Gens: Unterscheidung zwischen Funktionsgen und Mendel-Gen

27
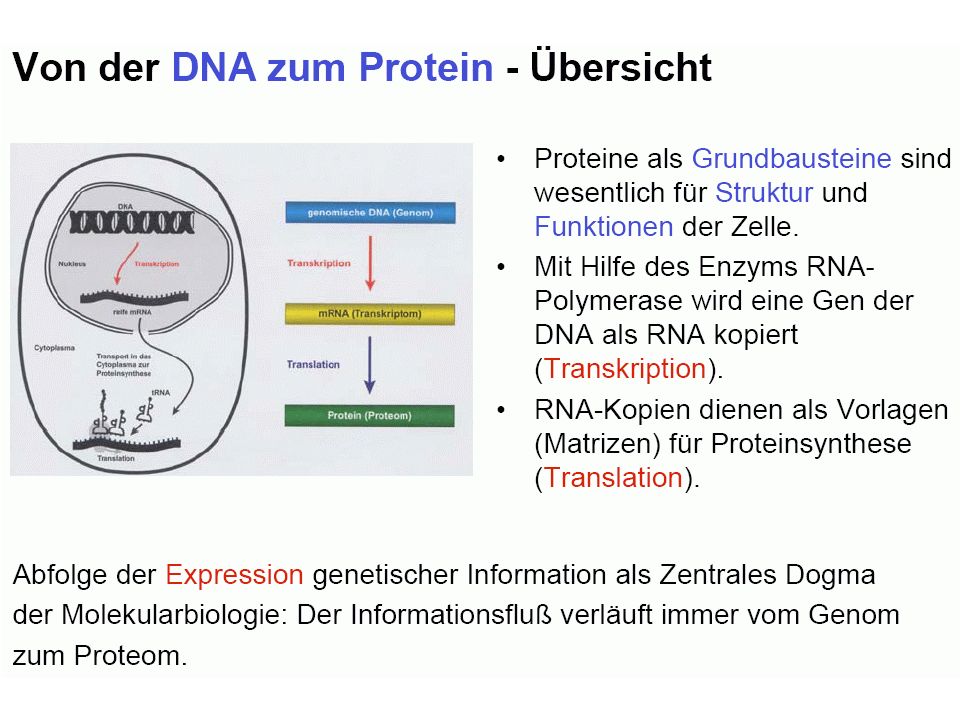
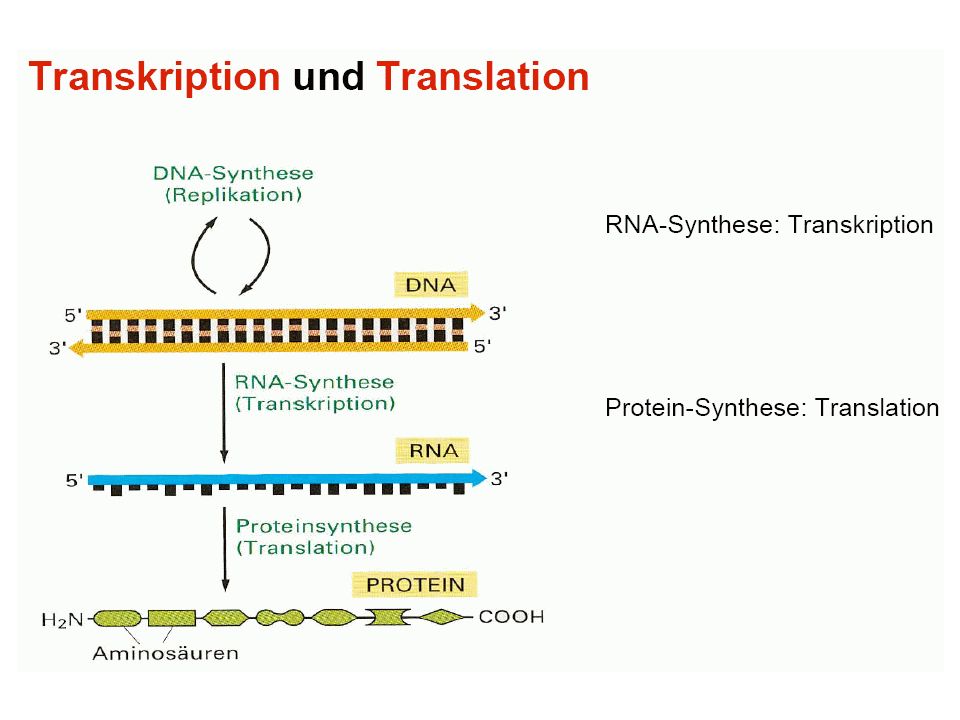
Das Zentrale Dogma „The central dogma states that once 'information' has passed into a protein it cannot get out again. The transfer of information from nucleic acid to nucleic acid, or from nucleic acid to protein, may be possible, but transfer from protein to protein, or from protein to nucleic acid, is impossible. Information here means the precise determination of sequence, either of bases in the nucleic acid or of amino acid residues in the protein" Francis Crick (1958). aus Waterman (1995)
. aus Waterman (1995)")
44
Bioinformatik-Probleme
Probleme, die mit dem zentralen Dogma assoziiert sind: Alle Probleme, die direkt mit einem spezifischen Level von Information (Sequenz, Struktur, Funktion) assoziiert sind oder aber mehrere Levels umfassen. Beispiele: Alignierungsverfahren (sequence alignment, structural alignment); Proteinstrukturvorhersage Probleme der Datenhaltung: Fragestellungen der Speicherung, Wiedergewinnung und Analyse der Daten. Beispiele: Aufbau von biologischen Datenbanken; data mining (Gewinnung neuen Wissens aus der Ansammlung der Daten) Simulation biologischer Systeme: Vorhersage des dynamischen Verhaltens eines biologischen Systems auf der Basis seiner Komponenten. Beispiel: Untersuchung metabolischer Netzwerke. Rolf Backofen (Institut für Informatik, LMU München) aus Hofestädt & Schnee (2002)
 assoziiert sind oder aber mehrere Levels umfassen. Beispiele: Alignierungsverfahren (sequence alignment, structural alignment); Proteinstrukturvorhersage. Probleme der Datenhaltung: Fragestellungen der Speicherung, Wiedergewinnung und Analyse der Daten. Beispiele: Aufbau von biologischen Datenbanken; data mining (Gewinnung neuen Wissens aus der Ansammlung der Daten) Simulation biologischer Systeme: Vorhersage des dynamischen Verhaltens eines biologischen Systems auf der Basis seiner Komponenten. Beispiel: Untersuchung metabolischer Netzwerke. Rolf Backofen (Institut für Informatik, LMU München) aus Hofestädt & Schnee (2002)")
49
Die nächsthöhere Ebene: "Metabolomik"
Metabolische Netzwerke Leben: beruht auf sehr vielen Stoffwechselprozessen, vernetzt (menschl. Zelle: ca Molekülarten) "autokatalytisch": das Netzwerk produziert seine eigenen Katalysatoren Datenbanken (Selkov et al.; Karp et al. ...) zu den Netzwerken
 autokatalytisch : das Netzwerk produziert seine eigenen Katalysatoren. Datenbanken (Selkov et al.; Karp et al. ...) zu den Netzwerken.")
50
Ausschnitt aus den "metabolic pathways":

51
Formalisierung: bipartite Graphen Stoffknoten und Reaktionsknoten (qualitatives Modell – liefert Rahmen und Restriktionen für quantitative Modelle) Erweiterung: Petri-Netze ggf. Petri-Netze mit Farben (Marken) = "high-level Petri nets" Arbeiten von Reddy et al. 1993, M. Heiner ...
 Erweiterung: Petri-Netze. ggf. Petri-Netze mit Farben (Marken) = high-level Petri nets Arbeiten von Reddy et al. 1993, M. Heiner ...")
52
Beispiel: Petrinetz-Modell des Glykolyse/Pentosephosphat-Stoffwechsels (aus Heiner et al. 2001):
Probleme: - Bestimmung solcher Netzwerke aus empirischen Daten - topologische Analyse - insbes. Pfadlängen - dynamische Simulation der Konzentrationen

53
Die "makroskopische Ebene":
Morphologie, Wachstum und Funktion von (bzw. in) Organen, Organismen und Biota (Lebensgemeinschaften) bisher in der Bioinformatik noch wenig im Fokus aber: zukünftige Notwendigkeit, zu dieser Skalenebene vorzustoßen Beispiel: Struktur und Funktion von Pflanzen Struktur: Stamm, Wurzel, Äste, Blätter, Blüten... Funktionen: Photosynthese, Atmung, Stofftransport, Speicherung von Assimilaten, Reproduktion der Pflanze... Zusammenhang von Struktur und Funktion: z.B. Optimierung der Lichtaufnahme über die Anordnung der Blätter
 Organen, Organismen und Biota (Lebensgemeinschaften) bisher in der Bioinformatik noch wenig im Fokus. aber: zukünftige Notwendigkeit, zu dieser Skalenebene vorzustoßen. Beispiel: Struktur und Funktion von Pflanzen. Struktur: Stamm, Wurzel, Äste, Blätter, Blüten... Funktionen: Photosynthese, Atmung, Stofftransport, Speicherung von Assimilaten, Reproduktion der Pflanze... Zusammenhang von Struktur und Funktion: z.B. Optimierung der Lichtaufnahme über die Anordnung der Blätter.")
54
Formalismus der L-Systeme (Lindenmayer-Systeme):
aus der Theorie formaler Grammatiken analog zu Chomsky-Grammatiken (regulär, kontextfrei, kontextsensitiv etc.) aber: in jedem Ableitungsschritt parallele Ersetzung aller Zeichen, auf die eine Regel anwendbar ist von Aristid Lindenmayer (Botaniker) 1968 zur Modellierung des Wachstums von fadenförmigen Algen eingeführt
 aber: in jedem Ableitungsschritt parallele Ersetzung aller Zeichen, auf die eine Regel anwendbar ist. von Aristid Lindenmayer (Botaniker) 1968 zur Modellierung des Wachstums von fadenförmigen Algen eingeführt.")
55
L-Systeme arbeiten stringbasiert.
Erweiterungen: Wörter aus parametrisierten Zeichen (Modulen); Graph-Grammatiken; map-L-Systeme und cellwork-L-Systeme. Grundversion gut für alle Strukturen mit lokal 1-dimensionalem Grundgerüst (Verzweigungssysteme). Definition: Ein (kontextfreies, nichtparametrisches) L-System ist ein Tripel (, , R), darin ist - eine nichtleere Menge von Zeichen (das Alphabet), - ein Element von *, das Startwort oder Axiom, - R eine nichtleere Teilmenge von *, die Menge der Produktionsregeln (generative Regeln).
; Graph-Grammatiken; map-L-Systeme und cellwork-L-Systeme. Grundversion gut für alle Strukturen mit lokal 1-dimensionalem Grundgerüst (Verzweigungssysteme). Definition: Ein (kontextfreies, nichtparametrisches) L-System ist ein Tripel. (, , R), darin ist. - eine nichtleere Menge von Zeichen (das Alphabet), - ein Element von *, das Startwort oder Axiom, - R eine nichtleere Teilmenge von *, die Menge der Produktionsregeln (generative Regeln).")
56
Ein Ableitungsschritt eines Wortes
Ein Ableitungsschritt eines Wortes * besteht aus der Ersetzung aller Zeichen in , die in linken Regelseiten von R vorkommen, durch die entsprechenden rechten Regelseiten. Man vereinbart: Zeichen, auf die keine Regeln anwenbar sind, werden unverändert übernommen. Ergebnis zunächst nur: Ableitungskette von Wörtern, die sich durch iterierte Anwendung des rewriting-Vorgangs aus dem Startwort ergeben. 1 2 3 .... was für die Morphologie-Modellierung noch fehlt: - eine Semantik (= geometrische Interpretation)
")
57
füge zu obiger Def. hinzu:
eine Abbildung, die jedem Wort aus * eine Teilmenge des R3 zuordnet dann: "interpretierte" L-System-Abarbeitung 1 2 3 .... S1 S2 S S1, S2, S3, ... können als Generationen oder als Entwicklungsstufen eines belebten Objekts (Pflanze, Biotop...) interpretiert werden. Als Interpretationsabbildung wird meistens gewählt: Turtle geometry ("Schildkrötengeometrie") befehlsgesteuertes, lokales Navigieren im 2D- oder 3D-Raum - Abelson & diSessa 1982 - vgl. Sprache "LOGO"
 interpretiert werden. Als Interpretationsabbildung wird meistens gewählt: Turtle geometry ( Schildkrötengeometrie ) befehlsgesteuertes, lokales Navigieren im 2D- oder 3D-Raum. - Abelson & diSessa vgl. Sprache LOGO")
58
"Turtle": Zeichen- oder Konstruktionsgerät (virtuell)
- speichert (grafische und nicht-grafische) Informationen - mit Stack assoziiert aktueller Zustand enthält z.B. Information über aktuelle Liniendicke, Schrittweite, Farbe, weitere Eigenschaften des als nächstes zu konstruierenden Objekts Befehle (Auswahl): F "Forward", mit Konstruktion eines Elements (Linienstück, Segment, Internodium einer Pflanze...), benutzt wird die aktuelle Schrittweite für die Länge f forward ohne Konstruktion (move-Befehl) L(x) ändere die aktuelle Schrittweite (Länge) zu x L+(x) inkrementiere die aktuelle Schrittweite um x L*(x) multipliziere die aktuelle Schrittweite mit x D(x), D+(x), D*(x) analog für die aktuelle Dicke RU(45) Drehung der turtle um die "up"-Achse um 45° RL(...), RH(...) analog um "left" und "head"-Achse up-, left- und head-Achse bilden ein orthonormales Rechtssystem, das von der turtle mitgeführt wird
 Informationen. - mit Stack assoziiert. aktueller Zustand enthält z.B. Information über aktuelle Liniendicke, Schrittweite, Farbe, weitere Eigenschaften des als nächstes zu konstruierenden Objekts. Befehle (Auswahl): F Forward , mit Konstruktion eines Elements (Linienstück, Segment, Internodium einer Pflanze...), benutzt wird die aktuelle Schrittweite für die Länge. f forward ohne Konstruktion (move-Befehl) L(x) ändere die aktuelle Schrittweite (Länge) zu x. L+(x) inkrementiere die aktuelle Schrittweite um x. L*(x) multipliziere die aktuelle Schrittweite mit x. D(x), D+(x), D*(x) analog für die aktuelle Dicke. RU(45) Drehung der turtle um die up -Achse um 45° RL(...), RH(...) analog um left und head -Achse. up-, left- und head-Achse bilden ein orthonormales Rechtssystem, das von der turtle mitgeführt wird.")
59
Strings aus diesen Symbolen werden sequenziell abgearbeitet.
Verzweigungen: Realisierung mit Stack-Befehlen [ lege aktuellen Zustand auf Stack ] nimm Zustand vom Stack und mache diesen zum aktuellen Zustand (Ende der Verzweigung)
")
60
Beispiel: Regeln a F [ RU45 b ] a, b F b Startwort a
![Beispiel: Regeln a F [ RU45 b ] a, b F b Startwort a](http://slideplayer.org/slide/669771/1/images/60/Beispiel%3A+Regeln+a+%EF%82%AE+F+%5B+RU45+b+%5D+a%2C+b+%EF%82%AE+F+b+Startwort+a.jpg "Beispiel: Regeln a F [ RU45 b ] a, b F b Startwort a")
61
Verzweigung, alternierende Zweigstellung und Verkürzung:
* F a, a L*0.5 [ RU90 F ] F RH180 a

62
Beispiel Fichte (L-System basierend auf Messungen an realen Bäumen)
")
63
Nachteile von L-Systemen:
• in L-Systemen mit Verzweigungen (über Turtle-Kommandos) nur 2 mögliche Relationen zwischen Objekten: "direkter Nachfolger" und "Verzweigung" Erweiterungen: • Zulassen weiterer Relationstypen (beliebig wählbar) • Zulassen von Zyklen ( Graph-Grammatik)
 nur 2 mögliche Relationen zwischen Objekten: direkter Nachfolger und Verzweigung Erweiterungen: • Zulassen weiterer Relationstypen (beliebig wählbar) • Zulassen von Zyklen ( Graph-Grammatik)")
64
"relationale Wachstumsgrammatik"
• Grammatik modifiziert direkt den Graphen, Umweg über String-Codierung entfällt (bzw. wird nur noch für Regel-Input gebraucht) "relationale Wachstumsgrammatik" außerdem Nachteil der Turtle-Interpretation von L-Systemen: Segmente sind nur Zylinder, keine Objekte im Sinne der OOP Erweiterungen: • Knoten des Graphen können beliebige Objekte sein (auch Grafikobjekte) • Einbettung von Code einer höheren, imperativen oder objektorientierten Programmiersprache in die Regeln (für uns: Java)
 relationale Wachstumsgrammatik außerdem Nachteil der Turtle-Interpretation von L-Systemen: Segmente sind nur Zylinder, keine Objekte im Sinne der OOP. Erweiterungen: • Knoten des Graphen können beliebige Objekte sein (auch Grafikobjekte) • Einbettung von Code einer höheren, imperativen oder objektorientierten. Programmiersprache in die Regeln (für uns: Java)")
65
Relationale Wachstumsgrammatiken (RGG)
Aufbau einer Regel einer RGG:

66
eine RGG-Regel und ihre Anwendung in grafischer Form:
Regel in Textform: i -b-> j -a-> k -a-> i = => j

67
Realisierung dieser Konstrukte in einer Programmiersprache:
Sprache XL (eXtended L-system language) • RGG-Regeln in Blöcken organisiert Kontrolle der Reihenfolge der Regelanwendungen • Turtle-Kommandos als Knoten erlaubt • Knoten sind Java-Objekte • Sprache Java als Rahmen für die gesamte RGG Benutzer kann Konstanten, Variablen, Klassen... definieren
 • RGG-Regeln in Blöcken organisiert. Kontrolle der Reihenfolge der Regelanwendungen. • Turtle-Kommandos als Knoten erlaubt. • Knoten sind Java-Objekte. • Sprache Java als Rahmen für die gesamte RGG. Benutzer kann Konstanten, Variablen, Klassen... definieren.")
68
XL wird interpretiert von der interaktiven 3D-Plattform GroIMP (Growth-grammar related Interactive Modelling Platform) • GroIMP stellt Objekte für die 3D-Visualisierung bereit. Diese können in XL verwendet werden (analog zur Turtle-Grafik in klassischen L-Systemen). • GroIMP ist ein open source-Projekt; siehe
. • GroIMP ist ein open source-Projekt; siehe.")
69
Signalausbreitung in einem Netzwerk
Beispiel für RGG-Anwendung: Signalausbreitung in einem Netzwerk Zellen mit zwei Zuständen (0 oder 1) – codiert als Attribut (Knoten-Markierung) "state" nur eine RGG-Regel: (* c1: Cell *) c2: Cell, (c1.state == 1) ==> c2(1) grafische Darstellung der Regel: (schattiert: Kontext)
 – codiert als Attribut. (Knoten-Markierung) state nur eine RGG-Regel: (* c1: Cell *) c2: Cell, (c1.state == 1) ==> c2(1) grafische Darstellung der Regel: (schattiert: Kontext)")
70
2 3 1 Anwendung auf ein gegebenes Netzwerk: Verfeinerung:
Verwendung reellwertiger Zustände (für Konzentrationen...) und von Regeln, die typische Reaktionskinetiken darstellen Simulation von Reaktions- und Transportnetzwerken
 und von Regeln, die typische Reaktionskinetiken darstellen. Simulation von Reaktions- und Transportnetzwerken.")
71
Allgemeine Literatur:

72
Allgemeine Literatur:
Hofestädt, R., Schnee, R. (2002): Studien- und Forschungsführer Bioinformatik. Spektrum-Verlag. 234 S. Rashidi, H., Bühler, L.K. (2001): Grundriss der Bioinformatik. Spektrum-Verlag. 215 S. Hansen, A. (2001): Bioinformatik. Ein Leitfaden für Naturwissenschaftler. Birkhäuser-Verlag. 112 S. Waterman, M.S. (1995): Introduction to Computational Biology. Maps, sequences and genomes. Chapman & Hall, London. 431 S. Mount, D.W. (2001): Bioinformatics. Sequence and Genome Analysis. Cold Spring Harbor Laboratory Press. 564 S. Prusinkiewicz, P.; Lindenmayer, A. (1990): The Algorithmic Beauty of Plants. Springer, Berlin.
: Studien- und Forschungsführer Bioinformatik. Spektrum-Verlag. 234 S. Rashidi, H., Bühler, L.K. (2001): Grundriss der Bioinformatik. Spektrum-Verlag. 215 S. Hansen, A. (2001): Bioinformatik. Ein Leitfaden für Naturwissenschaftler. Birkhäuser-Verlag. 112 S. Waterman, M.S. (1995): Introduction to Computational Biology. Maps, sequences and genomes. Chapman & Hall, London. 431 S. Mount, D.W. (2001): Bioinformatics. Sequence and Genome Analysis. Cold Spring Harbor Laboratory Press. 564 S. Prusinkiewicz, P.; Lindenmayer, A. (1990): The Algorithmic Beauty of Plants. Springer, Berlin.")
73
Themenliste: T1: Modellierung der Morphologie von Arabidopsis thaliana mit relationalen Wachstumsgrammatiken unter GroIMP T2: Zellbiologisches Modell von Blumeria graminis (Mehltau) T3: Topologische Analyse von biochemischen Reaktions-netzwerken T4: Dreidimensionale "Biomorphe" mit Insektenformen, unter Verwendung von XL und von NURBS-Flächen in GroIMP T5: Konstruktion und Visualisierung taxonomischer Bäume auf Basis von Sequenzdaten T6: Ontologische Visualisierung von Genexpressionsdaten aus Makroarray-Experimenten
 T3: Topologische Analyse von biochemischen Reaktions-netzwerken. T4: Dreidimensionale Biomorphe mit Insektenformen, unter Verwendung von XL und von NURBS-Flächen in GroIMP. T5: Konstruktion und Visualisierung taxonomischer Bäume auf Basis von Sequenzdaten. T6: Ontologische Visualisierung von Genexpressionsdaten aus Makroarray-Experimenten.")
74
Zeitplan: Einführung Detaillierte Vorstellung der Themen, verbindliche Anmeldung Einführung in die Sprache XL und Vorstellung der Software GroIMP Zwischenpräsentation der Ergebnisse Abschlusspräsentation der Ergebnisse

Ähnliche Präsentationen


















>")
 Prof. Th. Ottmann.>")













