Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Vorlesung Datenbanksysteme vom 20.10.2014 Physische Datenorganisation
Architektur eines DBMS Speicherhierarchie Hintergrundspeicher / RAID Index-Verfahren Ballung (Clustering) „beste“ Zugriffsmethode Ev. nach dem RAID-Kapitel eine Folie „Nicht nur für HW-Gurus“ einfügen (oder zumindest auf der Ton-Spur erwähnen) mit wichtigen Punkten: Architektur-Übersicht Zugriffslücke: DB-Puffer vs. Platte Seitenweise Verarbeitung der Daten TIDs ad ISAM: Da Kemper und Ramakrishnan sich widersprechen, lassen wir dieses Kapitel lieber aus. Unklar: Wie wird B-Index bzw. B+-Index bei mehrfachen Schlüsseln organisiert. Antwort: wird in Ulmann‘s „complete book“ gut beschrieben -> könnte man auch in den Stoff aufnehmen.
 „beste Zugriffsmethode. Ev. nach dem RAID-Kapitel eine Folie „Nicht nur für HW-Gurus einfügen (oder zumindest auf der Ton-Spur erwähnen) mit wichtigen Punkten: Architektur-Übersicht. Zugriffslücke: DB-Puffer vs. Platte. Seitenweise Verarbeitung der Daten. TIDs. ad ISAM: Da Kemper und Ramakrishnan sich widersprechen, lassen wir dieses Kapitel lieber aus. Unklar: Wie wird B-Index bzw. B+-Index bei mehrfachen Schlüsseln organisiert. Antwort: wird in Ulmann‘s „complete book gut beschrieben -> könnte man auch in den Stoff aufnehmen.")
2
Architektur eines DBMS
Wichtigste SW-Komponenten eines DBMS SW-Komponenten der physischen Speicherorganisation

3
Architektur eines DBMS

4
Disk Space Manager: Verwaltet die Daten auf der Platte
Die höheren Schichten des DBMS sehen keine HW-Details sondern nur noch eine Sammlung von Seiten Disk Space Manager stellt Routinen bereit für Allokieren / Deallokieren von Seiten Lesen / Schreiben einer Seite Bemerkung: 1 Seite entspricht einem Block auf der Platte => Lesen/Schreiben einer Seite in einem I/O-Vorgang Die meisten DB-Systeme haben eigenes Disk Management (und erweitern nicht bloß die File System Funktionen des OS) => flexibler, größere OS-Unabhängigkeit Ad Flexibilität: File kann sich nicht über mehrere Platten erstrecken,
 => flexibler, größere OS-Unabhängigkeit. Ad Flexibilität: File kann sich nicht über mehrere Platten erstrecken,")
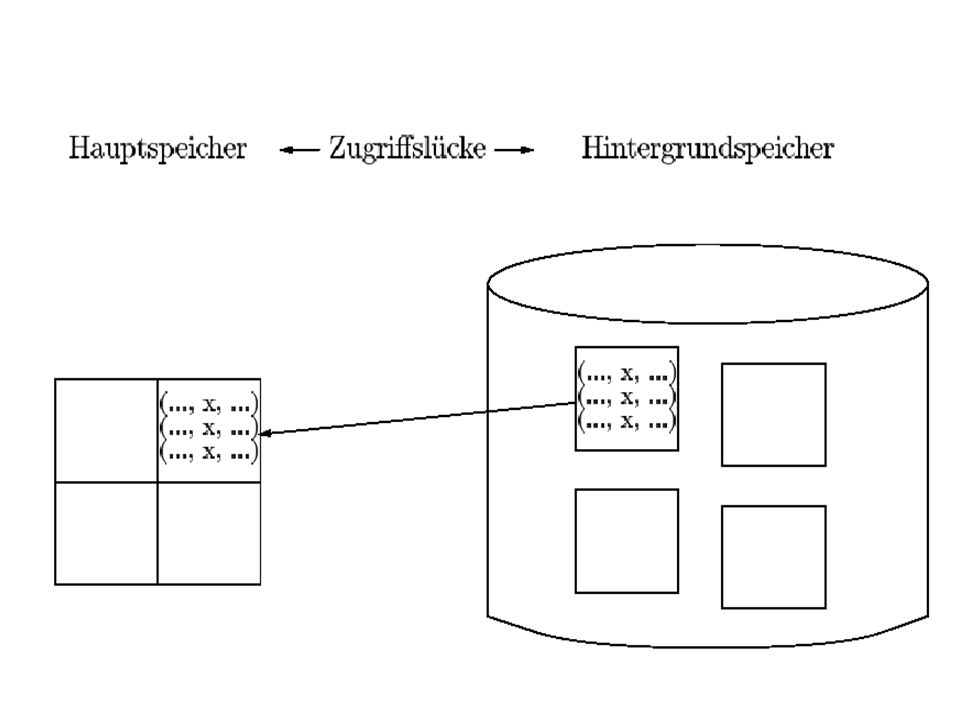
5
Buffer Manager: Verwaltet den Datenbankpuffer (buffer pool) im Hauptspeicher Bearbeitung von Daten kann immer nur im Hauptspeicher (und nicht direkt auf der Platte) geschehen.) Seiten müssen von der Platte in den Datenbankpuffer gelesen und später wieder auf die Platte zurück geschrieben werden. Buffer Manager ist für das Einlesen und Auslagern von Seiten zw. Datenbankpuffer und Platte verantwortlich. Die anderen Schichten des DBMS fordern einfach eine Seite an. Buffer Manager speichert zu jeder Seite im Puffer Information: ob die Seite noch verwendet wird: in diesem Fall darf die Seite nicht durch andere Seiten überschrieben werden. ob die Seite geändert wurde: nur in diesem Fall ist Zurückschreiben auf Platte nötig. Wird Seite noch verwendet? Dazu verwaltet Buffer Manager einen Pin-Count: Bei jeder Anforderung dieser Seite, wird der Pin-Count inkrementiert (pinning). Bei jeder Freigabe dieser Seite wird der Pin-Count dekrementiert (unpinning). Natürlich dürfen nur Seiten mit Pin-Count=0 aus Puffer verdrängt werden. Ob Seite verändert wurde, steht in Boolean flag „dirty“.
 geschehen.) Seiten müssen. von der Platte in den Datenbankpuffer gelesen und später. wieder auf die Platte zurück geschrieben werden. Buffer Manager ist für das Einlesen und Auslagern von Seiten. zw. Datenbankpuffer und Platte verantwortlich. Die anderen. Schichten des DBMS fordern einfach eine Seite an. Buffer Manager speichert zu jeder Seite im Puffer Information: ob die Seite noch verwendet wird: in diesem Fall darf die. Seite nicht durch andere Seiten überschrieben werden. ob die Seite geändert wurde: nur in diesem Fall ist. Zurückschreiben auf Platte nötig. Wird Seite noch verwendet Dazu verwaltet Buffer Manager einen Pin-Count: Bei jeder Anforderung dieser Seite, wird der Pin-Count inkrementiert (pinning). Bei jeder Freigabe dieser Seite wird der Pin-Count dekrementiert (unpinning). Natürlich dürfen nur Seiten mit Pin-Count=0 aus Puffer verdrängt werden. Ob Seite verändert wurde, steht in Boolean flag „dirty .")
6
Files and Access Methods Layer:
Die Zeilen einer DB-Tabelle (= Tupeln einer Relation) haben im allgemeinen nicht auf einer einzelnen Seite Platz. Logisch zusammengehörige Seiten werden als "File" verwaltet. Zwei Hauptaufgaben dieses Software Layers: Verwaltung der Seiten eines Files (entspricht üblicherweise einer Tabelle): "Heap file": Zufällige Verteilung der Tupeln auf die Seiten "Index file": Spezielle Verteilung der Tupeln auf die Seiten zwecks Optimierung bestimmter Zugriffe. Verwaltung der Tupeln innerhalb einer einzelnen Seite: Seitenformat: Tupeln mit fixer oder variabler Länge Zugriff der anderen SW-Schichten auf die einzelnen Tupeln: mit TID (Tupelidentifikator) (engl.: RID: record ID), d.h. Seiten-ID + Speicherplatz innerhalb der Seite
 haben. im allgemeinen nicht auf einer einzelnen Seite Platz. Logisch. zusammengehörige Seiten werden als File verwaltet. Zwei Hauptaufgaben dieses Software Layers: Verwaltung der Seiten eines Files (entspricht üblicherweise. einer Tabelle): Heap file : Zufällige Verteilung der Tupeln auf die Seiten. Index file : Spezielle Verteilung der Tupeln auf die Seiten. zwecks Optimierung bestimmter Zugriffe. Verwaltung der Tupeln innerhalb einer einzelnen Seite: Seitenformat: Tupeln mit fixer oder variabler Länge. Zugriff der anderen SW-Schichten auf die einzelnen Tupeln: mit TID (Tupelidentifikator) (engl.: RID: record ID), d.h. Seiten-ID + Speicherplatz innerhalb der Seite.")
7
Speicherhierarchie Primärer / sekundärer / tertiärer Speicher
Zugriffszeiten Puffer-Verwaltung Adressierung von Tupeln

8
Überblick: Speicherhierarchie
Register Cache Hauptspeicher Plattenspeicher Archivspeicher Primärspeicher Sekundärspeicher Tertiärspeicher

9
Überblick: Speicherhierarchie
Register Cache Hauptspeicher Plattenspeicher Archivspeicher 1 – 8 Byte Compiler 8 – 128 Byte Cache-Controller 4 – 64 KB Betriebssystem Benutzer

10
Überblick: Speicherhierarchie
1-10ns Register 10-100ns Cache ns Hauptspeicher 10 ms Plattenspeicher Archivspeicher: sec Zugriffslücke 105

11
Lesen von Daten von der Platte
Seek Time: Arm auf gewünschte Spur positionieren: ca. 5ms Latenzzeit (= "rotational delay"): Warten, bis sich der gesuchte Block am Kopf vorbeibewegt (durchschnittlich ½ Plattenumdrehung; Umdrehungen / min) ca. 3ms Transfer von der Platte zum Hauptspeicher: (100 Mb /s) ca. 15 MB/s Bemerkung: Sektor: physikalische Größe der Platte, meist 512B Block: kleinste Lese/Schreib- Einheit (= mehrere Sektoren), z.B.: 4kB, 8kB Ad rotational delay: Umdrehungen / min = 150 Umdrehnungen / sec => ca. 6 ms pro Umdrehung. => Im Durchschnitt reicht ½ Umdrehung bis zum gewünschten block, d.h.: 3 ms. Bemerkung: Early hard disks had the same number of sectors per track location, and in fact, the number of sectors in each track were fairly standard between models. Today's advances in drive technology have allowed the number of sectors per track, or SPT, to vary significantly. When a hard disk is prepared with its default values, each sector will be able to store 512 bytes of data. Without elaborating, there are a few operating system disk setup utilities that permit this 512 byte number per sector to be modified, however 512 is the standard, and found on virtually all hard drives by default. Each sector, however, actually holds much more than 512 bytes of information. Additional bytes are needed for control structures, information necessary to manage the drive, locate data and perform other functions. Exact sector structure depends on the drive manufacturer and model, however the contents of a sector usually include the following elements: ID Information Synchronization Fields: These are used internally by the drive controller to guide the read process. Data: The actual data in the sector. ECC: Error correcting code used to ensure data integrity. Gaps: Often referred to as spacers used to separate sector areas and provide time for the controller to process what it has been read before processing additional data.
: Warten, bis sich der. gesuchte Block am Kopf vorbeibewegt (durchschnittlich. ½ Plattenumdrehung; Umdrehungen / min) ca. 3ms. Transfer von der Platte zum Hauptspeicher: (100 Mb /s) ca. 15 MB/s. Bemerkung: Sektor: physikalische Größe. der Platte, meist 512B. Block: kleinste Lese/Schreib- Einheit (= mehrere Sektoren), z.B.: 4kB, 8kB. Ad rotational delay: Umdrehungen / min = 150 Umdrehnungen / sec => ca. 6 ms pro Umdrehung. => Im Durchschnitt reicht ½ Umdrehung bis zum gewünschten block, d.h.: 3 ms. Bemerkung: Early hard disks had the same number of sectors per track location, and in fact, the number of sectors in each track were fairly standard between models. Today s advances in drive technology have allowed the number of sectors per track, or SPT, to vary significantly. When a hard disk is prepared with its default values, each sector will be able to store 512 bytes of data. Without elaborating, there are a few operating system disk setup utilities that permit this 512 byte number per sector to be modified, however 512 is the standard, and found on virtually all hard drives by default. Each sector, however, actually holds much more than 512 bytes of information. Additional bytes are needed for control structures, information necessary to manage the drive, locate data and perform other functions. Exact sector structure depends on the drive manufacturer and model, however the contents of a sector usually include the following elements: ID Information. Synchronization Fields: These are used internally by the drive controller to guide the read process. Data: The actual data in the sector. ECC: Error correcting code used to ensure data integrity. Gaps: Often referred to as spacers used to separate sector areas and provide time for the controller to process what it has been read before processing additional data.")
12
Random versus Chained IO
Beispiel: 1000 Blöcke à 4KB sind zu lesen Random I/O Jedes Mal Arm positionieren Jedes Mal Latenzzeit 1000 * (5 ms + 3 ms) + Transferzeit von 4 MB ca ms + 300ms 8s Chained I/O Ein Mal positionieren, dann "von der Platte kratzen" 5 ms + 3ms + Transferzeit von 4 MB ca. 8ms ms 1/3 s Also ist chained IO ein bis zwei Größenordnungen schneller als random IO in Datenbank-Algorithmen unbedingt beachten!
 + Transferzeit von 4 MB. ca ms + 300ms 8s. Chained I/O. Ein Mal positionieren, dann von der Platte kratzen 5 ms + 3ms + Transferzeit von 4 MB. ca. 8ms ms 1/3 s. Also ist chained IO ein bis zwei Größenordnungen schneller. als random IO in Datenbank-Algorithmen unbedingt beachten!")
13
Datenbankpuffer-Verwaltung
Hauptspeicher einlagern verdrängen Bemerkung: DBMS greift nie direkt auf eine Seite (= Block) des Hintergrundspeichers zu Seite muss zuerst in den Hauptspeicher (Datenbank- puffer) gelesen werden. Platte ~ persistente DB
 des. Hintergrundspeichers zu. Seite muss zuerst in den. Hauptspeicher (Datenbank- puffer) gelesen werden. Platte ~ persistente DB.")
14
Ein- und Auslagern von Seiten
DB-Puffer ist in Seitenrahmen gleicher Größe aufgeteilt. Ein Rahmen kann eine Seite aufnehmen. "Überzählige" Seiten werden auf die Platte ausgelagert. Hauptspeicher 4K 8K 12K Platte P123 16K 20K 24K 28K P480 32K 36K 40K 44K Brauche Ersetzungspolitik (weil irgendwann der Puffer voll ist) Ideal: möglichst lange nicht mehr gebrauchte Seiten (LRU = least recently used). Es gibt aber auch andere Strategien: clock replacement, FIFO, MRU (= most recently used), random 48K 52K 56K 60K Seitenrahmen Seite
 Ideal: möglichst lange nicht mehr gebrauchte Seiten (LRU = least recently used). Es gibt aber auch andere Strategien: clock replacement, FIFO, MRU (= most recently used), random. 48K. 52K. 56K. 60K. Seitenrahmen. Seite.")
15
Adressierung von Tupeln auf dem Hintergrundspeicher
Vgl. Ramakrishnan, p.326ff: Es gibt versch. Arten des Page Format: Fixed length => TID könnte einfach slot-Nummer innerhalb der Page haben Variable length => TID könnte den Offset innerhalb der Page haben Nachteil: Beim Verschieben innerhalb der Page würde sich der TID ändern Flexibelste Lösung: mittels slot directory (Datensatztabelle): -> nur diese Lösung ist hier beschrieben. Spezialfall: ev. Passt ein Record nicht in eine Page (insbes. Bei CLOB und BLOB) -> DBs speichern diese Felder bzw. diese Records in linked list of pages.
: -> nur diese Lösung ist hier beschrieben. Spezialfall: ev. Passt ein Record nicht in eine Page (insbes. Bei CLOB und BLOB) -> DBs speichern diese Felder bzw. diese Records in linked list of pages.")
16
Verschiebung innerhalb einer Seite
Verschieben innerhalb der Seite (oder gar auf andere Seite) kann nur bei records mit variables Länge passieren!!
 kann nur bei records mit variables Länge passieren!!")
17
Verschiebung von einer
Seite auf eine andere Forward

18
Verschiebung von einer
Seite auf eine andere Bei der nächsten Verschiebung wird der „Forward“ auf Seite 4711 geändert (kein Forward auf Seite 4812)
")
19
Hintergrundspeicher / RAID

20
Disk Arrays RAID-Systeme

21
RAID Abkürzung: ursprünglich: redundant array of inexpensive disks
mittlerweile: redundant array of independent disks Idee: mehrere kleine Platten an Stelle von einer großen Platte "inexpensive disks" (ursprüngliche Idee von RAID): Kleine Platten sind wesentlich billiger als große Platten. (nicht zuletzt wegen Erfolg von RAID): ausreichend große Platten werden mittlerweile nicht einmal mehr hergestellt. "independent disks": Parallele Schreib/Lese-Zugriffe auf die Platten möglich Nach außen: über RAID-Controller sieht Speicherarray logisch wie eine einzige, große Platte aus.
: Kleine Platten sind wesentlich billiger als große Platten. (nicht zuletzt wegen Erfolg von RAID): ausreichend große. Platten werden mittlerweile nicht einmal mehr hergestellt. independent disks : Parallele Schreib/Lese-Zugriffe auf die Platten möglich. Nach außen: über RAID-Controller sieht Speicherarray. logisch wie eine einzige, große Platte aus.")
22
RAID Levels Es gibt 8 RAID-Levels (für unterschiedliche Zielsetzungen): RAID 0, 1, 0+1 (auch RAID 10 genannt), 2, 3, 4, 5, 6 "Striping" (= Verteilung der Daten auf mehrere Platten): ermöglicht parallelen Schreib/Lese-Zugriff Problem: Ausfallswahrscheinlichkeit steigt mit der Anzahl der Platten Redundanz : "Mirroring" (= mehrfaches Abspeichern der Daten): ermöglicht parallelen Lese-Zugriff Abspeichern von Fehlererkennungs- und Korrekturcodes: ermöglicht Rekonstruktion der Daten bei Ausfall einer Platte. Beispiel für Lesen vs. Schreiben: eigene Paritätsplatte: kann beim Lesen ignoriert werden. Ist beim Schreiben ev. Ein bottleneck.
: ermöglicht parallelen Schreib/Lese-Zugriff. Problem: Ausfallswahrscheinlichkeit steigt mit der Anzahl. der Platten. Redundanz : Mirroring (= mehrfaches Abspeichern der Daten): ermöglicht parallelen Lese-Zugriff. Abspeichern von Fehlererkennungs- und Korrekturcodes: ermöglicht Rekonstruktion der Daten bei Ausfall einer Platte. Beispiel für Lesen vs. Schreiben: eigene Paritätsplatte: kann beim Lesen ignoriert werden. Ist beim Schreiben ev. Ein bottleneck.")
23
RAID 0: Striping Datei A B C D A B C D
Lastbalancierung wenn alle Blöcke mit gleicher Häufigkeit gelesen/geschrieben werden Doppelte Bandbreite beim sequentiellen Lesen der Datei bestehend aus den Blöcken ABCD... Datenverlust wird immer wahrscheinlicher, je mehr Platten man verwendet (Stripingbreite = Anzahl der Platten, hier 2)
")
24
RAID 1: Spiegelung (mirroring)
B A B C D C D Datensicherheit: durch Redundanz aller Daten Doppelter Speicherbedarf Lastbalancierung beim Lesen: z.B. kann Block A von der linken oder der rechten Platte gelesen werden Aber beim Schreiben müssen beide Kopien geschrieben werden Kann aber im Allgemeinen nicht parallel geschehen wegen Datenverlust (z.B. bei Stromausfall)
")
25
Zusammenfassung: RAID Levels
RAID 0: Striping (blockweise) RAID 1: Mirroring RAID 0+1 (= RAID 10): kombiniert Striping und Mirroring RAID 2, 3, 4, 5, 6: unterschiedliche Kombinationen von Ideen: Striping auf Bit (oder Byte)-Ebene bzw. blockweise Umfang des Fehlererkennungs- und Korrekturcodes: Rekonstruktion der Daten bei Ausfall einer einzelnen Platte bzw. auch bei Ausfall von 2 Platten möglich Speicherort des Fehlererkennungs- und Korrekturcodes: auf alle Laufwerke verteilt bzw. auf zusätzlicher Platte Korrektur-Codes: Paritätsinformation: 1 Platte rekonstruierbar Hamming-Code: Zusätzlich: erkennt, welche Platte defekt ist (das kann aber auch der Disk-controller) Reed-Solomon Code: 2 Platten rekonstruierbar
 RAID 1: Mirroring. RAID 0+1 (= RAID 10): kombiniert Striping und Mirroring. RAID 2, 3, 4, 5, 6: unterschiedliche Kombinationen von Ideen: Striping auf Bit (oder Byte)-Ebene bzw. blockweise. Umfang des Fehlererkennungs- und Korrekturcodes: Rekonstruktion der Daten bei Ausfall einer einzelnen Platte. bzw. auch bei Ausfall von 2 Platten möglich. Speicherort des Fehlererkennungs- und Korrekturcodes: auf alle Laufwerke verteilt bzw. auf zusätzlicher Platte. Korrektur-Codes: Paritätsinformation: 1 Platte rekonstruierbar. Hamming-Code: Zusätzlich: erkennt, welche Platte defekt ist (das kann aber auch der Disk-controller) Reed-Solomon Code: 2 Platten rekonstruierbar.")
26
B-Bäume B+-Bäume Hashing R-Bäume
Index-Verfahren B-Bäume B+-Bäume Hashing R-Bäume Ab jetzt werden (dieser und nächster Termin) nur noch Index-methoden beschrieben: Einfachste Methode: ISAM: Problem: Überlaufseiten; Beschreibung in Kemper ist aber problematisch: lt. Ramakrishnan ist nicht die Index-Info auf sequentiellen Seiten abgespeichert sondern die eigentlichen Daten! Heute: B, B+, Präfix-B Bäume Nächstes Mal: Heap, R-Bäume
 nur noch Index-methoden beschrieben: Einfachste Methode: ISAM: Problem: Überlaufseiten; Beschreibung in Kemper ist aber problematisch: lt. Ramakrishnan ist nicht die Index-Info auf sequentiellen Seiten abgespeichert sondern die eigentlichen Daten! Heute: B, B+, Präfix-B Bäume. Nächstes Mal: Heap, R-Bäume.")
27
B-Bäume Problemstellung:
"Normale" Binär-Bäume (wie AVL-Bäume, Rot/Schwarz-Bäume) sind gut geeignet für den Hauptspeicher. Bei Datenbanken benötigt man ein Verfahren, das auf die Seitengröße des Hintergrundspeichers abgestimmt ist. Lösung: B-Bäume (oder B+-Bäume) Idee von B-Bäumen (und B+-Bäumen): Die Knotengröße entspricht der Seitengröße. Der Verzweigungsgrad des Baums hängt davon ab, wie viele Einträge auf einer Seite Platz haben. Durch entsprechende Algorithmen für das Einfügen und Löschen von Daten wird garantiert, dass der Baum immer ausbalanciert ist => Logarithmische Zugriffszeiten.
 sind gut geeignet für den Hauptspeicher. Bei Datenbanken benötigt man ein Verfahren, das auf die Seitengröße des Hintergrundspeichers abgestimmt ist. Lösung: B-Bäume (oder B+-Bäume) Idee von B-Bäumen (und B+-Bäumen): Die Knotengröße entspricht der Seitengröße. Der Verzweigungsgrad des Baums hängt davon ab, wie viele Einträge auf einer Seite Platz haben. Durch entsprechende Algorithmen für das Einfügen und Löschen von Daten wird garantiert, dass der Baum immer ausbalanciert ist => Logarithmische Zugriffszeiten.")
28
S.. Suchschlüssel D.. Weitere Daten V.. Verweise (SeitenNr)
")
29
Ergänze: Wurzel hat mindestens 1 und höchstens 2 k Einträge.

31
Einfügen eines neuen Objekts (Datensatz) in einen B-Baum
Bemerkung: Verschieben von Tupeln ist natürlich ein Problem, wenn mit TIDs auf diese Tupeln verwiesen wird => alle anderen Indexe, die auf so einen TID verweisen, müssen upgedated werden!

32
Beispiel 1 B-Baum vom Grad k = 2
Ausgangssituation: 1 Knoten mit Schlüssel-Werten 10, 13, 19 Sukzessiver Aufbau des Baums durch das Einfügen neuer Schlüssel-Werte: 7, 3, 1, 2, 4

33
Beispiel 1 7 10 13 19

34
Beispiel 1 3 7 10 13 19

35
Beispiel 1 ? 3 7 10 13 19

36
Beispiel 1 ? 3 7 10 13 19

37
Beispiel 1 10 ? 3 3 7 13 19

38
Beispiel 1 10 ? 3 7 13 19

39
Beispiel 1 1 10 ? 3 7 13 19

40
Beispiel 1 1 10 ? 3 7 13 19

41
Beispiel 1 10 ? 1 3 7 13 19

42
Beispiel 1 10 ? 1 1 3 7 13 19

43
Beispiel 1 2 10 ? 1 3 7 13 19

44
Beispiel 1 2 10 ? 2 1 3 7 13 19

45
Beispiel 1 2 10 ? 2 1 2 3 7 13 19

46
Beispiel 1 4 10 ? 1 2 3 7 13 19

47
Beispiel 1 4 10 ? 4 1 2 3 7 13 19

48
Beispiel 1 4 10 ? 4 1 2 3 7 13 19

49
Beispiel 1 4 10 ? 4 1 2 3 7 13 19

50
Beispiel 1 4 3 ? 10 4 1 2 3 7 13 19

51
Beispiel 1 3 ? 10 1 2 13 19 4 7

52
Beispiel 2 B-Baum vom Grad k = 2 Ausgangssituation: Baum der Tiefe 2
Die Wurzel hat bereits den maximalen Füllstand erreicht Einfügen eines weiteren Knotens führt zur Teilung eines Blattknotens Teilung des Blattknotens führt nun zur Teilung der Wurzel Resultat: Baum der Tiefe 3

53
Beispiel 2 8 3 ? 10 13 19 1 2 20 21 14 15 4 5 6 7 11 12

54
Beispiel 2 8 3 ? 10 13 19 1 2 20 21 14 15 8 4 5 6 7 11 12

55
Beispiel 2 8 3 ? 10 13 19 1 2 20 21 14 15 8 4 5 6 7 11 12

56
Beispiel 2 8 3 ? 10 13 19 1 2 20 21 14 15 8 4 5 6 7 11 12

57
Beispiel 2 8 3 ? 10 13 19 1 2 20 21 4 5 14 15 8 6 7 11 12

58
Beispiel 2 6 3 ? 10 13 19 1 2 20 21 4 5 6 14 15 7 8 11 12

59
Beispiel 2 6 3 ? 10 13 19 1 2 20 21 4 5 14 15 7 8 11 12

60
Beispiel 2 6 3 ? 10 13 19 1 2 20 21 4 5 14 15 7 8 11 12

61
Beispiel 2 6 3 ? 10 13 19 1 2 20 21 4 5 14 15 7 8 11 12

62
Beispiel 2 6 3 6 3 ? 10 13 19 1 2 20 21 4 5 14 15 7 8 11 12

63
Beispiel 2 10 3 6 13 ? 19 1 2 20 21 4 5 14 15 7 8 11 12

64
Beispiel 2 10 3 6 13 ? 19 1 2 20 21 4 5 14 15 7 8 11 12

65
Beispiel 2 10 10 3 6 13 ? 19 1 2 20 21 4 5 14 15 7 8 11 12

66
Beispiel 2 B-Baum mit Minimaler Speicherplatz- ausnutzung 10 3 6 13 ? 19 1 2 20 21 4 5 14 15 7 8 11 12
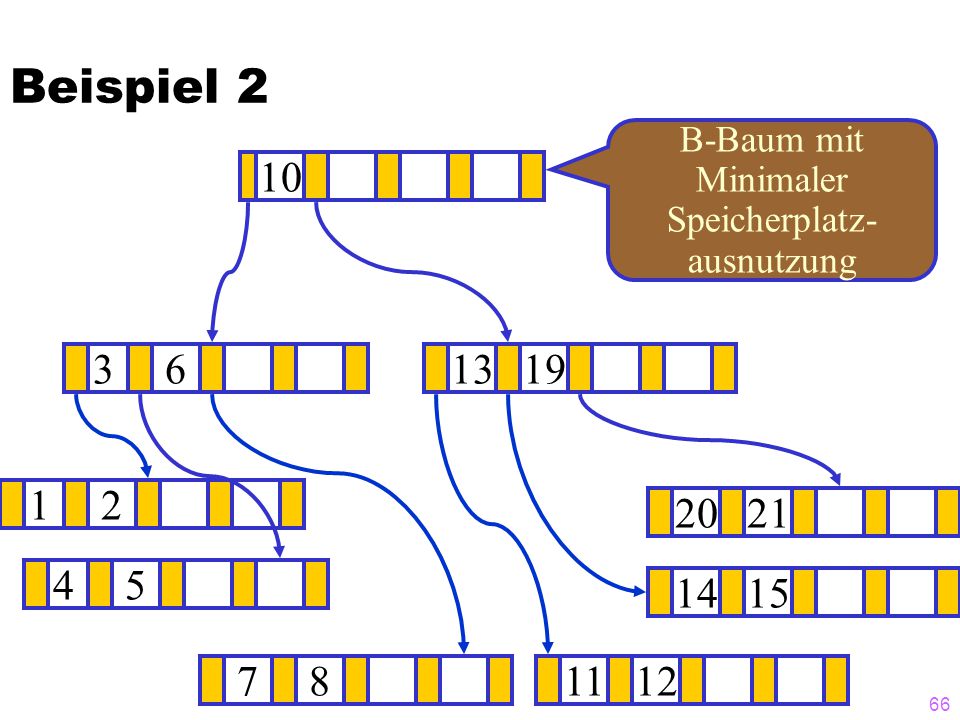
67
Beispiel 3 B-Baum vom Grad k = 2
Ausgangssituation: Einige Knoten haben minimalen Füllstand Löschen von Schlüsselwerten führt zu Unterlauf ) Ausgleich mit einem Nachbarknoten erforderlich.
 Ausgleich mit einem Nachbarknoten erforderlich.")
68
Beispiel 3 10 3 6 13 ? 19 1 2 20 21 23 4 5 14 15 7 8 11 12

69
Beispiel 3 14 10 3 6 13 ? 19 1 2 20 21 23 4 5 14 15 7 8 11 12

70
Beispiel 3 14 10 Unterlauf 3 6 13 ? 19 1 2 20 21 23 4 5 14 15 7 8 11 12

71
Beispiel 3 10 Unterlauf 3 6 13 ? 19 1 2 20 21 23 4 5 15 7 8 11 12

72
Beispiel 3 10 3 6 13 ? 20 1 2 21 23 4 5 15 19 7 8 11 12

73
Beispiel 4 B-Baum vom Grad k = 2 Ausgangssituation: Baum der Tiefe 3
Einige Knoten haben minimalen Füllstand Löschen von Schlüsselwerten führt zu Unterlauf Da die Nachbarknoten ebenfalls minimalen Füllstand haben, müssen 2 Knoten verschmolzen werden. Durch das Verschmelzen kann es zu einem Unterlauf des Vaterknotens kommen. ) Vorgang wird wiederholt. Resultat: Baum der Tiefe 2 Je nach Definition ist die Tiefe des Baumes verschieden (Ramakrishnan/Gehrke etwa vergeben für einen Baum bestehend nur aus der Wurzel die Tiefe 0)
 Vorgang wird wiederholt. Resultat: Baum der Tiefe 2. Je nach Definition ist die Tiefe des Baumes verschieden (Ramakrishnan/Gehrke etwa vergeben für einen Baum bestehend nur aus der Wurzel die Tiefe 0)")
74
Beispiel 4 5 10 3 6 13 ? 20 1 2 21 23 4 5 15 19 7 8 11 12

75
Beispiel 4 5 10 3 6 13 ? 20 1 2 21 23 4 5 15 19 Unterlauf 7 8 11 12

76
Beispiel 4 10 3 6 13 ? 20 1 2 21 23 4 15 19 merge 7 8 11 12

77
Beispiel 4 10 3 6 13 ? 20 1 2 21 23 4 15 19 merge 7 8 11 12

78
Beispiel 4 10 Unterlauf 3 13 ? 20 1 2 21 23 4 6 7 8 15 19 11 12

79
Beispiel 4 10 merge 3 13 ? 20 1 2 21 23 4 6 7 8 15 19 11 12

80
Beispiel 4 10 merge 3 13 ? 20 1 2 21 23 4 6 7 8 15 19 11 12

81
Beispiel 4 3 10 13 20 ? 1 2 21 23 4 6 7 8 15 19 11 12

82
Beispiel 4 Schrumpfung, Freie Knoten 3 10 13 20 ? 1 2 21 23 4 6 7 8 15
19 11 12
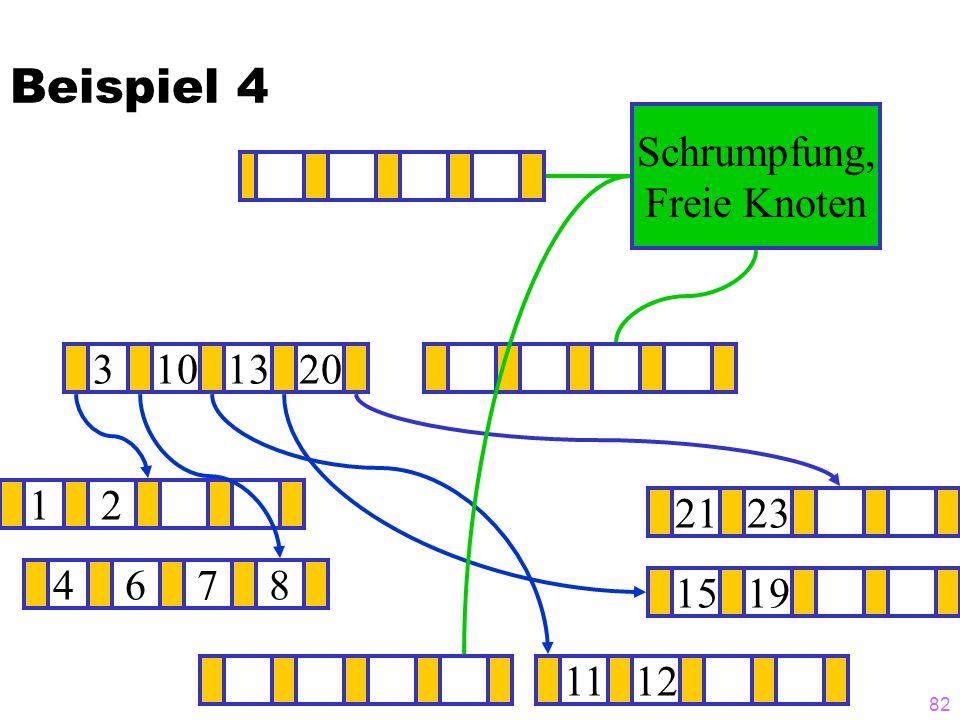
83
Beispiel 4 3 10 13 20 1 2 21 23 4 6 7 8 15 19 11 12

84
Speicherstruktur eines B-Baums auf dem Hintergrundspeicher
4 Speicherblock Nr 4

85
Speicherstruktur eines B-Baums auf dem Hintergrundspeicher
8 KB-Blöcke 0*8KB 1*8KB 3 2*8KB 3*8KB 4*8KB Block- Nummer Datei

86
Speicherstruktur eines B-Baums auf dem Hintergrundspeicher
8 KB-Blöcke 0*8KB 1*8KB 3 2*8KB 3*8KB 4*8KB Block- Nummer Datei

87
Speicherstruktur eines B-Baums auf dem Hintergrundspeicher
8 KB-Blöcke 0*8KB 1 1*8KB 3 1 2*8KB 1 3*8KB Freispeicher- Verwaltung 4*8KB 1 Block- Nummer Datei

88
Zusammenspiel: Hintergrundspeicher -- Hauptspeicher
Datenbank- Puffer Hintergrundspeicher 4 4 Zugriffslücke 105

89
B+-Bäume Ziel bei B-Bäumen: geringe Tiefe. Dafür benötigt man
hohen Verzweigungsgrad (d.h.: viele Kinder pro Knoten) Verzweigungsgrad wird bestimmt durch die Anzahl der Datensätze in einem Knoten Idee von B+-Bäumen: Daten werden ausschließlich in den Blättern gespeichert Die inneren Knoten dienen nur noch der Navigation, d.h.: Sie enthalten Referenzschlüssel und Verweise (aber keine weiteren Daten). Da Referenzschlüssel im allgemeinen weniger Platz brauchen als vollst. Datensätze, erhöht sich der Verzweigungsgrad. Zusätzlicher Vorteil: Durch Verkettung der Blattknoten lassen sich Bereichsanfragen effizient beantworten.
 Verzweigungsgrad wird bestimmt durch die Anzahl der. Datensätze in einem Knoten. Idee von B+-Bäumen: Daten werden ausschließlich in den Blättern gespeichert. Die inneren Knoten dienen nur noch der Navigation, d.h.: Sie enthalten Referenzschlüssel und Verweise (aber keine weiteren Daten). Da Referenzschlüssel im allgemeinen weniger Platz brauchen als vollst. Datensätze, erhöht sich der Verzweigungsgrad. Zusätzlicher Vorteil: Durch Verkettung der Blattknoten lassen sich Bereichsanfragen effizient beantworten.")
90
B+-Baum Referenz- schlüssel Such- schlüssel

91
Präfix B+-Bäume Idee: An den inneren Knoten werden nur Referenzschlüssel benötigt. Die Werte der Referenzschlüssel dienen nur der Navigation und müssen nicht unbedingt in den Daten existieren. Beispiel: Anforderung an Referenzschlüssel R : Kant < R ≤ Popper Bemerkung: Kleiner Fehler im Buch: dort steht, dass links die Schlüssel ≤ R sein müssen und nicht < R. P Bei Kemper steht, dass links von einem Referenzschlüssel R alle Suchschlüssel kleiner gleich R wären. Bei Ramakrishnan ist‘s so, dass links die echt kleineren Suchschlüssel sind. Letztlich ist‘s egal. Aber bei Präfix klingt‘s mir fast plausibler, dass links echt kleinere Schlüssel stehen, z.B.: Referenzschlüssel B,C, … bedeuten, dass die Teilbäume an den Kindern jeweils alle Wörter mit A, alle Wörter mit B, alle Wörter mit C, … enthalten. Aber vor allem bei integers ist‘s völlig wurscht. Hauptsache es ist klar definiert. Curie Kant Popper Russel

92
Idee von Hashing Direkte Abbildung von Werten eines Such-Schlüssels auf einen bestimmten Speicherbereich. Aufteilung des Speichers in "Buckets". Jedes Bucket besteht aus einer primären Seite sowie möglicherweise 1 oder mehreren Überlaufseiten. Mittels Hashfunktion h: S ! B wird jedem Schlüsselwert eindeutig eine Bucket-Nummer zugeordnet. Gebräuchlichste Hashfunktionen: h(x) = x mod N (N = Anzahl der Buckets) oder: h(x) = (a*x + b) mod N (für geeignete Wahl von Konstanten a und b) "Gute Hashfunktion": möglichst gleichmäßige Verteilung der möglichen Schlüsselwerte auf die Buckets. h(x) = x mod N := „Divisionsrestverfahren“
 = x mod N (N = Anzahl der Buckets) oder: h(x) = (a*x + b) mod N. (für geeignete Wahl von Konstanten a und b) Gute Hashfunktion : möglichst gleichmäßige Verteilung der. möglichen Schlüsselwerte auf die Buckets. h(x) = x mod N := „Divisionsrestverfahren")
93
Statisches Hashing A priori Allokation des Speichers, d.h.: jedes Bucket besteht exakt aus 1 Seite (= primäre Seite). Bei Überlauf einer Seite wird eine weitere Seite zum Bucket hinzugefügt (= Überlaufseite). Mit der Zeit können sehr viele Überlaufseiten entstehen => Suchen innerhalb eines Buckets wird teuer. Lösung 1: Nachträgliche Vergrößerung der Hashtabelle Rehashing der Einträge Hashfunktion h(...) = ... mod N wird ersetzt durch h(...) = ... mod M (mit M > N) In Datenbankanwendungen: viele GB ) sehr teuer Lösung 2: Erweiterbares Hashing
. Mit der Zeit können sehr viele Überlaufseiten entstehen. => Suchen innerhalb eines Buckets wird teuer. Lösung 1: Nachträgliche Vergrößerung der Hashtabelle. Rehashing der Einträge. Hashfunktion h(...) = ... mod N wird ersetzt durch. h(...) = ... mod M (mit M > N) In Datenbankanwendungen: viele GB ) sehr teuer. Lösung 2: Erweiterbares Hashing.")
94
Statisches Hashing Hier: Hash-Funktion = MatrNr mod 3

95
Erweiterbares Hashing
zusätzliche Indirektion über ein Directory Directory enthält einen Zeiger (Seiten-Nr) des Hash-Bucket Dynamisches Wachsen und Schrumpfen ist möglich (ohne Überlaufseiten). Der Zugriff auf das Directory erfolgt über einen binären Hashcode (d.h.: Strings aus 0 und 1). Der Zugriff auf die Buckets erfolgt im Stil eines (i.a. nicht ausbalancierten) binären Entscheidungsbaums (= "Trie"). Jeder Pfad im Trie entspricht einem String aus 0 und 1. A trie (from retrieval), is a multi-way tree structure useful for storing strings over an alphabet. It has been used to store large dictionaries of English (say) words in spelling-checking programs and in natural-language "understanding" programs. The idea is that all strings sharing a common stem or prefix hang off a common node. When the strings are words over {a..z}, a node has at most 27 children - one for each letter plus a terminator. The elements in a string can be recovered in a scan from the root to the leaf that ends a string. All strings in the trie can be recovered by a depth-first scan of the tree.
 des Hash-Bucket. Dynamisches Wachsen und Schrumpfen ist möglich. (ohne Überlaufseiten). Der Zugriff auf das Directory erfolgt über einen binären. Hashcode (d.h.: Strings aus 0 und 1). Der Zugriff auf die Buckets erfolgt im Stil eines (i.a. nicht. ausbalancierten) binären Entscheidungsbaums (= Trie ). Jeder Pfad im Trie entspricht einem String aus 0 und 1. A trie (from retrieval), is a multi-way tree structure useful for storing strings over an alphabet. It has been used to store large dictionaries of English (say) words in spelling-checking programs and in natural-language understanding programs. The idea is that all strings sharing a common stem or prefix hang off a common node. When the strings are words over {a..z}, a node has at most 27 children - one for each letter plus a terminator. The elements in a string can be recovered in a scan from the root to the leaf that ends a string. All strings in the trie can be recovered by a depth-first scan of the tree.")
98
Hashfunktion für erweiterbares Hashing
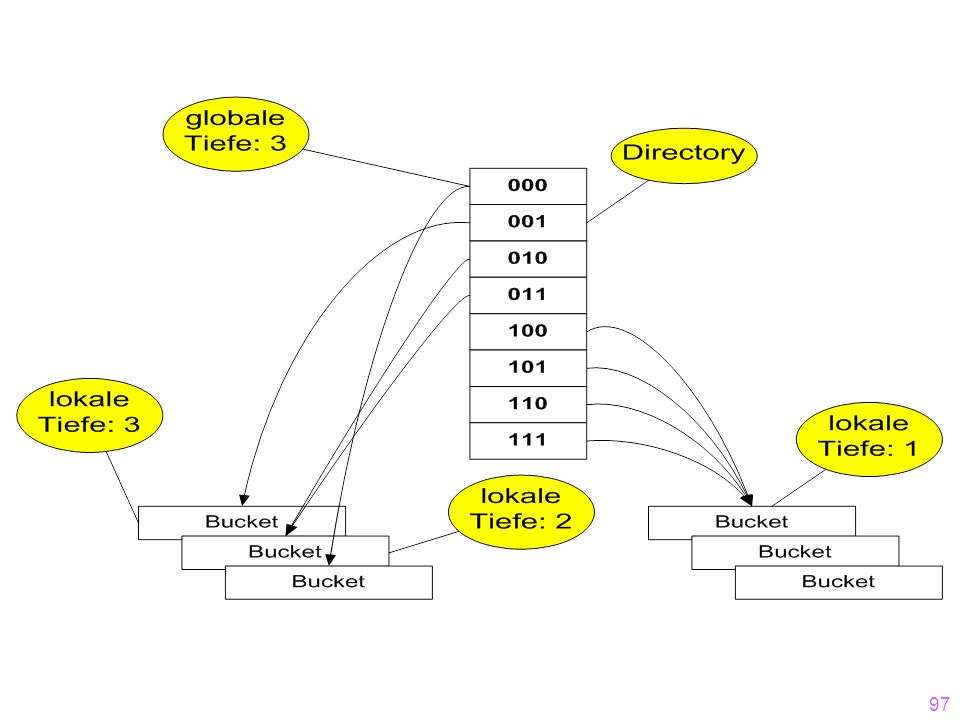
h: Schlüsselmenge {0,1}* Der Bitstring muss lang genug sein, um alle Objekte auf ihre Buckets abbilden zu können Anfangs wird nur ein (kurzer) Präfix des Hash-Wertes (Bitstrings) benötigt. Wenn die Hashtabelle wächst, wird aber sukzessive ein längerer Präfix benötigt. ) Das Directory wird jeweils verdoppelt. Globale Tiefe (des Directory): Momentan verwendete Anzahl der Bits in den Hashwerten des Directory (= max. Länge der Pfade des binären Trie). Lokale Tiefe (jedes einzelnen Bucket): Länge des Pfades (im binären Trie) der auf dieses Bucket zeigt.
 Präfix des Hash-Wertes. (Bitstrings) benötigt. Wenn die Hashtabelle wächst, wird aber sukzessive ein. längerer Präfix benötigt. ) Das Directory wird jeweils. verdoppelt. Globale Tiefe (des Directory): Momentan verwendete Anzahl. der Bits in den Hashwerten des Directory (= max. Länge der. Pfade des binären Trie). Lokale Tiefe (jedes einzelnen Bucket): Länge des Pfades. (im binären Trie) der auf dieses Bucket zeigt.")
99
Beispiel- Hashfunktion: gespiegelte PersNr
Namensgebung: Hashcode „dp“ beseht aus 2 Teilen: d = Teil der im Moment genützt wird (hier nur 1 Bit), um auf‘s Verzeichnis zuzugreifen. p = Rest, d.h.: Teil der im Moment nicht genützt wird.
, um auf‘s Verzeichnis zuzugreifen. p = Rest, d.h.: Teil der im Moment nicht genützt wird.")
101
R-Bäume Ursprüngliche Motivation: Indexe für geometrische Daten
Allgemeine Verwendungsmöglichkeit: Indexierung von mehreren Attributen (= Dimensionen) R-Baum = balancierter Baum. Die inneren Knoten dienen nur der Navigation; Daten nur an den Blättern (wie B+-Baum). Einträge eines inneren Knoten: Anstelle eines Referenzschlüssels enthält jeder Eintrag die Beschreibung einer n-dimensionalen "Box". Verweis auf einen Nachfolger-Knoten. Alle Datenpunkte bzw. alle Boxes der Nachfolger müssen innerhalb der Box des Vorgängers liegen.
 R-Baum = balancierter Baum. Die inneren Knoten dienen nur. der Navigation; Daten nur an den Blättern (wie B+-Baum). Einträge eines inneren Knoten: Anstelle eines Referenzschlüssels enthält jeder Eintrag. die Beschreibung einer n-dimensionalen Box . Verweis auf einen Nachfolger-Knoten. Alle Datenpunkte. bzw. alle Boxes der Nachfolger müssen innerhalb der Box. des Vorgängers liegen.")
102
R-Baum: Urvater der baum-strukturierten mehrdimensionalen Zugriffsstrukturen

103
Gute vs. schlechte Partitionierung
Problem bei mehr-dimensionalen Daten: es gibt keine totale Ordnung => Man hat mehrere Möglichkeiten, eine Box in mehrere Unter-Boxen zu unterteilen.

104
Nächste Phase in der Entstehungsgeschichte des R-Baums

105
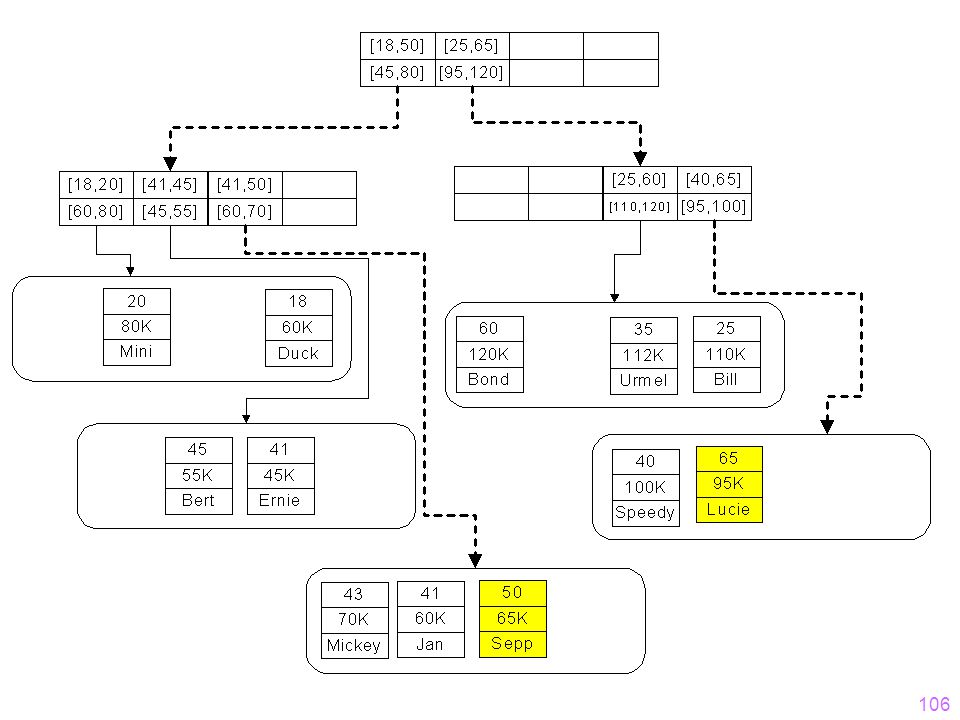
Bereichsanfragen auf dem R-Baum
Beispiel: finde alle Tupel mit Alter in [47,67] und Gehalt in [55K,115K]. Idee: - Hier: Suche alle Tupel mit Alter in [47,67] und Alle Daten

107
Logisch verwandte Daten liegen am Hintergrundspeicher nahe beieinander
Ballung Logisch verwandte Daten liegen am Hintergrundspeicher nahe beieinander

108
Objektballung / Clustering logisch verwandter Daten

111
Indexe und Ballung Geballter Index = Index, bei dem die Anordnung der
Daten-Tupel der Ordnung der Einträge im Index entspricht. Beispiel: Angenommen, die Zeilen der Tabelle Student sind auf der Platte nach MatrNr sortiert. Index für Attribut MatrNr: geballt Index für Attribut Semester: nicht geballt Nutzen der Ballung bei unterschiedlichen Anfragen: Punktanfrage (exact match): Ballung irrelevant Bereichsanfrage (range selection): Ballung entscheidend Beispiel: Select * From Studenten Where Semester > 6; bei geballtem Index: Suche ersten Treffer (mittels Index) und durchlaufe ab hier alle Datensätze, solange die Bedingung erfüllt ist.
: Ballung irrelevant. Bereichsanfrage (range selection): Ballung entscheidend. Beispiel: Select * From Studenten Where Semester > 6; bei geballtem Index: Suche ersten Treffer (mittels Index) und. durchlaufe ab hier alle Datensätze, solange die Bedingung erfüllt ist.")
112
Index-Einträge und Daten
Zwei Alternativen: Der Index enthält (neben der Steuerinformation des Index) die Daten selbst, z.B.: B+-Index: Zeilen der Tabelle stehen in den Blattknoten Hash-Index: Zeilen der Tabelle stehen in den Buckets Der Index enthält nur Verweise auf die Daten, d.h.: TIDs Auswirkung auf Ballung: Index mit Alternative 1 ist immer geballt. Index mit Alternative 2 kann geballt sein (falls die Zeilen der Tabelle entsprechend dem Suchschlüssel sortiert sind)
 die Daten selbst, z.B.: B+-Index: Zeilen der Tabelle stehen in den Blattknoten. Hash-Index: Zeilen der Tabelle stehen in den Buckets. Der Index enthält nur Verweise auf die Daten, d.h.: TIDs. Auswirkung auf Ballung: Index mit Alternative 1 ist immer geballt. Index mit Alternative 2 kann geballt sein (falls die Zeilen der. Tabelle entsprechend dem Suchschlüssel sortiert sind)")
113
Verweis auf Datensatz mittels Tupelidentifikator (TID)
")
115
Mehrere Indexe auf denselben Objekten
B-Baum Mit (PersNr, Daten) Einträgen B-Baum Mit (Alter, ???) Einträgen Alter, PersNr Name, Alter, Gehalt ...
 Einträgen. B-Baum. Mit. (Alter, ) Einträgen. Alter, PersNr. Name, Alter, Gehalt ...")
116
Mehrere Indexe auf denselben Objekten
Wer ist 20 ? B-Baum Mit (PersNr, Daten) Einträgen B-Baum Mit (Alter, ???) Einträgen 20, 007 Alter, PersNr Name, Alter, Gehalt ...
 Einträgen. B-Baum. Mit. (Alter, ) Einträgen. 20, 007. Alter, PersNr. Name, Alter, Gehalt ...")
117
Mehrere Indexe auf denselben Objekten
Wer ist 20 ? B-Baum Mit (PersNr, Daten) Einträgen B-Baum Mit (Alter, ???) Einträgen 007,Bond,20,... 20, 007 Alter, PersNr Name, Alter, Gehalt ...
 Einträgen. B-Baum. Mit. (Alter, ) Einträgen. 007,Bond,20,... 20, 007. Alter, PersNr. Name, Alter, Gehalt ...")
118
Eine andere Möglichkeit: Referenzierung über Speicheradressen
Alter PersNr 20,... 007,... 007, Bond, 20, ...

119
„Beste“ Zugriffsmethode
Beobachtung: „Beste“ Methode hängt vom Anwendungsfall ab.

120
Anwendungsfall Select Name From Professoren Where PersNr = 2136
Where Gehalt >= and Gehalt <=

121
„Beste“ Methode Die wichtigsten Zugriffsmethoden:
Heap File (ungeordnet bzw. kein "passender" Index) sortierte Datei geballter Index nicht geballter Index Die wichtigsten Anwendungsfälle: Durchlaufen des gesamten File (scan) Punktanfrage (exact match) Bereichsanfrage (range selection) Einfügen (insert) Löschen (delete)
 sortierte Datei. geballter Index. nicht geballter Index. Die wichtigsten Anwendungsfälle: Durchlaufen des gesamten File (scan) Punktanfrage (exact match) Bereichsanfrage (range selection) Einfügen (insert) Löschen (delete)")
122
„Beste“ Methode "Beste" Methode hängt vom Anwendungsfall ab, d.h.: Es gibt keine Methode, die immer besser ist als die anderen, z.B.: Bei Punktanfragen ist Hash-Index im allgemeinen etwas schneller als ein B+-Baum. Bei Bereichsanfragen ist Hash-Index wesentlich schlechter als ein B+-Baum. Bei einer Bereichsanfrage mit vielen Treffern wird auch ein nicht geballter B+-Baum schlechter (wegen Random I/O). Beim Einfügen ist ein ungeordnetes File am schnellsten. Gutes Verhalten "in allen Lebenslagen": B+-Baum
. Beim Einfügen ist ein ungeordnetes File am schnellsten. Gutes Verhalten in allen Lebenslagen : B+-Baum.")
123
Indexe in SQL Create index SemsterInd on Studenten (Semester)
drop index SemsterInd Indexe sind nicht Teil des SQL-99 Standards. Aber im allgemeinen kann man sogar auch noch die Zugrffsmethode angeben, e.g.: Create Index <index-name> With structure = BTree On Studenten (Name, Semester);
;")
Ähnliche Präsentationen








>")






>")


>")


>")

>")
