Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Berlin-Brandenburgische Akademie der Wissenschaften
Wolfenbüttel, Das Projekt DWDS: Auf dem Wege zu einem Digitalen Wörterbuch der deutschen Sprache des 20./21. Jahrhunderts – Alexander Geyken – Berlin-Brandenburgische Akademie der Wissenschaften

2
Motivation ein gutes Wörterbuch sollte auf Corpusdaten basieren oder diese zumindest substanziell miteinbeziehen

3
Motivation Es gibt kein befriedigendes Wörterbuch der deutschen Sprache des 20./21. Jahrhunderts. Gründe (vgl. Hartmut Schmidt (1994,1995)): fehlende ‚balancierte‘ Textcorpora zu stark einzelwortbezogene Darstellung unzureichende Darstellung der deutschen Sprache in Österreich und der Schweiz Deutschland liegt hinter England und Frankreich zurück ein gutes Wörterbuch sollte auf Corpusdaten basieren oder diese zumindest substanziell miteinbeziehen

4
Vorbereitungsphase Arbeitsgruppe: M. Bierwisch, W. Klein, H. Schmidt, D. Simon, A. Geyken Kuratorium: Enzensberger, Frühwald, Honnefelder, Lepennies, Rau, Weizsäcker, Zimmer Erstellung einer Machbarkeitsstudie für ein elektronisches Corpus; Beantragung eines DFG-Projekts

5
Ziele des DWDS DWDS: Erstellung eines ausgewogenen Corpus des 20./21. Jh. [Einschub – Wozu ein Korpus] DWDS: beschreibt nicht nur das Einzelwort, sondern das Wort in seinem Gebrauch (=> auf der Basis eines großen und ausgewogenen Corpus) DWDS: breite Nutzungsmöglichkeiten => On-line Plattform: akademische Basis für Sprachbeschreibung und Sprachvermittlung DWDS: Nutzung computerlexikographischer Methoden
![Ziele des DWDS DWDS: Erstellung eines ausgewogenen Corpus des 20./21. Jh. [Einschub – Wozu ein Korpus]](http://slideplayer.org/slide/1314394/3/images/5/Ziele+des+DWDS+DWDS%3A+Erstellung+eines+ausgewogenen+Corpus+des+20.%2F21.+Jh.+%5BEinschub+%E2%80%93+Wozu+ein+Korpus%5D.jpg "DWDS: beschreibt nicht nur das Einzelwort, sondern das Wort in seinem Gebrauch (=> auf der Basis eines großen und ausgewogenen Corpus) DWDS: breite Nutzungsmöglichkeiten => On-line Plattform: akademische Basis für Sprachbeschreibung und Sprachvermittlung. DWDS: Nutzung computerlexikographischer Methoden.")
6
Einschub – Warum Corpora …

7
Einschub – Warum Corpora …

8
Einschub – Warum Corpora …

9
Einschub – Warum Corpora …

10
Projektphasen Vorbereitungsphase (11/ /2000) Erstellung der Textgrundlage (20. Jh.) (03/ /2004 -> DFG-Projekt) Erstellung der Textgrundlage ( Jh.) -> DFG Projekt Deutsches Textarchiv Computerlinguistische Erschließung der Wörterbuchgrundlage (seit 10/2002)
 -> DFG Projekt Deutsches Textarchiv. Computerlinguistische Erschließung der Wörterbuchgrundlage (seit 10/2002)")
11
Vorgehensweise Wie läßt sich die Wörterbucherstellung in einem zeitlich und finanziell planbaren Maß gestalten? => ‚breadth first‘-Strategie bei allen Projektetappen. ‚Industrielle‘ Digitalisierung der Texte modulare Erstellung des Wörterbuchs effiziente informatische Unterstützung des Bearbeitungsprozesses: Textfiltermethoden

12
Das Projekt DWDS: Stand
Gliederung Einleitung Das Projekt DWDS: Stand 2.1 Corpuserstellung 2.2 Webpräsenz 2.3 Anwendung Sprachbeobachtung Ausblick: Schritte zu einem Digitalen Wörterbuch opportunistisch, d.h. aber nicht „wahllos“, weil dennoch referenzierbar und „repräsentativ“, d.h. beispielsweise BILD, FAZ, NZZ, SPIEGEL, SZ, ZEIT, aber auch Konkret, TAZ, Computerwoche...

13
(2.1) Corpuserstellung: Vorgehensweise
Textauswahl und Copyrightvereinbarung Digitalisierung XML-Konvertierung Qualitätskontrolle

14
Ausgewogenheit der Textauswahl
Belletristik (27%) Journalistische Prosa (26%) Wissenschaftliche Fachtexte (21%) Gebrauchsliteratur (21%) Transkriptionen gesprochener Sprache (5%)
 Journalistische Prosa (26%) Wissenschaftliche Fachtexte (21%) Gebrauchsliteratur (21%) Transkriptionen gesprochener Sprache (5%)")
15
Textauswahl Textauswahl wird vorgenommen von: Akademiemitgliedern der BBAW, Schriftstellern (Belletristik) Akademiemitgliedern (Wissenschaft und Journalistische Prosa) Arbeitsgruppe (Gebrauchstexte, Gesprochene Sprache)
 Arbeitsgruppe (Gebrauchstexte, Gesprochene Sprache)")
16
Literatur über 300 Monographien

17
Zeitungen Stichproben aus 150 Zeitungen

18
Wissenschaft wir haben insgesamt ca. 125 Werke (über China und OCR, nicht CD) über Dokumente, d.h. Monographien und sehr lange Aufsätze aus der Wissenschaft mit zusammen ca. 12 Mio Wörtern. Beinahe alle sind im Kerncorpus, Rechte haben wir maximal für ein Viertel der Menge und wir ersetzen sie durch CD-Material.
 über Dokumente, d.h. Monographien und sehr lange Aufsätze aus der. Wissenschaft mit zusammen ca. 12 Mio Wörtern. Beinahe alle sind im Kerncorpus, Rechte haben wir maximal für ein Viertel der Menge und wir. ersetzen sie durch CD-Material.")
19
Werbung

20
Werbung

21
Flugblätter

22
Gebrauchsliteratur

23
Gebrauchsliteratur

24
Beispiele: Belletristik – 20er Jahre
Grimm, Hans, Volk ohne Raum, München: Albert Langen 1926 Hesse, Hermann, Der Steppenwolf, Berlin: S. Fischer 1927 Kafka, Franz, Der Process, [1925] Luckner, Felix Graf, Seeteufel, Leipzig: Köhler 1921 LeFort, Gertrud von, Schweißtuch der Veronika, München: Kösel & Pustet 1928 Salten, Felix, Bambi: Eine Lebensgeschichte aus dem Walde, Berlin: Zsolnay 1926 Winkler, Josef, Der tolle Bomberg: Ein westfälischer Schelmenroman, Stuttgart u.a.: Dt. Verl. Anstalt 1923

25
Beispiele: Belletristik – 80er Jahre
Merian, Svende, Der Tod des Märchenprinzen, Hamburg: Buntbuch Verlag 1980 Ransmayr, Christoph, Die letzte Welt, Nördlingen: Greno 1988 Strittmatter, Erwin, Der Laden, Berlin: Aufbau 1983 Bieler, Manfred, Der Bär, Hamburg: Hoffmann & Campe 1983 Loest, Erich, Völkerschlachtdenkmal, Hamburg: Hoffmann & Campe 1984 Nadolny, Sten, Die Entdeckung der Langsamkeit, München: Piper 1983 Pausewang, Gudrun, Die Wolke, Ravensburg: Maier 1987

26
RBB - Textquellen

27
Copyrightvereinbarungen
Verlage (Aufbau Verlagsgruppe, Diogenes, DirectMedia, Eichborn, Fischer Verlags-gruppe, Hoffmann & Campe, Kiepenheuer & Witsch, Saur, Spiegel, Suhrkamp, Ullstein-Heyne-List-Econ, ZEIT, Zsolnay) Autoren: u.a. Böll, Dürrenmatt, Habermas, Hesse, G. Hauptmann, Klemperer, K. Kraus, S. Lenz, Th. und H. Mann, Moers, Perutz, Seghers, Süskind, Walser
 Autoren: u.a. Böll, Dürrenmatt, Habermas, Hesse, G. Hauptmann, Klemperer, K. Kraus, S. Lenz, Th. und H. Mann, Moers, Perutz, Seghers, Süskind, Walser.")
28
Copyrightvereinbarungen
DWDS verwendet die Werke bzw. Extrakte auf seiner on-line Plattform Einschränkungen: das Werk darf nicht rekonstruierbar sein nur Auszüge aus dem Werk im Corpus: reicht von 5% bis 75% kleine Belegkontexte: Je nach Vereinbarung: Paragraph oder 3 Sätze oder 1 Satz oder +/- 3 Wörter keine kommerzielle Nutzung

29
Kontextgröße Beispiel

30
Textakquise (1) Textgeber (60% des Kerncorpus): Verlage (s. oben) Bibliotheken (Staatsbibliothek Berlin) Archive (Deutsches Rundfunkarchiv)
")
31
Textakquise (2) Eigendigitalisierung (40%) Manuelle Transkription von Zeitungsartikel ( ), 250 Monographien (Fraktur). Transkription: Grepect GmbH (Peking) Metatagging (Autor, Titel, Seitenumbruch etc.): bis zu 15 studentische MitarbeiterInnen in Berlin
. Transkription: Grepect GmbH (Peking) Metatagging (Autor, Titel, Seitenumbruch etc.): bis zu 15 studentische MitarbeiterInnen in Berlin.")
32
Corpuserstellung: Vorgehensweise
Textauswahl und Copyrightvereinbarung Digitalisierung Qualitätskontrolle Integrierter Workflow und Dokumentenmanagement-System

33
Einschub: OCR oder Abtippen
Abtippen: bei nicht serieller Fraktur und schlecht erhaltenen Antiqua-Vorlagen Double oder Triple-keying Genauigkeiten von 99,95%. OCR: bei serieller und wenig strukturierter Fraktur und gut erhaltenen Antiqua-Vorlagen

34
Berliner Tageblatt vom 18.2.1902

35
Geclippter Artikel und Datenblatt
Clipping Abtippen / OCR Konvertierung XML/TEI Linguistische Annotierung <a>Block, Paul</a> <t>Das Drama von Springe</t> <st>Ein Rückblick auf den Prozeß Falkenhagen</st> <pubdata> </pubdata> <journal>Berliner Tageblatt</journal> <page>1-2</page>

36
Text nach Abtippen in China: XML „light“
<a>Block, Paul</a> <t><b>Das Drama von Springe.</b></t> <st><b>Ein Rückblick auf den Prozeß Falkenhagen.</b></st> <p><b>Hannover,</b> 17. Februar.</p> <p>Es ist eigentlich kein Drama, es ist nur ein bürgerliches Trauer-<lbr/> spiel. Der höhere Konflikt fehlt. Leichtfertigkeit und konventionelle<lbr/> Form weben die tödtliche Schlinge, in der ein wackerer Mann zu<lbr/> Grunde geht. Zwei ehrenwerthe Familien begraben ihre Hoffnungen<lbr/> und einen Theil ihres Glücks …</p> <p>Man hat gestern mit der Höflichkeit, die uns Frauen gegenüber<lbr/> einmal eigen ist, alles Mögliche aufgeboten, um der Frau Land-<lbr/> räthin das Peinliche der Situation zu ersparen. Als sie beim Zeugen-<lbr/> aufruf erschien, schwarz gekleidet und verschleiert, saben Alle<lbr/> [...] <PB NS=2>neugierig nach ihr hin. </p> <p>Ein schlechtes Drama! Das Leben schreibt dumme Theaterstücke!</p> Clipping Abtippen / OCR Konvertierung XML/TEI Linguistische Annotierung

37
Konvertierung nach TEI: (1) Die Metadaten
<teiHeader><fileDesc><publicationStmt> <publisher id="DWDS-Corpus-Publisher">BBAW - AG Digitales Wörterbuch</publisher> <availability n=„OR3S" status="restricted"></availability> </publicationStmt> <sourceDesc><biblFull><titleStmt> <title level="a" type="main">Das Drama von Springe.</title> <title level="a" type="sub">Ein Rückblick auf den Prozeß Falkenhagen.</title> <author>Block, Paul</author></titleStmt> <publicationStmt> <publisher id="Rechtsinhaber">Rudolf Mosse</publisher> <pubPlace>Berlin</pubPlace> <date> </date> <seriesStmt><title level="j">Berliner Tageblatt</title> <idno type="Seite">1</idno></seriesStmt> </biblFull></sourceDesc></fileDesc>... <profileDesc><textClass><keywords> <term n="1">Zeitung</term> </keywords></textClass></profileDesc></teiHeader> Clipping Abtippen / OCR Konvertierung XML/TEI Linguistische Annotierung

38
Konvertierung nach TEI: (2) Der Text
<text TEIform="text"> <body TEIform="body"> <p TEIform="p"> <hi type="b" TEIform="hi">Hannover,</hi> 17. Februar. </p> <p>Es ist eigentlich kein Drama, es ist nur ein bürgerliches Trauer- <lbr/> spiel. Der höhere Konflikt fehlt. Leichtfertigkeit und konventionelle <lbr/> Form weben die tödtliche Schlinge, in der ein wackerer Mann zu <lbr/> Grunde geht. Zwei ehrenwerthe Familien begraben ihre Hoffnungen <lbr/> und einen Theil ihres Glücks …</p> <p>Man hat gestern mit der Höflichkeit, die uns Frauen gegenüber <lbr/> einmal eigen ist, alles Mögliche aufgeboten, um der Frau Land- <lbr/> räthin das Peinliche der Situation zu ersparen. Als sie beim Zeugen- <lbr/> aufruf erschien, schwarz gekleidet und verschleiert, saben Alle [...] <lbr/> <PB NS=2>neugierig nach ihr hin. </p> [...] <p>Ein schlechtes Drama! Das Leben schreibt dumme Theaterstücke!</p> </body> </text> Clipping Abtippen / OCR Konvertierung XML/TEI Linguistische Annotierung

39
Bedingter Trennstrich oder Bindestrich?
Problemfälle der OCR/Abtippen – Beispiel 1 Clipping Abtippen / OCR Konvertierung XML/TEI Linguistische Annotierung Es ist eigentlich kein Drama, es ist nur ein bürgerliches Trauer- spiel. Der höhere Konflikt fehlt. Leichtfertigkeit und konventionelle Bedingter Trennstrich oder Bindestrich?

40
Worttrennungen am Zeilenende
Kodierung in TEI: <w> <wform>Trauerspiel</wform> <seg>Trauer-</seg><lbr/> <seg>spiel</seg> </w> Linguistische Annotierung: <w t="trauer#spiel" cs="n#n" c="noun"> Trauerspiel</w> Clipping Abtippen / OCR Konvertierung XML/TEI Linguistische Annotierung

41
Worttrennungen am Zeilenende
Kodierung in TEI: <w> <wform>Trauerspiel</wform> <seg>Trauer-</seg><lbr/> <seg>spiel</seg> </w> Linguistische Annotierung: <w t="trauer#spiel" cs="n#n" c="noun"> Trauerspiel</w> => Bedingter Trennstrich: Wortbestandteile werden zusammengezogen Clipping Abtippen / OCR Konvertierung XML/TEI Linguistische Annotierung

42
Worttrennungen am Zeilenende
Kodierung in TEI: <w> <wform>Trauerspiel</wform> <seg>Trauer-</seg><lbr/> <seg>spiel</seg> </w> Linguistische Annotierung: <w t="trauer#spiel" cs="n#n" c="noun"> Trauerspiel</w> => Bindestrich und Zeilenumbruch werden durch bedingten Trennstrich ersetzt Clipping Abtippen / OCR Konvertierung XML/TEI Linguistische Annotierung

43
Bedingter Trennstrich oder Bindestrich?
Problemfälle der OCR/Abtippen – Beispiel 2 Clipping Abtippen / OCR Konvertierung XML/TEI Linguistische Annotierung Sondern ist Weingutsbesitzer und Wein- und Kognakhändler. Seine Kognakmarke ... Bedingter Trennstrich oder Bindestrich? => Lemma: Weinhändler und nicht Weinund!

44
Worttrennungen am Zeilenende
Kodierung in TEI: <w> <wform>Weinund</wform> <seg>Wein-</seg><lbr/> <seg>und</seg> </w> Linguistische Annotierung: <w state="unknown" errC="001"> Weinund</w> Clipping Abtippen / OCR Konvertierung XML/TEI Linguistische Annotierung

45
Worttrennungen am Zeilenende
Kodierung in TEI: <w> <wform>Weinund</wform> <seg>Wein-</seg><lbr/> <seg>und</seg> </w> Linguistische Annotierung: <w state="unknown" errC="001"> Weinund</w> => Wortbestandteile bleiben erhalten Clipping Abtippen / OCR Konvertierung XML/TEI Linguistische Annotierung

46
Worttrennungen am Zeilenende
Kodierung in TEI: <w> <wform>Weinund</wform> <seg>Wein-</seg><lbr/> <seg>und</seg> </w> Linguistische Annotierung: <w state="unknown" errC="001"> Weinund</w> => Wortbestandteile bleiben erhalten => Zeilenumbruch wird durch 'Leerzeichen' ersetzt Clipping Abtippen / OCR Konvertierung XML/TEI Linguistische Annotierung

47
Linguistische Annotierung
Unbekannte Wörter werden identifiziert und annotiert: Clipping Abtippen / OCR Konvertierung XML/TEI Linguistische Annotierung <w n="6" c="w.art">die</w> <w n="7" state="unknown" errC="001">tödtliche</w> <w n="8" nb="sg" g="f" s=„artef" c="noun">Schlinge</w>

48
Ergebnis nach der linguistischen Aufbereitung
<text TEIform="text"> <body TEIform="body"> <p TEIform="p"> <hi type="b" TEIform="hi">Hannover,</hi> 17. Februar. </p> <p>Es ist eigentlich kein Drama, es ist nur ein bürgerliches Trauer- spiel. Der höhere Konflikt fehlt. Leichtfertigkeit und konventionelle Form weben die tödtliche Schlinge, in der ein wackerer Mann zu Grunde geht. Zwei ehrenwerthe Familien begraben ihre Hoffnungen und einen Theil ihres Glücks …</p> <p>Man hat gestern mit der Höflichkeit, die uns Frauen gegenüber einmal eigen ist, alles Mögliche aufgeboten, um der Frau Land- räthin das Peinliche der Situation zu ersparen. Als sie beim Zeugen- aufruf erschien, schwarz gekleidet und verschleiert, saben Alle [...] <PB NS=2>neugierig nach ihr hin. </p> [...] <p>Ein schlechtes Drama! Das Leben schreibt dumme Theaterstücke!</p> </body> </text> Clipping Abtippen / OCR Konvertierung XML/TEI Linguistische Annotierung

49
Ergebnis nach der linguistischen Aufbereitung
<text TEIform="text"> <body TEIform="body"> <p TEIform="p"> <hi type="b" TEIform="hi">Hannover,</hi> 17. Februar. </p> <p>Es ist eigentlich kein Drama, es ist nur ein bürgerliches Trauer- spiel. Der höhere Konflikt fehlt. Leichtfertigkeit und konventionelle Form weben die <w errC=„001" state=„unknown"> tödtliche </w> Schlinge, in der ein wackerer Mann zu Grunde geht. Zwei ehrenwerthe Familien begraben ihre Hoffnungen und einen Theil ihres Glücks …</p> <p>Man hat gestern mit der Höflichkeit, die uns Frauen gegenüber einmal eigen ist, alles Mögliche aufgeboten, um der Frau Land- räthin das Peinliche der Situation zu ersparen. Als sie beim Zeugen- aufruf erschien, schwarz gekleidet und verschleiert, saben Alle [...] <PB NS=2>neugierig nach ihr hin. </p> [...] <p>Ein schlechtes Drama! Das Leben schreibt dumme Theaterstücke!</p> </body> </text> Clipping Abtippen / OCR Konvertierung XML/TEI Linguistische Annotierung => Annotierung unbekannter Wörter

50
Problemfälle OCR/Abtippen
Grenzen der automatischen Analyse: Falsche Analysen sind im Nachhinein nur noch mühsam „per Kopf“ zu erkennen Preis#geh#krön#teen (statt Preisgekrönten) Weit|geh#hände (statt Weitgehende) Hoch#bedeut#hände (statt Hochbedeutende) Zeit#raub#hände (statt Zeitraubende) Zeichen#orient#hirt (statt zeichenorientiert) Lebens#orient#hirte (statt Lebensorientierte) Clipping Abtippen / OCR Konvertierung XML/TEI Linguistische Annotierung
 Weit|geh#hände (statt Weitgehende) Hoch#bedeut#hände (statt Hochbedeutende) Zeit#raub#hände (statt Zeitraubende) Zeichen#orient#hirt (statt zeichenorientiert) Lebens#orient#hirte (statt Lebensorientierte) Clipping Abtippen / OCR Konvertierung. XML/TEI Linguistische. Annotierung.")
51
Corpuserstellung: Vorgehensweise
Textauswahl Digitalisierung Qualitätskontrolle Integrierter Workflow und Dokumentenmanagement-System

52
Qualitätskontrolle Nach der linguistischen Analyse verbleiben mehrere Prüffälle (d.h. für das linguistische Analysewerkzeug unbekannte Wörter) Quasi-“Industrielle“ Vorgehensweise: 30 Mio Textwörter = Zeitungsartikel, ca. 200 Monographien; Neben der Firma in China 2 Mitarbeiter und ca. 12 Studentische Hilfskräfte; neben der Korrektur ist aber auch die Frage nach lexikalisch interessantem Material. Es verbleiben nach dem Abtippen mehrere Wörter, die von der linguistischen Analyse nicht erkannt wurden. Wie klassifiziert und korrigiert man dieses Material am effektivsten?
 Quasi- Industrielle Vorgehensweise: 30 Mio Textwörter = Zeitungsartikel, ca. 200 Monographien; Neben der Firma in China 2 Mitarbeiter und ca. 12 Studentische Hilfskräfte; neben der Korrektur ist aber auch die Frage nach lexikalisch interessantem Material. Es verbleiben nach dem Abtippen mehrere Wörter, die von der linguistischen Analyse nicht erkannt wurden. Wie klassifiziert und korrigiert man dieses Material am effektivsten")
53
Prüffälle: Klassifizierung einer Stichprobe
Digitalisierungsfehler (saben statt sahen) Namen bzw. Ableitungen: Geographie: Abessinien, japanesisch Familiennamen: Moltke, vossische Veraltete Abkürzungen und Akronyme (lebh . Beif. rechts u. im Zentr.) Historische Rechtschreibung (diktirt, That) lexikographisch interessantes Material (Antichambrist, branchekundig statt heutzutage branchenkundig)
 Namen bzw. Ableitungen: Geographie: Abessinien, japanesisch. Familiennamen: Moltke, vossische. Veraltete Abkürzungen und Akronyme (lebh . Beif. rechts u. im Zentr.) Historische Rechtschreibung (diktirt, That) lexikographisch interessantes Material (Antichambrist, branchekundig statt heutzutage branchenkundig)")
54
Ergebnis: DWDS-Corpus
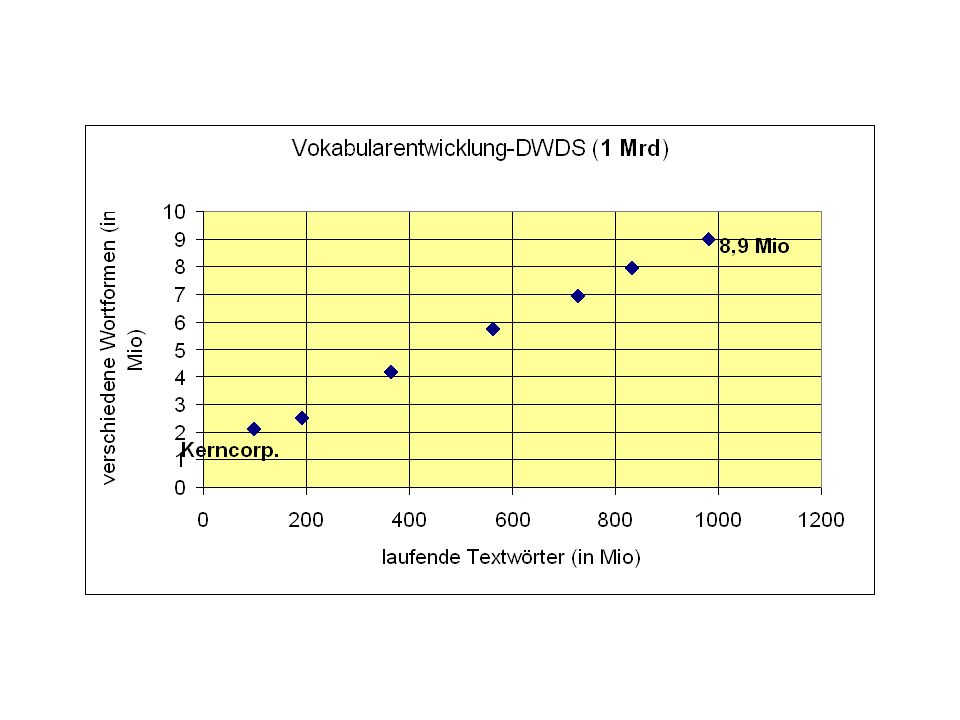
Kerncorpus: Größe: 100 Millionen Textwörter - ausgewogen rechtlich abgesichert XML/TEI Format linguistisch voranalysiert Ergänzungscorpus: Größe: 1 Milliarde Textwörter

55
Automatische linguistische Analyse
Lemmatisierung: Ärzte, Arztes -> Arzt Disambiguierung von Wortarten: (1) Er tritt vor die Tür vs. das kommt vor Präposition Verbpartikel (2) Der Strauß Blumen vs. Richard Strauß Nomen Eigenname Automatische Analyse durch einen Part-of-Speech Tagger (s. Quasi-“Industrielle“ Vorgehensweise: 30 Mio Textwörter = Zeitungsartikel, ca. 200 Monographien; Neben der Firma in China 2 Mitarbeiter und ca. 12 Studentische Hilfskräfte; neben der Korrektur ist aber auch die Frage nach lexikalisch interessantem Material. Es verbleiben nach dem Abtippen mehrere Wörter, die von der linguistischen Analyse nicht erkannt wurden. Wie klassifiziert und korrigiert man dieses Material am effektivsten?
 Er tritt vor die Tür vs. das kommt vor. Präposition Verbpartikel. (2) Der Strauß Blumen vs. Richard Strauß. Nomen Eigenname. Automatische Analyse durch einen Part-of-Speech Tagger (s. Quasi- Industrielle Vorgehensweise: 30 Mio Textwörter = Zeitungsartikel, ca. 200 Monographien; Neben der Firma in China 2 Mitarbeiter und ca. 12 Studentische Hilfskräfte; neben der Korrektur ist aber auch die Frage nach lexikalisch interessantem Material. Es verbleiben nach dem Abtippen mehrere Wörter, die von der linguistischen Analyse nicht erkannt wurden. Wie klassifiziert und korrigiert man dieses Material am effektivsten")
56
Exkurs: Corpora und Größe
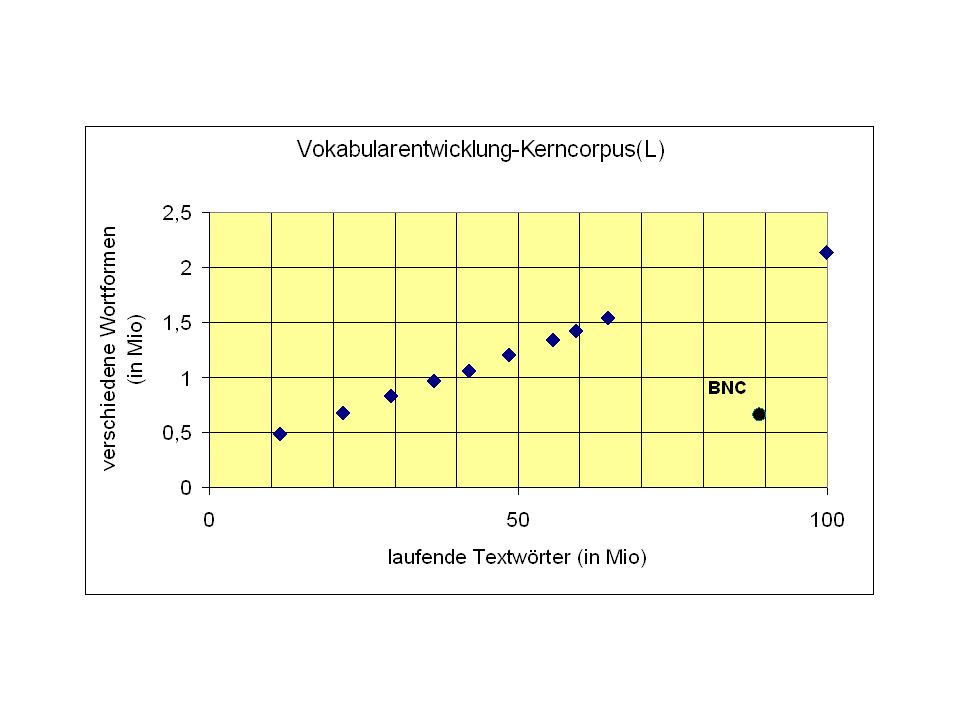
Corpus Textwörter verschiedene Wörter Dürrenmatt (Verdacht) 33.888 6.201 Brown (US, 1969) 1 Million 50.406 Limas (D, 1973) 98.138 British Nat. Corp. (1993) 100 Mio. DWDS-Kerncorpus (2003) 2,1 Millionen DWDS-Ergänzungscorpus (2003) 1 Mrd. ? der Augenblick Hungertobel undurchdringlich=1 undurchdringliche=1 undurchdringlichen=1 unverbesserlich=1
 Brown (US, 1969) 1 Million Limas (D, 1973) British Nat. Corp. (1993) 100 Mio DWDS-Kerncorpus (2003) 2,1 Millionen. DWDS-Ergänzungscorpus (2003) 1 Mrd. der. Augenblick. Hungertobel. undurchdringlich=1. undurchdringliche=1. undurchdringlichen=1. unverbesserlich=1.")
57
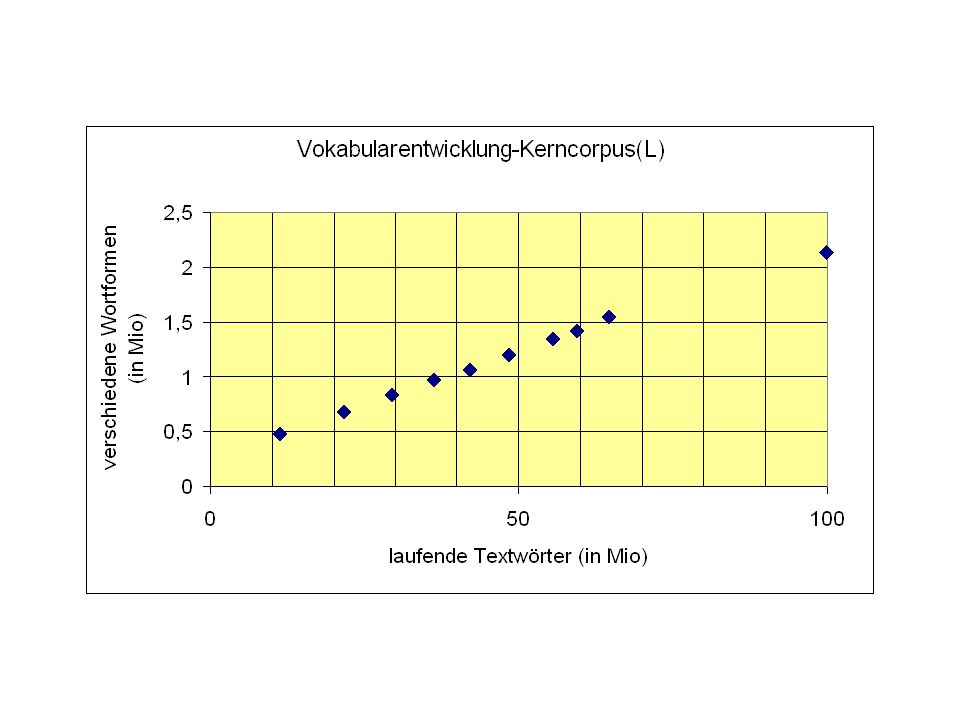
Experiment British National Corpus (100 Mio): hinreichend groß? Unbekannt ist: Wie wächst das Vokabular bei wachsender Corpusgröße [ab 100 Mio]? Konvergiert die Menge der verschiedenen Wortformen bei genügend großer Corpusmenge? [Besonderheit des Deutschen: Komposition]
![Experiment British National Corpus (100 Mio): hinreichend groß Unbekannt ist: Wie wächst das Vokabular bei wachsender Corpusgröße [ab 100 Mio]](http://slideplayer.org/slide/1314394/3/images/57/Experiment+British+National+Corpus+%28100+Mio%29%3A+hinreichend+gro%C3%9F+Unbekannt+ist%3A+Wie+w%C3%A4chst+das+Vokabular+bei+wachsender+Corpusgr%C3%B6%C3%9Fe+%5Bab+100+Mio%5D.jpg "Konvergiert die Menge der verschiedenen Wortformen bei genügend großer Corpusmenge [Besonderheit des Deutschen: Komposition]")
62
Aufarbeitung des Corpus
Produktive Wortbildung im Deutschen: lange Komposita: z.B. Frühlingsanfangsschokoladenhohlkörper Einsatz von automatischen Verfahren zur Wortzerlegung: Das Programm TAGH (s. Grundidee: verschiedene Wortformen werden auf ihre Grundformen reduziert. So zählen Haus, Häuser, Hauses beispielsweise zur gleichen Grundform, nämlich Haus. Durch Abgleich der Zerlegungen mit den Wörterbüchern lassen sich neue Wortformen identifizieren.

63
AutomatischeWortzerlegung
Die korrekte Zerlegung von abgeleiteten oder zusammengesetzten Wortformen spielt dabei eine sehr große Rolle. Dadurch können beispielsweise die Selbstbauanlage, Selbstbauanleitung den Bestandteilen Selbstbau, Anlage bzw. Anleitung zugeordnet werden. Umgekehrt würden falsche Zerlegungen zu einem „falschen Alarm“ führen. In solchen Fällen würde das Verfahren fälschlicherweise neue Wörter vorschlagen: Gendarm sollte ein Einzelwort bleiben und nicht in Gen und Darm zerlegt werden. Telekommunikation sollte am besten gar nicht oder als Tele+kommunikation analysiert werden, keinesfalls jedoch als Tele+komm+unikat+ion, noch in Tele+komm+uni+kation und auch nicht in Telekom+muni+kation (Muni = schweiz. der Zuchtstier)
")
66
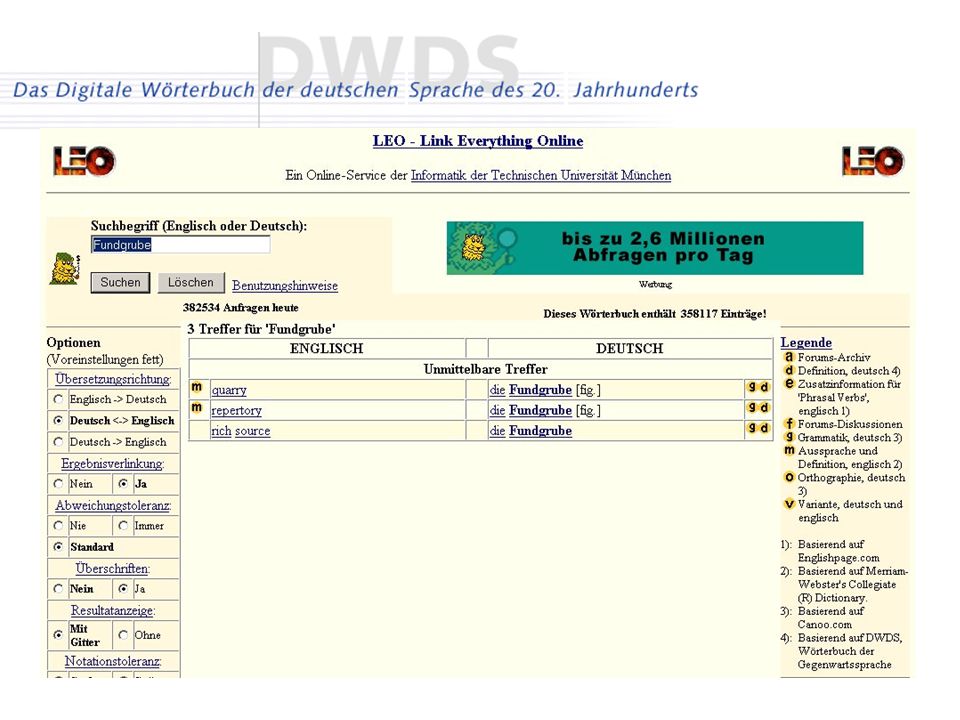
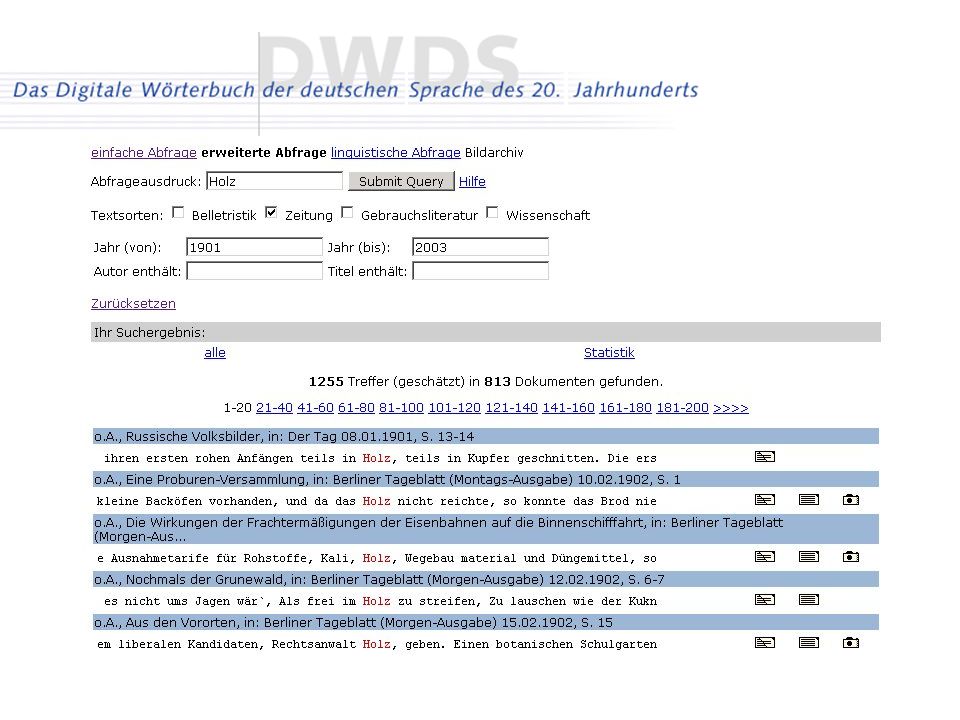
(2.2) Webpräsenz – www.dwds.de
Wörterbuchabfrage: Wörterbuch der deutschen Gegenwartssprache (WDG, ) Corpora: DWDS-Kerncorpus, ZEIT (wochenaktuell), Tagesspiegel (ab Okt. 2005) Wortinformationssystem: WDG und Corpus Automatisch generierte Informationen: Synonyme, Ober- und Unterbegriffe Kollokationen
 Corpora: DWDS-Kerncorpus, ZEIT (wochenaktuell), Tagesspiegel (ab Okt. 2005) Wortinformationssystem: WDG und Corpus. Automatisch generierte Informationen: Synonyme, Ober- und Unterbegriffe. Kollokationen.")
67
Maske - Wortinformation

68
WDG-Artikel

69
Quellenverzeichnis

70
Stichwörter von Thälmann

71
Stichwort: Schlotbaron

72
Wortinfo – Syn etc.

73
Corpus,1

74
Corpus,2

75
Corpus,3

76
Corpus,4

77
Kollok , 1

78
Kollok, 2

79
Weitere Web-Anwendungen
Verknüpfung Beleg – Wörterbuch Vernetzung Wörterbuch mit anderen on-line Angeboten Verknüpfung Beleg – Bild – Volltext Wörterbuch der deutschen Gegenwartssprache WDG: größte frei zugängliche gegenwartssprachliche deutsche Wörterbuch WDG: Kernbestandteil des zukünftigen digitalen Wörterbuchsystems.

80
ii) on-line Plattform - Vernetzung
ZEIT-online Wörterbuchportal dict.leo.org (größtes deutsch-englisches on-line Wörterbuch) uni-deutsch (BMBF, DAAD) etwa Seitenaufrufe (p.i.) täglich Ergebnisse im Internet sichtbar: Das DWDS ist das „kleine D“ bei leo.org ca. alle halbe Minute nimmt eine virt. Person ein Wort nach
 uni-deutsch (BMBF, DAAD) etwa Seitenaufrufe (p.i.) täglich. Ergebnisse im Internet sichtbar: Das DWDS ist das „kleine D bei leo.org. ca. alle halbe Minute nimmt eine virt. Person ein Wort nach.")
83
iii) Verknüpfung Beleg - Volltext - Bild
Basis: etwa Zeitungsartikel (Berliner Tageblatt, Vossische Zeitung, Die ZEIT). Berücksichtigung des Copyrightstatus bei der Kontextanzeige Wenn Rechte am Volltext oder Bild vorhanden => interne Verknüpfung Wenn keine Rechte vorhanden => externe Verknüpfung
. Berücksichtigung des Copyrightstatus bei der Kontextanzeige. Wenn Rechte am Volltext oder Bild vorhanden => interne Verknüpfung. Wenn keine Rechte vorhanden => externe Verknüpfung.")
92
(C) Fortlaufende Sprachbeobachtung
„Eigentlich hätte uns das Wort nicht durch die Lappen gehen dürfen“, gesteht Beate Varnhorn, Chefredakteurin von Wahrig, der Wörterbuchmarke bei Bertelsmann. Doch immer wieder ist das Wort „Ceranfeld“ Sprachbeobachtern durchgerutscht.... Nun bekommen die [Wörterbuchmacher] Unterstützung von Computerlinguisten. Deren Programme sollen Texte schneller nach neuen Wörtern durchsuchen und dabei weniger Fehler machen.” (Süddeutsche Zeitung, )
")
93
(C) Fortlaufende Sprachbeobachtung
Möglichkeiten (Beispiele): empirische Ermittlung der Entwicklung von ´s (Helga´s Hundesalon, Kant´s Schriften) empirische Ermittlung der Entwicklung von Anglizismen Korrektiv für Wörterbücher Erweiterung von Wörterbüchern Vorzüge des elektronischen Mediums: der unbegrenzte Platz; der Gebrauch von Wörtern im Kontext kann nachgezeichnet werden
: empirische Ermittlung der Entwicklung von ´s (Helga´s Hundesalon, Kant´s Schriften) empirische Ermittlung der Entwicklung von Anglizismen. Korrektiv für Wörterbücher. Erweiterung von Wörterbüchern. Vorzüge des elektronischen Mediums: der unbegrenzte Platz; der Gebrauch von Wörtern im Kontext kann nachgezeichnet werden.")
94
Beispiel 1: WDG Corpus: sternhagelbesoffen (0 Corpusbelege) sternhagelvoll (40) Beispiel 2: Grimm Neubearbeitung (1998) Corpus: Angstkauf (0) Angstkäufe (17)
 Angstkäufe (17)")
95
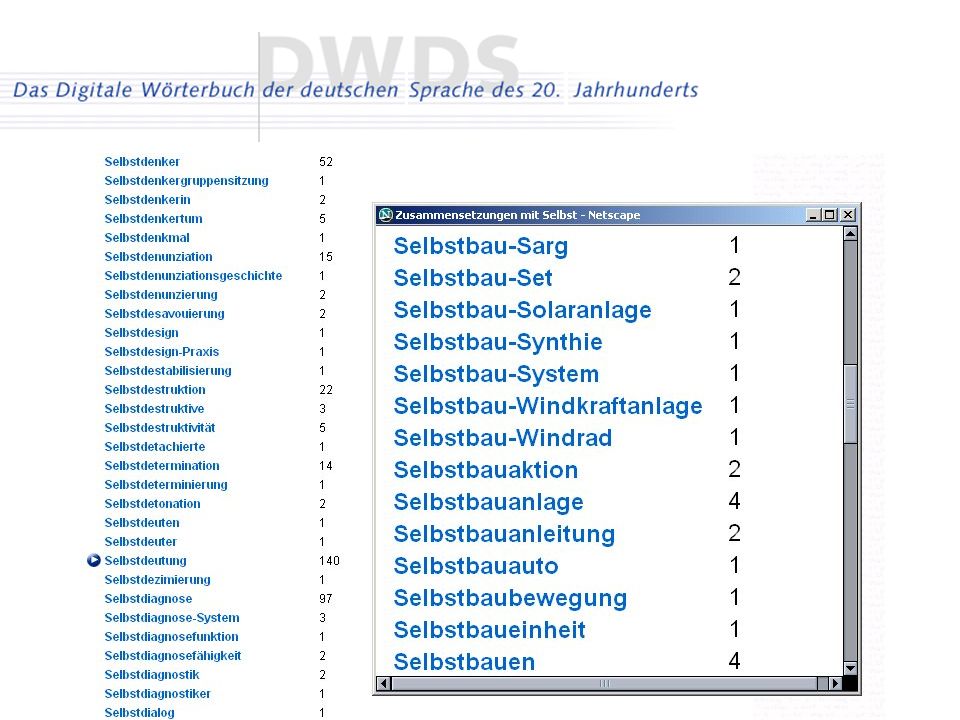
Beispiel 3: Duden (10-Bände, 2001) Stichwort: Selbst
Wörterbuch: 244 Einträge Selbstabholer ... Selbstbedienung ... Selbsterfahrung ... Selbstzweifel Corpus: 7884 verschiedene Wörter von Selbstabbau bis Selbstzündung Beispiel mit Selbstbau-Sarg ...

96
Nicht im Duden, aber im Corpus sehr häufig:
Selbstauskunft (185) Selbstmordanschlag (171) ... Selbstbedienungsmentalität (143) Selbstbau (105) Selbstbeschäftigung (105) Selbstgänger (91) Selbstnutzung (81) Selbstinteresse (80) Selbstähnlichkeit (77) Selbstlernen (30) Nicht im Duden, aber im Corpus sehr häufig: Selbstverpflichtung (2139 Mal) Selbstmordattentäter (801) Selbstregierung (727) Selbstregulierung (450) Selbstbeschreibung (380) Selbstbefragung (312) ...
 Selbstmordanschlag (171) ... Selbstbedienungsmentalität (143) Selbstbau (105) Selbstbeschäftigung (105) Selbstgänger (91) Selbstnutzung (81) Selbstinteresse (80) Selbstähnlichkeit (77) Selbstlernen (30) Nicht im Duden, aber im Corpus sehr häufig: Selbstverpflichtung (2139 Mal) Selbstmordattentäter (801) Selbstregierung (727) Selbstregulierung (450) Selbstbeschreibung (380) Selbstbefragung (312) ...")
97
Im Duden, aber nicht im Corpus:
Selbstabholerin Selbstanzeigerin Selbstbucherin Selbstentlader Selbsterzeugerin Selbstinserent Selbstladevorrichtung Selbstverstand Selbststellerin Selbstverlegerin Selbstverpflegerin

98
das stetige Anwachsen der Wortform gilt nicht nur für Eigennamen, sondern auch für die produktive Wortbildungsmuster.

100
Wortform(en): Selbstbau-Sarg Orig: o. A
Wortform(en): Selbstbau-Sarg Orig: o.A., Der Niedergang nach dem Abgang, in: Süddeutsche Zeitung , S. 13 Sargdiscounter, Sonderangebote, Selbstbau-Särge, vorsorgliche Hausbesuche bei potentiellen Kunden, Werbung bei Zielgruppen in Krankenhaus und Altenheim, Provisionsverträge mit Hausmeistern und Rettungsdienstpersonal – dies alles muß zugelassen werden. Datum: Seite: unknown Textsorte: Zeitung Feuilleton
: Selbstbau-Sarg Orig: o.A., Der Niedergang nach dem Abgang, in: Süddeutsche Zeitung , S. 13 Sargdiscounter, Sonderangebote, Selbstbau-Särge, vorsorgliche Hausbesuche bei potentiellen Kunden, Werbung bei Zielgruppen in Krankenhaus und Altenheim, Provisionsverträge mit Hausmeistern und Rettungsdienstpersonal – dies alles muß zugelassen werden. Datum: Seite: unknown Textsorte: Zeitung Feuilleton.")
101
Beispiel 4: rückläufige Wörterbücher
Mater (1967): etwa 100 verschiedene Substantive mit -kasten Farbkasten ... Baukasten, Steinbaukasten DWDS-Corpus: 1500 verschiedene Substantive mit –kasten insgesamt 177 Substantive auf -baukasten Baukasten, Modellbaukasten, Chemiebaukasten, Metallbaukasten, Stabilbaukasten, Steinbaukasten, Legobaukasten, Satzbaukasten (alle Frequenz > 10) ... Begriffsbaukasten
: etwa 100 verschiedene Substantive mit -kasten. Farbkasten ... Baukasten, Steinbaukasten. DWDS-Corpus: 1500 verschiedene Substantive mit –kasten. insgesamt 177 Substantive auf -baukasten. Baukasten, Modellbaukasten, Chemiebaukasten, Metallbaukasten, Stabilbaukasten, Steinbaukasten, Legobaukasten, Satzbaukasten (alle Frequenz > 10) ... Begriffsbaukasten.")
102
„Stolpe greift zielsicher in den Begriffsbaukasten.“
Geis, Matthias, Stolpe - die Krönung einer Kampagne, in: die tageszeitung - 12 ½ Jahre taz auf CD-ROM, Berlin: Contrapress-Media-GmbH 1999 [1992]

103
Beispiel 5: Zeitliche Veränderungen
NACHHALTIG, adj. und adv. auf längere zeit anhaltend und wirkend: nachhaltiger ertrag des bodens wird nur erzielt, wenn der boden in gutem stand erhalten wird. (DWB – Grimm) nachhaltig<Adj.>: 1. Sich auf längere Zeit stark auswirkend: einen –en Eindruck hinterlassen; etw. wirkt sich nachhaltig aus; jmdn. N. beeinflussen. 2. (Forstw.) die Nachhaltigkeit (2) betreffend, auf ihr beruhend: -e Forstwirtschaft (Duden 2001)
 nachhaltig<Adj.>: 1. Sich auf längere Zeit stark auswirkend: einen –en Eindruck hinterlassen; etw. wirkt sich nachhaltig aus; jmdn. N. beeinflussen. 2. (Forstw.) die Nachhaltigkeit (2) betreffend, auf ihr beruhend: -e Forstwirtschaft (Duden 2001)")
104
1. Wörterbücher: nachhaltig ohne Wertung
Im Corpus bis Ende der 30er Jahre nur neutrale und positive Wertung [des betroffenen Objekts]: Eindruck, Einfluß, Erfolg, Wirkung ab 1940 auch negative Wertung: z.B. Brände, Zerstörung, Zerstörungsangriffe, Straßenzerstörungen, Schäden, Verminung

105
2. Was ist alles nachhaltig?
: Wirkung, Eindruck, Erfolg, Einfluß, Besserung (5) : Weise, Druck, Abgabedruck, Genuß, Stärkung, ... (10) : Fleiß, Kraft, Bewirtschaftung, Widerstand, Spuren...(6) : Bedeutung, Unterstützung, Abhilfemaßnahmen (5) : Zerstörung, Zerstörungsangriffe, Straßenzerstörungen, Schäden, Brände, Abwehr, Sprengung, Verminung .. (12) : Interesse, Überwindung, Entspannung, Wirtschaftlichkeit, Verhinderung, Verbesserung, Störung (16) : Anstrengungen, Abbau, Impuls, Versuch ... (16) : Verkehrsstunden, Aufwertung, Anerkennung ... (20) : Abfuhr, Akzeptanzschub (72) : Entwicklung, Tourismus, Politik, Zukunft ... (> 100) interessant: nachhaltige Entwicklung ist am hochfrequentesten, aber erst seit 1995 im Corpus belegt. Ebenso ist nachhaltiger Tourismus seit
 : Weise, Druck, Abgabedruck, Genuß, Stärkung, ... (10) : Fleiß, Kraft, Bewirtschaftung, Widerstand, Spuren...(6) : Bedeutung, Unterstützung, Abhilfemaßnahmen ... (5) : Zerstörung, Zerstörungsangriffe, Straßenzerstörungen, Schäden, Brände, Abwehr, Sprengung, Verminung .. (12) : Interesse, Überwindung, Entspannung, Wirtschaftlichkeit, Verhinderung, Verbesserung, Störung ... (16) : Anstrengungen, Abbau, Impuls, Versuch ... (16) : Verkehrsstunden, Aufwertung, Anerkennung ... (20) : Abfuhr, Akzeptanzschub ... (72) : Entwicklung, Tourismus, Politik, Zukunft ... (> 100) interessant: nachhaltige Entwicklung ist am hochfrequentesten, aber erst seit 1995 im Corpus belegt. Ebenso ist nachhaltiger Tourismus seit.")
106
nachhaltige Sprachbeobachtung?
Ich hoffe, ich konnte Ihnen den Nutzen der Sprachbeobachtung an diesen Beispielen aufzeigen. Nicht belegt in unserem Corpus ist die Verbindung nachhaltige Sprachbeobachtung? Vielleicht läßt sich dies noch in der ein- oder anderen Veröffentlichung über die Tagung nachholen...

107
Sprachbeobachtung mit Computerlinguistik
Institut für deutsche Sprache Projekt Deutscher Wortschatz – Uni Leipzig Lothar Lemnitzer ( DWDS: Prototyp: ZEIT-Wörter der Woche

108
Wörter der Woche - ZEIT

109
ZEIT-Woewo – 2

110
3. Schritte zu einem Digitalen Wörterbuch
Vorzüge des elektronischen Mediums: unbegrenzter Platz (für die Darstellung der Stichwörter) Gewichtung entsprechend des Vorkommens in Texten Belege können beliebig sortiert, ein- und ausgeblendet werden Das Wörterbuch kann „modular“ erarbeitet werden
 Gewichtung entsprechend des Vorkommens in Texten. Belege können beliebig sortiert, ein- und ausgeblendet werden. Das Wörterbuch kann „modular erarbeitet werden.")
111
Basis des Digitalen Wörterbuchs
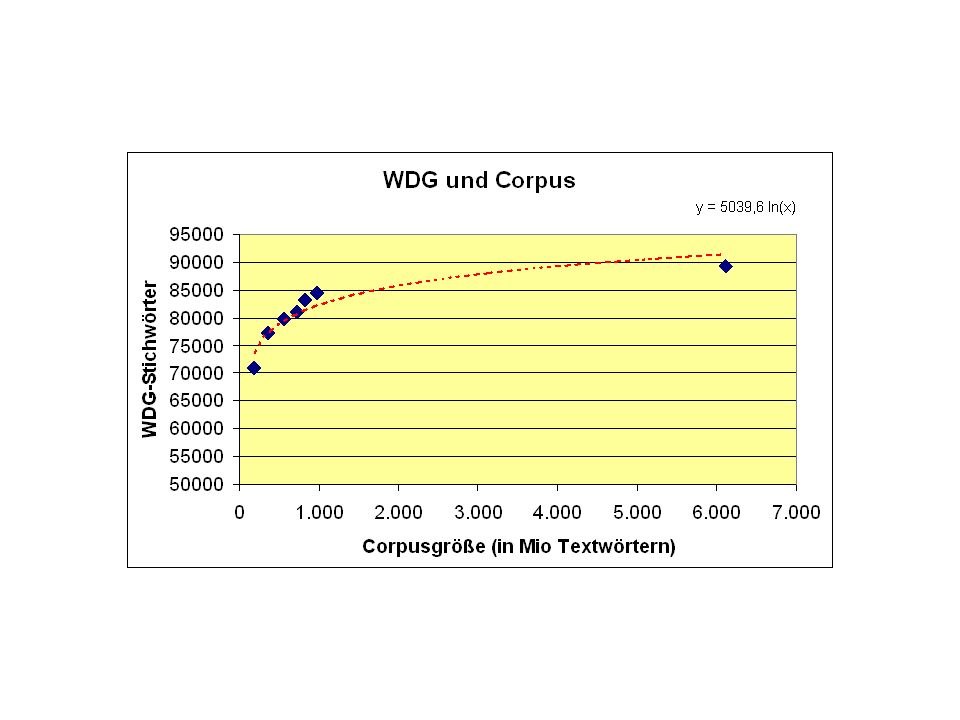
DWDS-Kerncorpus mit Suchmaschine Wörterbuch der deutschen Gegenwartssprache (1977) - 6 Bände, 5000 Seiten, ca Stichwörter Wörterbuch der deutschen Gegenwartssprache WDG: größte frei zugängliche gegenwartssprachliche deutsche Wörterbuch WDG: Kernbestandteil des zukünftigen digitalen Wörterbuchsystems.
 - 6 Bände, 5000 Seiten, ca Stichwörter. Wörterbuch der deutschen Gegenwartssprache. WDG: größte frei zugängliche gegenwartssprachliche deutsche Wörterbuch. WDG: Kernbestandteil des zukünftigen digitalen Wörterbuchsystems.")
112
„Modular“: Statt Corpus + Wörterbuch ...

113
... ein System von Wörterbüchern
entspricht der traditionellen Ebene der Sprachanalyse

114
... und einer Texterschliessungskomponente
opportunistisch, d.h. aber nicht „wahllos“, weil dennoch referenzierbar und „repräsentativ“, d.h. beispielsweise BILD, FAZ, NZZ, SPIEGEL, SZ, ZEIT, aber auch Konkret, TAZ, Computerwoche...

115
... mit Wörterbuchmodulen als Kooperationen

116
„Modul“ Kollokationen
in Kooperation mit C. Fellbaum (Princeton) im Rahmen des Wolfgang-Paul-Preis Projekts - Thema: Kollokationen im Wörterbuch Corpusbasierte lexikographische Beschreibung von Verb/Nomen Idiomen: sein Mütchen kühlen, den Nagel auf den Kopf treffen, sein blaues Wunder erleben, ...
 im Rahmen des Wolfgang-Paul-Preis Projekts. - Thema: Kollokationen im Wörterbuch. Corpusbasierte lexikographische Beschreibung von Verb/Nomen Idiomen: sein Mütchen kühlen, den Nagel auf den Kopf treffen, sein blaues Wunder erleben, ...")
117
... mit Filtern opportunistisch, d.h. aber nicht „wahllos“, weil dennoch referenzierbar und „repräsentativ“, d.h. beispielsweise BILD, FAZ, NZZ, SPIEGEL, SZ, ZEIT, aber auch Konkret, TAZ, Computerwoche...

118
Filter 2 opportunistisch, d.h. aber nicht „wahllos“, weil dennoch referenzierbar und „repräsentativ“, d.h. beispielsweise BILD, FAZ, NZZ, SPIEGEL, SZ, ZEIT, aber auch Konkret, TAZ, Computerwoche...

119
Filter 3 opportunistisch, d.h. aber nicht „wahllos“, weil dennoch referenzierbar und „repräsentativ“, d.h. beispielsweise BILD, FAZ, NZZ, SPIEGEL, SZ, ZEIT, aber auch Konkret, TAZ, Computerwoche...

120
DWDS – Texterschließung ist vielseitig nutzbar:
Zusammenfassung DWDS stellt Sprach- und Wortschatzforschung auf eine neue empirische Grundlage. DWDS – Texterschließung ist vielseitig nutzbar: Linguistische Suchmaschine Lemmatisierung, Wortartenzuordnung Kooperation zur Erarbeitung weiterer Wörterbuchmodule Gewinnung weiterer Textgeber opportunistisch, d.h. aber nicht „wahllos“, weil dennoch referenzierbar und „repräsentativ“, d.h. beispielsweise BILD, FAZ, NZZ, SPIEGEL, SZ, ZEIT, aber auch Konkret, TAZ, Computerwoche...

Ähnliche Präsentationen














.>")











>")
Digitalisierung Dipl. Sozw. Ralf Stockmann (SUB Göttingen)>")

