Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Formate, Codes & Algorithmen
Algorithmik Formate, Codes & Algorithmen

2
(Datei-) Formate
 Formate")
3
Digitale Information = Bitsequenzen
1 oder 0 Sein oder nicht Sein true oder false Ein Bit ist eine atomare Information Einen Informationsgehalt bekommt ein Bit, wenn es etwas repräsentiert z. B. schwanger / nicht schwanger Mehrere Bits können komplexere Informationen repräsentieren z.B. Zahlen, Farben, ... (oft Datentypen) Dazu muss man wissen, wofür eine bestimmte Bitsequenz (=Zeichen) steht ... und das wird komplizierter, wenn es nicht nur um eine Farbe, einen Buchstaben geht, sondern bspw. um ein ganzes Dokument Information existiert nicht in reiner Form eine Formulierung von Information kann für vieles stehen (repräsentieren)
 Dazu muss man wissen, wofür eine bestimmte Bitsequenz (=Zeichen) steht. ... und das wird komplizierter, wenn es nicht nur um eine Farbe, einen Buchstaben geht, sondern bspw. um ein ganzes Dokument. Information existiert nicht in reiner Form. eine Formulierung von Information kann für vieles stehen (repräsentieren)")
4
Definition (Daten-/Datei-) Format:
Ein Format ist eine spezifische Anordnung von Daten (Bits) für Speicherung, Weiterverarbeitung, Ausgabe, etc. Ein Format definiert so etwas wie eine Erwartungshaltung, in welcher Form (digitale) Information vorliegt. Das betrifft die Anordnung (wie teilt man die Sequenz in Zeichen auf?) die Codierung (für was steht ein Zeichen/Bitsequenz?) Diese grösstenteils impliziten (also nicht in der Sequenz enthaltenen) Informationen müssen allen Beteiligten bekannt sein – nur so kann man herausfinden, wofür die expliziten Informationen (Bitsequenz) stehen
 für Speicherung, Weiterverarbeitung, Ausgabe, etc. Ein Format definiert so etwas wie eine Erwartungshaltung, in welcher Form (digitale) Information vorliegt. Das betrifft. die Anordnung (wie teilt man die Sequenz in Zeichen auf ) die Codierung (für was steht ein Zeichen/Bitsequenz ) Diese grösstenteils impliziten (also nicht in der Sequenz enthaltenen) Informationen müssen allen Beteiligten bekannt sein – nur so kann man herausfinden, wofür die expliziten Informationen (Bitsequenz) stehen.")
5
Universalität vs. Speicherplatzbedarf
Ein Format macht nur Sinn, wenn es (für einen gewissen Bereich) universell ist, also bspw. alle Fotos speichern kann, nicht nur die grünen Andererseits benötigt diese Universalität Speicherplatz und ist nicht immer einfach festzulegen: macht es beispielsweise Sinn, in .DOC Unicode zu benutzen, nur damit die Chinesen dasselbe Format haben? ... oder sollte man Meta-Informationen einbauen, so dass z.B. die Codierung ausgetauscht oder explizit mitgeschickt werden kann?
 universell ist, also bspw. alle Fotos speichern kann, nicht nur die grünen. Andererseits benötigt diese Universalität Speicherplatz und ist nicht immer einfach festzulegen: macht es beispielsweise Sinn, in .DOC Unicode zu benutzen, nur damit die Chinesen dasselbe Format haben ... oder sollte man Meta-Informationen einbauen, so dass z.B. die Codierung ausgetauscht oder explizit mitgeschickt werden kann")
6
Digitale Repräsentation von Schach
oder: ein universeller digitale Koffer für Schach Was ist wichtig? nur die Information, die einen Spielstande eindeutig definiert Was ist möglich? alle Spielstände müssen repräsentiert werden können Welche Informationen codiert man (explizit) als Zeichen, welche (implizit) in der Anordnung? es geht nicht um maximale Effizienz, man muss aber trotzdem keinen Speicherplatz verschwenden Vorschläge? Wie viele Bits brauchen Sie?
 als Zeichen, welche (implizit) in der Anordnung es geht nicht um maximale Effizienz, man muss aber trotzdem keinen Speicherplatz verschwenden. Vorschläge Wie viele Bits brauchen Sie")
7
Ein Schach Format (.sch), 257 BIT
Das erste Bit gibt an, wer am Zug ist (1=schwarz, 0=weiss) Die folgenden 256 Bit repräsentieren die Belegung der 64 Felder, mit jeweils 4 Bit pro Feld (nummeriert zeilenweise von links nach rechts, dann spaltenweise von oben nach unten). Das erste Bit pro Feld steht für die Farbe der Figur: Die letzten 3 Bit pro Feld stehen für die Figur, die hier steht: 1 = schwarz 0 = weiss 000 = leer 100 = Pferd 001 = Bauer 101 = Dame 010 = Turm 110 = König 011 = Springer 111 = steht für nichts
 Die folgenden 256 Bit repräsentieren die Belegung der 64 Felder, mit jeweils 4 Bit pro Feld (nummeriert zeilenweise von links nach rechts, dann spaltenweise von oben nach unten). Das erste Bit pro Feld steht für die Farbe der Figur: Die letzten 3 Bit pro Feld stehen für die Figur, die hier steht: 1 = schwarz. 0 = weiss. 000 = leer. 100 = Pferd. 001 = Bauer. 101 = Dame. 010 = Turm. 110 = König. 011 = Springer. 111 = steht für nichts.")
8
Ein Format für Schieber-Jass
Das Spiel: 4 Spieler haben zu Beginn je 9 Karten, spielen sie reihum aus, und nach jeder Runde wandern 4 Karten auf den einen oder anderen Stapel von gespielten Karten. Aufgabe: erfinden Sie ein Format, mit dem jeder mögliche Zustand des Spiels binär repräsentiert werden kann. Formulieren Sie die von Ihnen erfundene Codierung so, dass ein anderer Schüler eine entsprechende Bitsequenz in den Spielzustand zurückübersetzen könnte Geben Sie an, wie viele Bits für die Speicherung eines Spielzustands benötigt werden

9
Und woher weiss der Computer, welches Format eine Datei hat?
Endung Header Diese Informationen sagen dem Computer, welche Brille er anziehen muss Die meisten Datei-Formate haben einen header, in dem sie sich vorstellen und zusätzliche Angaben zur Formatierung machen, z.B. Version/Variation des Formats Parameter allgemeine Zusatzinformationen

10
z.B. http://www.onlinehexeditor.com/
Beispiel.rtf öffnen mit Hex-Editor, z.B. { \rtf1\ansi\ansicpg1252\cocoartf1038\cocoasubrtf250 {\fonttbl\f0\fnil\fcharset0 GoudyOldStyleT-Regular;} {\colortbl;\red255\green255\blue255;\red6\green10\blue58;} \paperw11900\paperh16840\margl1440\margr1440\vieww9000\viewh8 400\viewkind0 \pard\tx566\tx1133\tx1700\tx2267\tx2834\tx3401\tx3968\tx4535\tx5102\t x5669\tx6236\tx6803\ql\qnatural\pardirnatural \f0\fs36 \cf2 Lirum \b larum \b0 L\ ‘f6ffelstiel }

11
RTF (Rich Text Format) Entwickelt von Microsoft, aber frei verfügbar
Basierend auf Standard-Codetabellen (ASCII, UNICODE) Lesbar von allen gängigen Texteditoren, wobei u.U. Teile der Layout-Information ignoriert werden
 Lesbar von allen gängigen Texteditoren, wobei u.U. Teile der Layout-Information ignoriert werden.")
12
RTF Spezifikationen Syntax: { <header> <document>}
Der header beinhalten Kontrollwörter, die mit Backslash anfangen und mit Leerzeichen getrennt werden Im header wird zusätzliche Layoutinformation repräsentiert, z.B. Schriftfarbe oder Schrifttyp RTF kann mit verschiedenen Versionen von ASCII oder UNICODE Zeichen umgehen (Meta-Information im header) Bei RTF wird implizit angenommen, dass die entsprechenden Codetabellen verfügbar sind, und dass die Blöcke innerhalb der Bitsequenz in der richtigen Reihenfolge vorliegen
 Bei RTF wird implizit angenommen, dass die entsprechenden Codetabellen verfügbar sind, und dass die Blöcke innerhalb der Bitsequenz in der richtigen Reihenfolge vorliegen.")
13
Zusammenfassung RTF kann mehr als TXT und weniger als DOC, das ist seine „digitale Nische“ RTF ermöglicht die Repräsentation von allgemeinen Layoutinformation durch standardisierte Kontrollwörter im header Das Layout für Textteile geschieht durch Auszeichnung des Dokuments mit Kontrollwörtern im Text (wie HTML)
")
14
Eine Analogie zur Zusammenfassung
Bildinformation in einem etwas speziellen Format Die Brille implementiert die Decodierung Das Format gibt an, welche Brille man braucht

15
Konzepte Beispiele Format Eigene Formate für Spiele .rtf Header Endung
Zeichen explizite & implizite Bestandteile Universalität Eigene Formate für Spiele .rtf

16
z.B. http://www.onlinehexeditor.com/
Datei: Raetsel öffnen mit Hex-Editor, z.B. <svg version="1.1“ xmlns=" xmlns:xlink= xmlns:a=" x="0px" y="0px" width="400px" height="400px" viewBox=" “ enable-background="new " xml:space="preserve"> <defs> </defs> <rect fill="#FF0000" stroke="none" x="0" y="0" width="400" height="400"/> <polygon fill="#FFFFFF" stroke="#FFFFFF" points="350,250 50,250 50, ,150"/> <polygon fill="#FFFFFF" stroke="#FFFFFF" points="250, , ,50 250,50"/> </svg>

17
und verlustbehaftete Komprimierung
Grafikformate und verlustbehaftete Komprimierung

18
Wie viel Information ist nötig?
Anfangs- und Endpunkt definieren die Linie eindeutig Mittelpunkt und Radius definieren den Kreis eindeutig Die Eckpunkte definieren das Polygon eindeutig

19
Vektorgrafik Mit allgemeinen Kurven (z.B. Bezier Kurven) und noch mehr Parametern kann man jede beliebige Form berechen kann zu extrem geringen Dateigrössen führen Vektorgrafiken sind beliebig skalierbar 26 Kb

20
26 Kb

21
Reine Vektorgrafikformate
Sind nicht weit verbreitet, meist proprietär, in Verbindung mit einem Editor – z.B. Adobe Illustrator (.ai) Ausnahme: SVG (scalable vector graphics) Benutzt werden Vektorgrafiken aber oft in Kombination, z.B. einzelne Ebenen in Photoshop Vektor-Fonts Zeichnungen in Word oder Powerpoint in Druckformaten (PDF, EPS) Interessant: .pptx hacken
 Ausnahme: SVG (scalable vector graphics) Benutzt werden Vektorgrafiken aber oft in Kombination, z.B. einzelne Ebenen in Photoshop. Vektor-Fonts. Zeichnungen in Word oder Powerpoint. in Druckformaten (PDF, EPS) Interessant: .pptx hacken.")
22
Flagge der Marshall Islands

26
Konzepte Beispiele Vektor- vs. Raster Farbtiefe Farbraum
indizierte Farben Farbraum RGB(A), CMYK, LAB Pixel zusammenfassen Farbverlauf Lauflänge .svg .bmp .jpg .gif .png, .tiff, RAW, .psd, eps
, CMYK, LAB. Pixel zusammenfassen. Farbverlauf. Lauflänge. .svg. .bmp. .jpg. .gif. .png, .tiff, RAW, .psd, eps.")
27
Reine Rastergrafikformate
Produzieren sehr grosse Dateien (aber verlustfrei) Beispiele .bmp – nur Windows, veraltet .pict – nur MAC, veraltet .tiff – (wenn ohne Komprimierung) Bestes Format für sehr hohe Qualität, üblich beim Drucken RAW – reine Sensordaten, für jede Kamera anders
 Beispiele. .bmp – nur Windows, veraltet. .pict – nur MAC, veraltet. .tiff – (wenn ohne Komprimierung) Bestes Format für sehr hohe Qualität, üblich beim Drucken. RAW – reine Sensordaten, für jede Kamera anders.")
28
RAW ist abhängig von Kamerasensor bzw. –Hersteller
DNG ist Adobes Versuch für ein herstellerübergreifendes Standard- RAW-Format RAW-Dateien haben eine höhere Farbtiefe (10 – 16 Bit) RAW-Dateien richten sich nach dem geomet- rischen Layout des Sensors, meist Bayer-Matrix Arbeitsschritte wie Demosaicing, Rauschunterdrückung, Weissabgleich, oder Tonwertkorrekturen können mit RAW- Daten in der Nachbearbeitung festgelegt werden Verschieden Algorithmen führen zu leicht unterschiedlichen Ergebnissen Bei starken Manipulationen verhilft die Farbtiefe zu besseren Ergebnissen
 RAW-Dateien richten sich nach dem geomet- rischen Layout des Sensors, meist Bayer-Matrix. Arbeitsschritte wie Demosaicing, Rauschunterdrückung, Weissabgleich, oder Tonwertkorrekturen können mit RAW- Daten in der Nachbearbeitung festgelegt werden. Verschieden Algorithmen führen zu leicht unterschiedlichen Ergebnissen. Bei starken Manipulationen verhilft die Farbtiefe zu besseren Ergebnissen.")
29
Die üblichsten Grafikformate (.jpg & .gif)
Komprimieren die Information reiner Rastergrafiken Nehmen ggf. Informationsverlust in Kauf (meist variabel) Ansätze zum (verlustbehafteten) Komprimieren: mehrere Pixel zusammenfassen Speicherplatz sparen bei der Repräsentation von Farben Dabei geht es immer darum, möglichst die Informationen zu verlieren, die (optisch) keinen grossen Unterschied machen
 Ansätze zum (verlustbehafteten) Komprimieren: mehrere Pixel zusammenfassen. Speicherplatz sparen bei der Repräsentation von Farben. Dabei geht es immer darum, möglichst die Informationen zu verlieren, die (optisch) keinen grossen Unterschied machen.")
30
JPG & GIF Pixel zusammenfassen Farben repräsentieren Besonderheiten
Anwendungsgebiet
![]()
31
JPG in Bildern

32
GIF in Bildern

33
Probleme & Spezialitäten

34
Formatentscheidungen
Sie wollen mit ihrer Digitalkamera ein Photo aufnehmen, um dann Sie dann im Internet einen Abzug in Postergrösse zu bestellen. Wie gehen Sie optimalerweise vor? Ein Freund von ihnen hat gehört, dass Vektorgraphiken wenig Speicherplatz brauchen und trotzdem skalierbar sind. Er hat ein Logo für seine Webseite gezeichnet (von Hand) und fragt Sie, wie er es in ein Vektorformat umwandelt. Was raten Sie ihm? Sie wollen ihren Freunden ein paar Urlaubsbilder per schicken. Wie gehen Sie vor? Für die Maturazeitung verfassen Sie einen Artikel, in dem sie auch einige statistische Grafiken zeigen wollen. Worauf achten Sie?
 und fragt Sie, wie er es in ein Vektorformat umwandelt. Was raten Sie ihm Sie wollen ihren Freunden ein paar Urlaubsbilder per schicken. Wie gehen Sie vor Für die Maturazeitung verfassen Sie einen Artikel, in dem sie auch einige statistische Grafiken zeigen wollen. Worauf achten Sie")
35
Zusammenfassung Ein Bild besteht aus Pixeln (Rastergrafik)
Auflösung, Farbraum, Farbtiefe, Transparenz? (ggf.) verlustbehaftete Komprimierung: Farben indizieren (.gif) Farbtiefe (in LAB-Farbraum) reduzieren (.jpg) Blöcke gleicher Pixel zusammenfassen (.gif) Farbverläufe zusammenfassen (.jpg) Ein Bild besteht aus geometrischen Objekten, bzw. Kurven (Vektorgrafik) Wie beschreibt man die Formen, welche Parameter gibt es?
![]()
36
(Grafik-) Formate, Überblick
BMP (Rastergrafik, Farbräume erwähnen) JPEG (Grafik mit Kompression) GIF (Grafik mit Kompression) PNG (Grafik mit Kompression, inkl. Alphakanal) TIFF (Grafik mit optionaler Kompression) SVG (Vektorgrafik) EPS (Druckerformat, Rastergrafik + Vektorgrafik) PDF (Grafik + Text) ZIP* (Komprimierung) RAR (Archivierung) MIDI (Musik) MP3 (Musik) AVI (Video) MOV (Video) MPEG (Video) Warum gibt es dieses Format? Wie funktioniert dieses Format?
 JPEG (Grafik mit Kompression) GIF (Grafik mit Kompression) PNG (Grafik mit Kompression, inkl. Alphakanal) TIFF (Grafik mit optionaler Kompression) SVG (Vektorgrafik) EPS (Druckerformat, Rastergrafik + Vektorgrafik) PDF (Grafik + Text) ZIP* (Komprimierung) RAR (Archivierung) MIDI (Musik) MP3 (Musik) AVI (Video) MOV (Video) MPEG (Video) Warum gibt es dieses Format Wie funktioniert dieses Format")
37
Verlustfreie Komprimieren
bzw. digitales Koffer packen

38
Aufgabenstellung: Sie wollen ihrem Freund eine Text-Botschaft übermitteln, können dazu aber nur Zahlen verwenden (entscheiden Sie selbst ob sie Dezimal- oder Binärzahlen benutzen). Überlegen Sie sich eine Methode, wie die gegebene Botschaft möglichst genau und möglichst kompakt in Zahlen übersetzt werden kann. Dann erstellen Sie zwei Textdokumente: Ein Dokument soll nur die Zahlenfolge enthalten Im anderen Dokument formulieren Sie eine Anleitung, mit deren Hilfe ihr Freund die ursprüngliche Botschaft aus der Zahlenfolge rekonstruieren kann
. Überlegen Sie sich eine Methode, wie die gegebene Botschaft möglichst genau und möglichst kompakt in Zahlen übersetzt werden kann. Dann erstellen Sie zwei Textdokumente: Ein Dokument soll nur die Zahlenfolge enthalten. Im anderen Dokument formulieren Sie eine Anleitung, mit deren Hilfe ihr Freund die ursprüngliche Botschaft aus der Zahlenfolge rekonstruieren kann.")
39
Auswertung Hat es geklappt? Was war schwierig?
Welche Informationen wurden übermittelt? (genau?) Wie viele Zahlen waren nötig? (kompakt?) Welche anderen Botschaften könnten so verschickt werden? Welche grundsätzliche Idee steckt hinter dieser Methode?
 Wie viele Zahlen waren nötig (kompakt ) Welche anderen Botschaften könnten so verschickt werden Welche grundsätzliche Idee steckt hinter dieser Methode")
40
Arbeitsauftrag Ihr Ziel ist herauszufinden, wie die Huffman Codierung funktioniert und sie selbst anwenden zu können Benutzen Sie dazu das Applet HuffmanApplet.jar Experimentieren Sie mit dem Applet (nur Huffman Code) und versuchen Sie, die Fragen im Arbeitsblatt AB Huffman Komprimierung.doc zu beantworten
 und versuchen Sie, die Fragen im Arbeitsblatt AB Huffman Komprimierung.doc zu beantworten.")
41
Besprechung Suchen Sie sich einen Partner und tauschen Sie ihre Ergebnisse aus Notieren Sie alles, was ihnen beiden noch unklar ist Können Sie die grundsätzliche Idee formulieren?

42
Konzepte Beispiele Block-Codierung Frequenz-Codierung
Präfixfreier Code Telefonnummern Morse-Code Huffman Codierung Arithmetische Codierung

43
Frequenzcodierung

44
Präfixfreie Telefonnummern
Was Telefonnummer Allgemeiner Notruf 112 Feuerwehrnotruf 118 Polizeinotruf 117 Sanitätsnotruf 144 Rega (Rettungshelikopter) 1414 Pannenhilfe 140 Toxikologisches Institut (bei Vergiftungen) 145 Auch normale Telefonnummern erfüllen die Fano-Bedingung, z.B. wenn das eine gültige Nummer ist dann kann es diese oder diese nicht geben
 Pannenhilfe Toxikologisches Institut (bei Vergiftungen) 145. Auch normale Telefonnummern erfüllen die Fano-Bedingung, z.B wenn das eine gültige Nummer ist dann kann es diese oder diese nicht geben.")
45
Information Genau & Kompakt
Koffer packen (Komprimieren von Information) Information Genau & Kompakt Codieren Komprimieren Koffer (~ Format) so wählen, dass alles eingepackt werden kann, was man im Urlaub vielleicht brauchen könnte Ziel: Der Koffer soll für alle Urlaube geeignet sein! Effizient packen, so dass möglichst wenig Luft im Koffer bleibt kann davon abhängen, was genau eingepackt wurde! Ziel: Der Koffer für diesen Urlaub soll möglichst klein werden!
 Information Genau & Kompakt. Codieren. Komprimieren. Koffer (~ Format) so wählen, dass alles eingepackt werden kann, was man im Urlaub vielleicht brauchen könnte. Ziel: Der Koffer soll für alle Urlaube geeignet sein! Effizient packen, so dass möglichst wenig Luft im Koffer bleibt kann davon abhängen, was genau eingepackt wurde! Ziel: Der Koffer für diesen Urlaub soll möglichst klein werden!")
46
Effizientes Packen von Buchstaben
Codieren von Buchstaben als binäre Codewörter ASCII Code Komprimieren der Bitsequenz z.B. Huffman Codierung kürzere Sequenz + neue Codewörter Speichern oder Übermitteln Dekomprimieren Decodieren -> Darstellen

47
Komprimierung von Buchstaben
originale Nachricht (z.B. ASCII) codierte Nachricht + Liste (z.B. Huffman) Komprimieren, z.B. mit Huffman Codierung Dekomprimieren, z.B. mit Huffman Decodierung Welche Informationen braucht es hier? speichern /verschicken
 codierte Nachricht + Liste. (z.B. Huffman) Komprimieren, z.B. mit Huffman Codierung. Dekomprimieren, z.B. mit Huffman Decodierung. Welche Informationen braucht es hier speichern /verschicken.")
48
ASCII (American Standard Code for Information Interchange)
Dezimal Hex Binär Zeichen 96 60 ` 97 61 a 98 62 b 99 63 c 100 64 d 101 65 e 102 66 f 103 67 g 104 68 h 105 69 i 106 6A j 107 6B k 108 6C l 109 6D m 110 6E n 111 6F o 112 70 p 113 71 q 114 72 r 115 73 s 116 74 t 117 75 u 118 76 v 119 77 w 120 78 x 121 79 y 122 7A z 123 7B { 124 7C | 125 7D } 126 7E ~ 127 7F DEL ASCII (American Standard Code for Information Interchange) Kleinbuchstaben:
 Kleinbuchstaben:")
49
Huffman Komprimierung

50
Huffman Decodierung Die binäre Nachricht: 0100111101001110010100111110
Die Codewörter: e = 110 d = 111 o = 00 p = 010 s = 011 u = 100 c = 101 Hinweis: Am einfachsten ist es, wenn Sie sich zunächst den zu den Codewörtern gehörenden Baum aufzeichnen

51
Und was daran war jetzt präfixfrei?
o = 00 p = 010 s = 011 u = 100 c = 101 e = 110 d = 111

52
Komprimierung allgemein
originale Nachricht (z.B. ASCII) codierte Nachricht + Liste (z.B. Huffman) Komprimieren, z.B. mit Huffman Codierung Dekomprimieren, z.B. mit Huffman Decodierung Welche Informationen braucht es hier? speichern /verschicken
 codierte Nachricht + Liste. (z.B. Huffman) Komprimieren, z.B. mit Huffman Codierung. Dekomprimieren, z.B. mit Huffman Decodierung. Welche Informationen braucht es hier speichern /verschicken.")
53
Grundsätzliche Idee bei Huffman
Häufige Zeichen (Buchstaben) werden in kurze Codewörter übersetzt (Frequenzcodierung) Im Binärsystem funktioniert das nur, wenn der entstehende Code (die Codewörter) präfixfrei ist! Die Bäumchen-Taktik (eigentlich ein Algorithmus) produziert eine Codierung, die diese beiden Prinzipien optimal verbindet. (allerdings ist der resultierende Komprimierungsgrad nur annähernd optimal, noch effizienter ist die Arithmetische Codierung)
 werden in kurze Codewörter übersetzt (Frequenzcodierung) Im Binärsystem funktioniert das nur, wenn der entstehende Code (die Codewörter) präfixfrei ist! Die Bäumchen-Taktik (eigentlich ein Algorithmus) produziert eine Codierung, die diese beiden Prinzipien optimal verbindet. (allerdings ist der resultierende Komprimierungsgrad nur annähernd optimal, noch effizienter ist die Arithmetische Codierung)")
54
Pseudocode ... ist eine sprachliche Mischung aus natürlicher Sprache, mathematischer Notation und einer höheren Programmier- sprache arrayMax(A, n) // Input: Ein Array A, der n Integer Werte enthält // Output: Das maximale Element in A currentMax = A[0] for i = 1 to n - 1 if currentMax < A[i] currentMax = A[i] end return currentMax
 // Input: Ein Array A, der n Integer Werte enthält. // Output: Das maximale Element in A. currentMax = A[0] for i = 1 to n - 1. if currentMax < A[i] currentMax = A[i] end. return currentMax.")
55
decodieren(nachricht_bin, codewortliste)
// Input: die Bitsequenz nachricht_bin und // eine Liste, die binären Codeworten Zeichen zuordnet // Output: nachricht_txt; die decodierte Nachricht, eine Sequenz von Zeichen nachricht_txt = leer; länge = 1; while (nachricht_bin != leer) zeichen_bin = get_first_n_bits(nachricht_bin, länge); if found_in(zeichen_bin, codewortliste) zeichen_txt = get_letter(zeichen_bin, codewortliste) nachricht_txt = attach_letter(zeichen_txt); nachricht_bin = delete_first_n_bits(länge); else länge ++; end return nachricht_txt;
 zeichen_bin = get_first_n_bits(nachricht_bin, länge); if found_in(zeichen_bin, codewortliste) zeichen_txt = get_letter(zeichen_bin, codewortliste) nachricht_txt = attach_letter(zeichen_txt); nachricht_bin = delete_first_n_bits(länge); else. länge ++; end. return nachricht_txt;")
56
Pseudocode für Huffman Codierung
codieren(nachricht_ascii) // Input: die Bitsequenz nachricht_ascii, bestend aus einer Sequenz von ASCII Zeichen (jeweils ein Byte) // Output: nachricht_bin; die codierte Nachricht, eine Bitsequenz // codewortliste; eine Liste, die binären Codeworten ASCII Zeichen zuordnet
 // Input: die Bitsequenz nachricht_ascii, bestend aus einer Sequenz von ASCII Zeichen (jeweils ein Byte) // Output: nachricht_bin; die codierte Nachricht, eine Bitsequenz. // codewortliste; eine Liste, die binären Codeworten ASCII Zeichen zuordnet.")
57
Huffman Komprimierung
ASCII Nachricht in 8-er Blöcke aufteilen, zählen wie oft jeder Block vorkommt Blöcke nach Häufigkeit ordnen Mit Huffman Baum präfixfreie Codewortliste erstellen ASCII Nachricht nach Huffman übersetzen, siehe Liste Bitsequenz & Liste in File speichern, evtl. verschicken Auch transportiert werden muss die Information, dass dieses File Huffman-codiert ist

58
Fragen zu Huffman & Komprimierung
Was ist die grundlegende Idee hinter Huffman Komprimierung? Wann ist Huffman am effizientesten? Wann lohnt sich Huffman sicher nicht? Warum benutzt z.B. Word kein Huffman Komprimierung? Was wären andere grundlegende Ideen zu Komprimierung von Daten? (Erklären Sie anhand eines Beispiels) Was sind allgemeine Vorteile von Datenkomprimierung? Was sind allgemeine Nachteile der Datenkomprimierung? originale Nachricht codierte Nachricht
 Was sind allgemeine Vorteile von Datenkomprimierung Was sind allgemeine Nachteile der Datenkomprimierung originale Nachricht. codierte Nachricht.")
59
Enthropie

60
Konzepte Beispiele Huffman in .zip Entropieschätzung
(Informations) Entropie Entropieschätzung Huffman in .zip
 Entropie. Entropieschätzung. Huffman in .zip.")
61
Was ist eigentlich Information?
Was ist das kleinstmögliche Bisschen an Information? Sein oder nicht Sein, das ist hier die Frage.

62
Ein BIT ist: There are 10 sorts of people:
those who unterstand binary and those who do not. eine Bezeichnung für eine Binärziffer (üblicherweise „0“ und „1“). eine Maßeinheit für die Datenmenge bei digitaler Speicherung von Daten. Die Datenmenge entspricht in diesem Fall der verwendeten Anzahl von binären Variablen zur Abbildung der Information. eine Maßeinheit für den Informationsgehalt (siehe Shannon). Dabei ist 1 Bit der Informationsgehalt, der in einer Auswahl aus zwei gleich wahrscheinlichen Möglichkeiten enthalten ist.
. eine Maßeinheit für die Datenmenge bei digitaler Speicherung von Daten. Die Datenmenge entspricht in diesem Fall der verwendeten Anzahl von binären Variablen zur Abbildung der Information. eine Maßeinheit für den Informationsgehalt (siehe Shannon). Dabei ist 1 Bit der Informationsgehalt, der in einer Auswahl aus zwei gleich wahrscheinlichen Möglichkeiten enthalten ist.")
63
Ordnen Sie diese Bitsequenzen nach Informationsgehalt (aufsteigend)

64
Ordnen Sie diese Bitsequenzen nach Informationsgehalt (aufsteigend)
2. 1. (= 1 Bit) 4c 4b (ASCII = ce) 4a 3.
 4c 4b (ASCII = ce) 4a 3.")
65
Entropie ist eine physikalische Zustandsgröße in der Thermodynamik
ein Maß für den mittleren Informationsgehalt oder auch Informationsdichte eines Zeichensystems Warum sollte uns das interessieren? Huffman Komprimierung ist das Paradebeispiel für eine Entropiecodierung

66
Entropie & Wahrscheinlichkeit
Der Normalzustand (= maximale Entropie) ist die Gleichverteilung Abweichungen von der Gleichverteilung bedeuten: es gibt eine gewisse Ordnung, Struktur man kann es kompakter beschreiben was trägt mehr Information? was ist wahrscheinlicher?
 ist die Gleichverteilung. Abweichungen von der Gleichverteilung bedeuten: es gibt eine gewisse Ordnung, Struktur. man kann es kompakter beschreiben was trägt mehr Information was ist wahrscheinlicher")
67
Berechnen der Informationsdichte
H = Entropie Z = endliches Alphabet von Zeichen z = ein einzelnes Zeichen p = Auftretenswahrscheinlichkeit (=Häufigkeit z/Gesamthäufigkeit) Für das deutsche Alphabet: Eine perfekte Komprimierung würde genau diesen Entropiewert erreichen
 Für das deutsche Alphabet: Eine perfekte Komprimierung würde genau diesen Entropiewert erreichen.")
68
Wozu brauchen wir das? ASCII Nachricht in 8-er Blöcke aufteilen, zählen wie oft jeder Block vorkommt Blöcke nach Häufigkeit ordnen Mit Huffman Baum präfixfreie Codewortliste erstellen ASCII Nachricht nach Huffman übersetzen, siehe Liste Bitsequenz & Liste in File speichern, evtl. verschicken Auch transportiert werden muss die Information, dass dieses File Huffman-codiert ist Was, wenn wir nicht wissen ob es ASCII Zeichen sind? (z.B. beim zippen)
")
69
Normierung für unterschiedliche Block-, bzw. Zeichenlängen
Wozu brauchen wir das? Entropie wird pro Zeichen berechnet - aber was ist ein Zeichen? 8er: 4er: noch allgemeiner: konditionelle Entropie Normierung für unterschiedliche Block-, bzw. Zeichenlängen

70
Huffman generalisiert
Binäre Nachricht durch Entropietests/Schätzung darauf analysieren, welche Bits ein Zeichen bilden sollten, so dass sich die niedrigste Entropie ergibt Binäre Nachricht in Zeichen aufteilen, zählen wie oft jedes Zeichen vorkommt Blöcke nach Häufigkeit ordnen Mit Huffman Baum präfixfreie Codewortliste erstellen Binäre Nachricht nach Huffman übersetzen, s. Liste Bitsequenz & Liste in File speichern, evtl. verschicken Auch transportiert werden muss die Information, dass dieses File Huffman-codiert ist

71
Entropiecodierung bedeutet
mit einer Entropieschätzung herausfinden, welche Abschnitte der originalen Bitsequenz man als Zeichen ansehen sollte diese Zeichen dann so in präfixfreie Codewörter übersetzen, dass den häufigsten Zeichen die kürzesten Codewörter zugeordnet werden ACHTUNG: trade-off der Listengrösse berücksichtigen!

72
Entropiecodierung ist
eine allgemeine Methode um zu bestimmen, wie viel Luft im Koffer ist, und den Koffer dann so umzupacken, dass möglicht wenig Luft verbleibt wie Legomodell verpacken. Zuerst muss man herausfinden, in wie kleine Teile man es zerlegen soll, und dann braucht man eine Methode, um diese Teile effizient ineinander zu stapeln

73
Optimalität der Huffman Codierung
ist die wohl am weitesten verbreitete Art der Entropiecodierung wird oft als letzter Schritt auf beliebige Bitsequenzen angewandt ist nur annähernd optimal. Bsp: völlig zufällige Sequenz mit drei mal mehr Nullen als Einsen - (1/4*lg(1/4)+3/4*lg(3/4)) = Bit/Zeichen(=Bit) weniger als ein Bit geht aber nicht, die beiden kürzest möglichen Codewörter haben jeweils ein Bit Noch bessere Lösung: Arithmetische Codierung
+3/4*lg(3/4)) = Bit/Zeichen(=Bit) weniger als ein Bit geht aber nicht, die beiden kürzest möglichen Codewörter haben jeweils ein Bit. Noch bessere Lösung: Arithmetische Codierung.")
74
Arithmetische Codierung
Die gesamte Nachricht in einer einzigen Zahl ... ... ausserdem braucht es die Zeichen und ihre Frequenz ... ... und einen schnellen Computer Die gesamte Nachricht in einer einzigen Zahl ... ... ausserdem braucht es die Zeichen und ihre Frequenz ... ... und einen schnellen Computer A = 0.6 B = 0.2 C = 0.1 D = 0.1 Zahl = 0.536 Nachricht = ACD Applet: lossless.jar

75
Lernziele - erreicht?? Sie verstehen, was Hamlet mit dem zersplitternden Weinglas zu tun hat, und wie beide mit der Huffman Kodierung zusammenhängen Sie kennen die allgemeine Form der Huffman Kodierung Zusatz: Sie können erklären a) warum die Block-Entropie einer Bitsequenz am kleinsten ist, wenn man die gesamte Sequenz als einen einzigen Block (= ein Zeichen) ansieht b) warum es trotzdem keinen Sinn macht, die ganze Sequenz als eine einziges Zeichen zu kodieren
 warum die Block-Entropie einer Bitsequenz am kleinsten ist, wenn man die gesamte Sequenz als einen einzigen Block (= ein Zeichen) ansieht. b) warum es trotzdem keinen Sinn macht, die ganze Sequenz als eine einziges Zeichen zu kodieren.")
76
Hausaufgaben Prüfziffern (jede(r) eine andere)
Möglichkeiten s. Wiki Eine übersichtliche Seite zusammenstellen mit Kurzbeschreibung: Berechnung dieser Prüfziffer Beispiel Versuch einer allgemeinen Definition von Prüfziffer

77
Fehlerkorrigierende Codes

78
Ein bisschen Magie!

79
Wie funktioniert der Trick?
Eine Hinweis:

80
Wie funktioniert der Trick?
Eine zufällige binäre Matrix wird um eine Spalte und eine Zeile ergänzt Dort wird jeweils das Paritätsbit eingetragen alle Zeilen und Spalten sind gerade Das geflippte Bit ist am Kreuzungspunkt der einzigen ungeraden Zeile & Spalte Technisch ausgedrückt (für 5x5): Ein (25,16)-fehlerkorrigierender Code mit HD = 4 1 1 1 1 1 1 1 1
: Ein (25,16)-fehlerkorrigierender Code mit HD =")
81
Wie funktioniert der Trick?
Eine zufällige binäre Matrix wird um eine Spalte und eine Zeile ergänzt Dort wird jeweils das Paritätsbit eingetragen alle Zeilen und Spalten sind gerade Das geflippte Bit ist am Kreuzungspunkt der einzigen ungeraden Zeile & Spalte Technisch ausgedrückt (für 5x5): Ein (25,16)-fehlerkorrigierender Code mit HD = 4 1 1 1 1 1 1 1 1 1
: Ein (25,16)-fehlerkorrigierender Code mit HD =")
82
Exkurs: Zusammenhang mit Prüfziffern?
Prüfziffern dienen der Fehlererkennung (wie Paritätsbits)
")
83
Wie funktionieren Prüfziffern? (allgemein)
Sender: Empfänger berechnen 3 anhängen berechnen 3 vergleichen ungleiche Prüfziffern es ist ein Fehler passiert

84
Prüfziffern Eigenschaften der Prüfzifferberechnung:
Redundanz: 1 Dezimalstelle 10% der Zeichen haben dieselbe Prüfziffer aber: die Versagensquote ist niedriger, weil die häufigsten Fehler erkannt werden (z.B. Zahlendreher) Eigenschaften der Prüfzifferberechnung: Menge der redundanten Informationen? Wie viele Fehler werden erkannt? Welche Fehler werden erkannt?
 Eigenschaften der Prüfzifferberechnung: Menge der redundanten Informationen Wie viele Fehler werden erkannt Welche Fehler werden erkannt")
85
Konzepte Beispiele Binärmagie Hamming-Code CIRC Fehlerkorrektur
Fehlererkennung Prüfsumme Paritätsbit Fehlerkorrektur Hamming-Distanz Binärmagie Hamming-Code CIRC

86
Paritätsbits sind minimale Prüfziffern
Redundanz: 1 Bit 50% der Zeichen haben dasselbe Prüfbit aber: der einfachste Fehler (ein geflipptes Bit) wird erkannt Mit mehreren, geschickt kombinierten Paritätsbit können Fehler nicht nur erkannt, sondern auch korrigiert werden: (9,4)Code – 5 Bit redundant (geht das effizienter?) 1 1 1 kann ein geflipptes Bit korrigieren kann zwei geflippte Bit erkennen (sicher? wie beweisen?) 1 1
 wird erkannt. Mit mehreren, geschickt kombinierten Paritätsbit können Fehler nicht nur erkannt, sondern auch korrigiert werden: (9,4)Code – 5 Bit redundant. (geht das effizienter ) kann ein geflipptes Bit korrigieren. kann zwei geflippte Bit erkennen. (sicher wie beweisen )")
87
(7,4)Hamming-Code: codieren
1 2 3 1 4 ? 5 ? 6 ? 7 1 ? 5 ? 6 Daten P-Bits 1 4 2 3 3 redundante Bits 1 Bit Korrektur 2 Bit Erkennung (?!) ? 7
 7.")
88
(7,4)Hamming-Code: codieren
1 2 3 1 4 5 6 1 7 1 5 6 Daten P-Bits 1 4 2 3 3 redundante Bits 1 Bit Korrektur 2 Bit Erkennung (?!) 1 7
")
89
(7,4)Hamming-Code: decodieren
1 1 2 3 1 4 1 5 1 6 1 7 1 1 5 1 6 Daten P-Bits 1 4 1 2 3 3 redundante Bits 1 Bit Korrektur 2 Bit Erkennung (?!) 1 7
")
90
(7,4)Hamming-Code: decodieren
1 2 3 1 4 1 5 1 6 1 7 1 1 5 1 6 Daten P-Bits 1 4 2 3 3 redundante Bits 1 Bit Korrektur 2 Bit Erkennung (?!) 1 7
")
91
Üben - decodieren 1 2 3 4 5 6 7 1 2 3 4 5 6 7 1 2 3 4 5 6 7 1 2 3 4 5 6 7 1 2 3 4 5 6 7 1 2 3 4 5 6 7 1 2 3 4 5 6 7 1 2 3 4 5 6 7

92
Üben: codieren 1 2 3 4 5 6 7 1 2 3 4 5 6 7 1 2 3 4 5 6 7 1 2 3 4 5 6 7 1 2 3 4 5 6 7 1 2 3 4 5 6 7 1 2 3 4 5 6 7 1 2 3 4 5 6 7 1 2 3 4 5 6 7 1 2 3 4 5 6 7 1 2 3 4 5 6 7 1 2 3 4 5 6 7 1 2 3 4 5 6 7 1 2 3 4 5 6 7 1 2 3 4 5 6 7 1 2 3 4 5 6 7
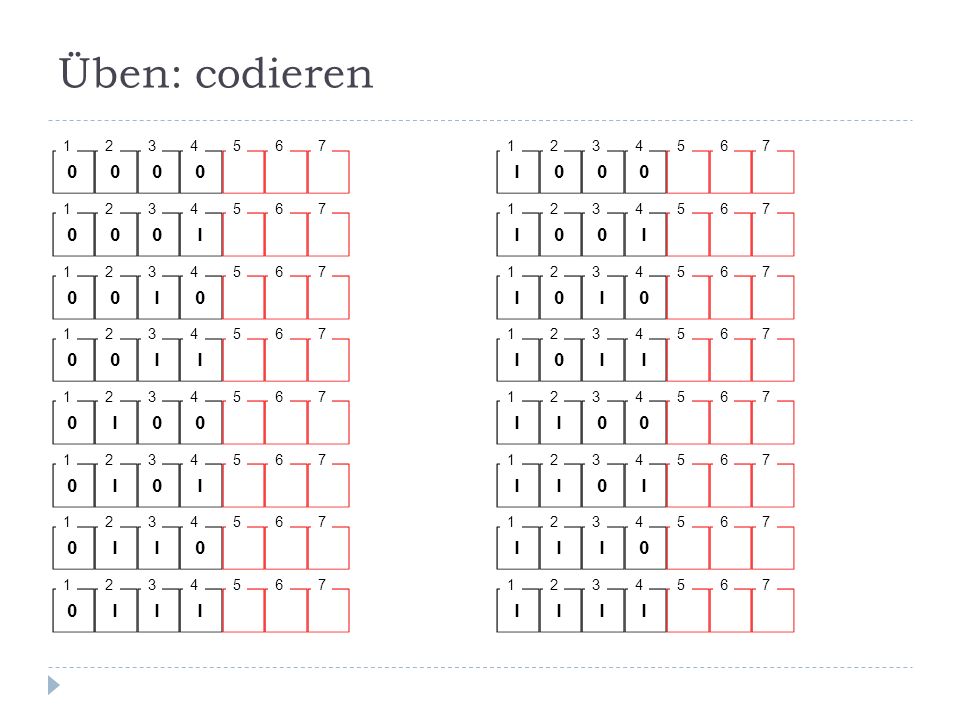
93
Lösungen 1 2 3 4 5 6 7 1 2 3 4 5 6 7 1 2 3 4 5 6 7 1 2 3 4 5 6 7 1 2 3 4 5 6 7 1 2 3 4 5 6 7 1 2 3 4 5 6 7 1 2 3 4 5 6 7 1 2 3 4 5 6 7 1 2 3 4 5 6 7 1 2 3 4 5 6 7 1 2 3 4 5 6 7 1 2 3 4 5 6 7 1 2 3 4 5 6 7 1 2 3 4 5 6 7 1 2 3 4 5 6 7
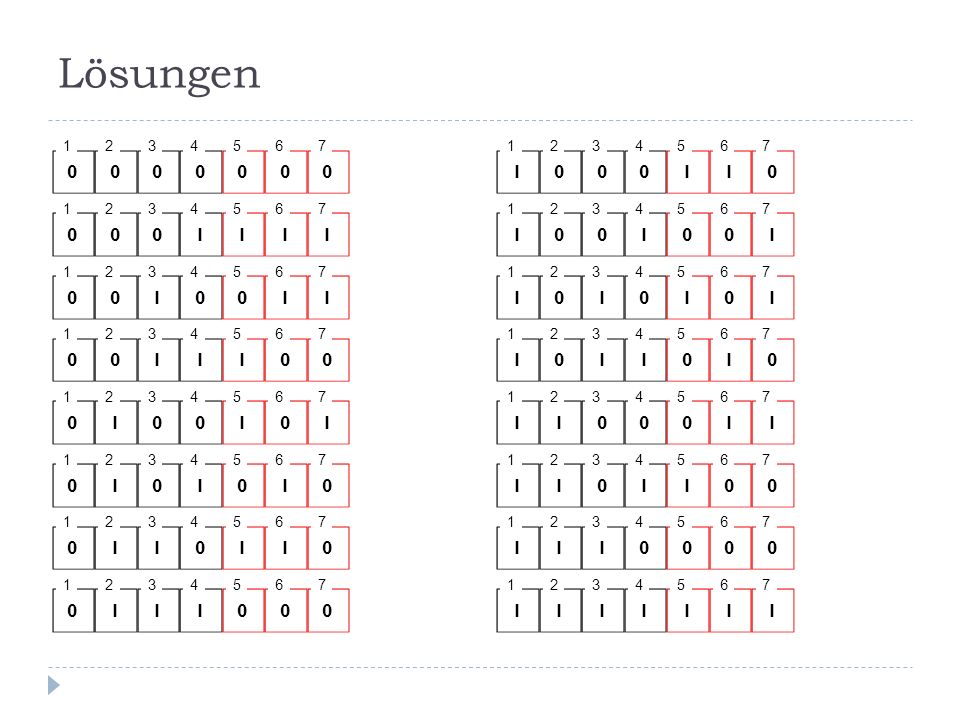
94
HD = n Bit Unterschied (4 Daten-Bit)
1 2 3 4 5 6 7 1 2 3 4 5 6 7 HD = 1 HD = 1 1 2 3 4 5 6 7 1 2 3 4 5 6 7 HD = 1 HD = 1 1 2 3 4 5 6 7 1 2 3 4 5 6 7 HD = 1 HD = 1 1 2 3 4 5 6 7 1 2 3 4 5 6 7 HD = 1 HD = 1 1 2 3 4 5 6 7 1 2 3 4 5 6 7 HD = 1 HD = 1 1 2 3 4 5 6 7 1 2 3 4 5 6 7 HD = 1 HD = 1 1 2 3 4 5 6 7 1 2 3 4 5 6 7 HD = 1 HD = 1 1 2 3 4 5 6 7 1 2 3 4 5 6 7

95
n Bit Unterschied (7 Bit Hamming Code)
1 2 3 4 5 6 7 1 2 3 4 5 6 7 HD = 4 HD = 4 1 2 3 4 5 6 7 1 2 3 4 5 6 7 HD = 3 HD = 3 1 2 3 4 5 6 7 1 2 3 4 5 6 7 HD = 4 HD = 4 1 2 3 4 5 6 7 1 2 3 4 5 6 7 HD = 4 HD = 4 1 2 3 4 5 6 7 1 2 3 4 5 6 7 HD = 4 HD = 4 1 2 3 4 5 6 7 1 2 3 4 5 6 7 HD = 4 HD = 3 1 2 3 4 5 6 7 1 2 3 4 5 6 7 HD = 4 HD = 4 1 2 3 4 5 6 7 1 2 3 4 5 6 7

96
Hamming-Distanz (HD) Definition Hamming-Distanz:
1 2 3 4 5 6 7 1 1 2 3 1 4 1 5 6 7 HD = 1 HD = 3 1 2 3 4 5 6 7 1 1 2 1 3 1 4 1 5 1 6 1 7 Definition Hamming-Distanz: n Stellen Unterschied zwischen zwei Zeichen (hier Bit) Hamming-Distanz als Eigenschaft eines Codes: Minimale HD zwischen zwei (gültigen) Codewörtern
 Hamming-Distanz als Eigenschaft eines Codes: Minimale HD zwischen zwei (gültigen) Codewörtern.")
97
Der (7,4)Hamming Code Korrektur: ? Bitflips Erkennung: ? Bitflips
... verteilt die 16 (24 Bit) ursprüng- lichen Codewörter so auf die 7 Bit, dass eine HD = 3 garantiert ist 1 Bitflip kann korrigiert werden 2 Bitflips können erkannt werden Allgemein, in Anhängigkeit von der HD des Codes Korrektur: ? Bitflips Erkennung: ? Bitflips
 ursprüng- lichen Codewörter so auf die 7 Bit, dass eine HD = 3 garantiert ist. 1 Bitflip kann korrigiert werden. 2 Bitflips können erkannt werden. Allgemein, in Anhängigkeit von der HD des Codes. Korrektur: Bitflips. Erkennung: Bitflips.")
98
Der (7,4)Hamming Code Korrektur: HD/2 - 1 Bitflips
... verteilt die 16 (24 Bit) ursprüng- lichen Codewörter so auf die 7 Bit, dass eine HD = 3 garantiert ist 1 Bitflip kann korrigiert werden 2 Bitflips können erkannt werden Allgemein, in Anhängigkeit von der HD des Codes Korrektur: HD/2 - 1 Bitflips Erkennung: HD - 1 Bitflips
 ursprüng- lichen Codewörter so auf die 7 Bit, dass eine HD = 3 garantiert ist. 1 Bitflip kann korrigiert werden. 2 Bitflips können erkannt werden. Allgemein, in Anhängigkeit von der HD des Codes. Korrektur: HD/2 - 1 Bitflips. Erkennung: HD - 1 Bitflips.")
99
Erkennen & Korrigieren geht nicht gleichzeitig. Warum?
Der erweiterte (8,4)Hamming-Code mit HD = 4 kann den einzelnen (korrigierbaren) Flip vom doppelten (nicht korrigierbaren) unterscheiden 100 % Redundanz für 25% Korrekturleistung Lohnt sich das? (und ist das richtig gerechnet?)
Hamming-Code mit HD = 4 kann den einzelnen (korrigierbaren) Flip vom doppelten (nicht korrigierbaren) unterscheiden. 100 % Redundanz für 25% Korrekturleistung. Lohnt sich das (und ist das richtig gerechnet )")
100
Lohnt sich das? Resultat für 1% Flip-Wahrscheinlichkeit pro Bit:
P für ein Bit, geflippt zu werden Anzahl Bits Eines von 4 Bit ist geflippt P für genau einen Flip P für keinen Flip P für einen oder keinen Flip P für mehr als einen Flip P für einen oder mehr Flips Resultat für 1% Flip-Wahrscheinlichkeit pro Bit: In ~96% der 4-Bit Sequenzen gibt es sowieso keinen Fehler In ~3.9% gibt es einen Fehler kann korrigiert werden In ~0.06% gibt es mehr als einen Fehler keine Korrektur möglich

101
Lohnt sich das? Resultat für 0.01% Flip-Wahrscheinlichkeit pro Bit:
P für ein Bit, geflippt zu werden Anzahl Bits Eines von 4 Bit ist geflippt P für genau einen Flip P für keinen Flip P für einen oder keinen Flip P für mehr als einen Flip P für einen oder mehr Flips Resultat für 0.01% Flip-Wahrscheinlichkeit pro Bit: In ~99.96% der 4-Bit Sequenzen gibt es sowieso keinen Fehler In ~0.039% gibt es einen Fehler kann korrigiert werden In ~ % gibt es mehr als einen Fehler keine Korrektur

102
Wie viel Redundanz lohnt sich?
Besser: In welchen Fällen lohnt sich (viel) Redundanz? Parameterkombinationen bei Hamming-Codes (HD = 3) n k N = n + k Datenbits (Datenwort) Paritybits (Kontrollstellen) Gesamtlänge des Codewortes 1 2 3 4 7 11 15 26 5 31 57 6 63 120 127 247 8 255
 Redundanz Parameterkombinationen bei Hamming-Codes (HD = 3) n. k. N = n + k. Datenbits (Datenwort) Paritybits (Kontrollstellen) Gesamtlänge des Codewortes")
103
Reale Anwendungen reine Hamming-Codes (inzwischen) selten
in manchen WLAN-Standards zur Korrektur von Speicheradressen Noch etwas komplizierter – obwohl basierend auf denselben Grundprinzipien – ist beispielsweise die Fehlerkorrektur auf CDs oder DVDs Cross-Interleaved Reed-Solomon Code (CIRC) (ab 3:10) Solomon%20Encoding%20and%20Decoding.pdf?sequence=1
 v=sYO6vm9PTsI (ab 3:10) Solomon%20Encoding%20and%20Decoding.pdf sequence=1.")
104
Cross-Interleaved Reed-Solomon Code
24 Byte 28 Byte 32 Byte

105
Performance of CIRC (256(+),192)
Both R-S coders (C1 and C2) have four parities, and their minimum distance is 5 If error location is not known, up to two symbols can be corrected. If the errors exceed the correction limit, they are concealed by interpolation. Since even-numbered sampled data and odd-numbered sampled data are interleaved as much as possible, CIRC can conceal long burst errors by simple linear interpolation. Max. completely correctable burst length is about 4000 data bits (2.5 mm track length). Max. interpolatable burst length in the worst case is about 12,3000 data bits (7.7 mm track length). Sample interpolation rate is one sample every 10 hours at BER 10-4 (Bit Error Rate) at and 1000 samples per minute at BER 10-3 Undetectable error samples (clicks) less than one every 750 hours at BER = and negligible BER =
 have four parities, and their minimum distance is 5. If error location is not known, up to two symbols can be corrected. If the errors exceed the correction limit, they are concealed by interpolation. Since even-numbered sampled data and odd-numbered sampled data are interleaved as much as possible, CIRC can conceal long burst errors by simple linear interpolation. Max. completely correctable burst length is about 4000 data bits (2.5 mm track length). Max. interpolatable burst length in the worst case is about 12,3000 data bits (7.7 mm track length). Sample interpolation rate is one sample every 10 hours at BER 10-4 (Bit Error Rate) at and 1000 samples per minute at BER Undetectable error samples (clicks) less than one every 750 hours at BER = 10-3 and negligible BER =")
106
Formate, Codes & Algorithmen
Definitionen und Zusammenhänge

107
Und wie passt das alles zusammen?
Format Information Codierung

108
Komprimierung allgemein
originale Nachricht (Bitsequenz) codierte Nachricht + Liste Komprimieren, z.B. mit Huffman Codierung Dekomprimieren, z.B. mit Huffman Decodierung speichern /verschicken
 codierte Nachricht + Liste. Komprimieren, z.B. mit Huffman Codierung. Dekomprimieren, z.B. mit Huffman Decodierung. speichern /verschicken.")
109
Codieren Nicht-digitale Information Nicht-digitale Information
Entdigitalisieren?! Darstellen Digitalisieren Komprimieren Komprimierte digitale Information Entkomprimieren Beispiel:„Fischers Fritz fischt frische...“ Digitale Information Digitale Information

110
Codieren allgemein Nicht-digitale Information
Entdigitalisieren?! Darstellen Digitalisieren Komprimieren Komprimierte digitale Information Entkomprimieren „Fischers Fritz fischt frische...“ Digitale Information Digitale Information

111
Codieren allgemein Nicht-digitale Information
Entdigitalisieren?! Darstellen Digitalisieren Verschlüsseln Verschlüsselte digitale Information Entschlüsseln Digitale Information Digitale Information

112
Codieren allgemein Format Format Format Nicht-digitale Information
Entdigitalisieren?! Darstellen Digitalisieren Format Digitale Information Digitale Information Komprimieren Kompr. Information Entkomprimieren Format Verschlüsseln Entschlüsseln Verschlüsselte Information Verschlüsselte Information Format

113
Definition Code:

114
Definition von Code, lang
Im Allgemeinen ist ein Code eine Vereinbarung über einen Satz (eine Menge) von Symbolen (Bedeutungsträgern, oder Verweisen) zum Zweck des Informationsaustauschs. Information existiert nicht in „reiner“ Form; sie ist immer in irgendeiner Weise formuliert. Ein Code ist – allgemein ausgedrückt – eine Formulierung von Information. Das setzt folgende Elemente voraus: mindestens eine informationsformulierende Instanz (Aufzeichner/Sender) mindestens eine informationsempfangende Instanz (Lesender/Empfänger) – kann unter Umständen auch identisch mit (1) sein ein zu übermittelnder, abstrakter Inhalt, die Information eine Vereinbarung zum Zweck der Informationsformulierung und gegebenenfalls Informationsübermittlung. Diese enthält einen Satz von Bedeutungsträgern oder Symbolen, der beiden Instanzen (1) und (2) bekannt ist, und gegebenenfalls Regeln zur Verwendung der Symbole
 von Symbolen (Bedeutungsträgern, oder Verweisen) zum Zweck des Informationsaustauschs. Information existiert nicht in „reiner Form; sie ist immer in irgendeiner Weise formuliert. Ein Code ist – allgemein ausgedrückt – eine Formulierung von Information. Das setzt folgende Elemente voraus: mindestens eine informationsformulierende Instanz (Aufzeichner/Sender) mindestens eine informationsempfangende Instanz (Lesender/Empfänger) – kann unter Umständen auch identisch mit (1) sein. ein zu übermittelnder, abstrakter Inhalt, die Information. eine Vereinbarung zum Zweck der Informationsformulierung und gegebenenfalls Informationsübermittlung. Diese enthält einen Satz von Bedeutungsträgern oder Symbolen, der beiden Instanzen (1) und (2) bekannt ist, und gegebenenfalls Regeln zur Verwendung der Symbole.")
115
Definition von Code, kurz
Beispiele für Codes: Ein Code ist eine Anleitung, um Zeichen eines Zeichensystems in die eines anderen zu übertragen. Ein Code definiert eine Umformulierung von Information Morse Code ASCII Code Huffman Codierung Hamming Code Binärcode Quellcode Genetischer Code Neuronaler Code Schrift Sprache ...

116
Wozu Information umformulieren?
Damit ein spezieller Empfänger sie verstehen kann, z.B. Übersetzung in andere Sprache, Digitalisieren, Drucken... Um bestimmte Übertragungswege oder Speichermedien zu nutzen, z.B. Morsen, Telefonieren, Bücher, Fotos, ... Um Platz zu sparen, z.B. DNA, Komprimierung, Datenübertragung... Um Fehler bei der Übertragung zu vermeiden, z.B. DNARNA, Hamming Code... Um Inhalte vor Unbefugten zu verstecken, z.B. Geheimsprachen, Verschlüsselung...

117
Definitionen Information ist in der Informationstheorie eine Teilmenge an Wissen, die ein Sender einem Empfänger mithilfe eines bestimmten Mediums übermittelt. Ein Dateiformat definiert die Syntax und Semantik von Daten innerhalb einer Datei. Es stellt damit eine bidirektionale Abbildung von Information auf einen eindimensionalen binären Speicher dar. Ein Code ist eine Vorschrift, die jedem Zeichen eines Zeichenvorrats (Urbildmenge) eindeutig ein Zeichen oder eine Zeichenfolge aus einem möglicherweise anderen Zeichenvorrat (Bildmenge) zuordnet. Ein Algorithmus ist eine eindeutige Handlungsvorschrift zur Lösung eines Problems oder einer Klasse von Problemen. Algorithmen bestehen aus endlich vielen, wohldefinierten Einzelschritten.
 eindeutig ein Zeichen oder eine Zeichenfolge aus einem möglicherweise anderen Zeichenvorrat (Bildmenge) zuordnet. Ein Algorithmus ist eine eindeutige Handlungsvorschrift zur Lösung eines Problems oder einer Klasse von Problemen. Algorithmen bestehen aus endlich vielen, wohldefinierten Einzelschritten.")
118
Informatik = Automatische Informationsverarbeitung
Computer machen eigentlich nichts anderes als Information mithilfe von Codes unter Anwendung von Algorithmen von einem Format in das andere umzuwandeln damit diese Information gespeichert, transportiert, verschlüsselt, dargestellt, extrahiert, verglichen, zusammengeführt, ... allgemein: verarbeitet werden kann Achtung! Codes können Information mit oder ohne Informationsverlust umwandeln. Je nach Zweck können „unwichtige“ Information verloren geht – z.B. weil man den Unterschied sowieso kaum bemerkt (.jpg) oder weil man nur an bestimmten Aspekten der Daten interessiert ist (der grösste Wert, die Richtigkeit einer Antwort, etc.) – oder es werden sogar zusätzliche generiert – z.B. Redundanz für Fehlererkennung oder –korrektur.
 oder weil man nur an bestimmten Aspekten der Daten interessiert ist (der grösste Wert, die Richtigkeit einer Antwort, etc.) – oder es werden sogar zusätzliche generiert – z.B. Redundanz für Fehlererkennung oder –korrektur.")
119
Suchen (in Theorie und Praxis)
Algorithmik Suchen (in Theorie und Praxis)
")
120
Konzepte Beispiele lineare Suche binäre Suche binäre Suche rekursiv
Struktogramme Suchalgorithmen (Laufzeit-)Komplexität Komplexitätsklassen O-Notation Softwareentwicklung Wasserfallmodell iterative development test driven development Divide & Conquer Iteration Rekursion lineare Suche binäre Suche binäre Suche rekursiv jUnit-tests NetBeans/Eclipse
Komplexität. Komplexitätsklassen. O-Notation. Softwareentwicklung. Wasserfallmodell. iterative development. test driven development. Divide & Conquer. Iteration. Rekursion. lineare Suche. binäre Suche. binäre Suche rekursiv. jUnit-tests. NetBeans/Eclipse.")
121
Struktogramme Nassi-Shneiderman-Diagramm zur Darstellung von (Programm)Abläufen
Verbale Beschreibung Struktogramm (JAVA) Code Maschinencode
 Code. Maschinencode.")
123
Lineare Suche Wir haben eine Namensliste (a) und wollen wissen, ob ein bestimmter Name (g) darin vorkommt. und jetzt? Entwickeln Sie einen geeigneten Algorithmus als Struktogramm Kerim Alexandra Lorenz Julian Samuel Niruban Aymar Joël Slavko Manuel Nathanael Anselm Niko

124
Algorithmus Lineare Suche
Worst case? Laufzeit n = 10? n = 20? n = 100? allgemein? O(n) (n verdoppeln ver- doppelt Laufzeit)
 (n verdoppeln ver- doppelt Laufzeit)")
125
Algorithmus Binäre Suche
Worst case? Laufzeit n = 10? n = 20? n = 100? allgemein? O()
")
126
Algorithmus Binäre Suche (rekursiv)
Worst case? Laufzeit n = 10? n = 20? n = 100? allgemein? O()
")
127
Komplexität von Suchalgorithmen
Bei der Linearen Suche ist es egal, ob der Datenbestand schon sortiert ist, oder nicht: n Datenzugriffe für eine erfolglose Suche (worst case) 1 Datenzugriff im best case (sehr unwahrscheinlich) im Mittel (average case) n/2 Dateizugriffe Lineare Suche: O(n) Die Binäre Suche funktioniert nur mit sortierten Daten: kann iterativ oder rekursiv implementiert werden 1 Listenspaltung mehr für doppelte Länge Binäre Suche: O(log(n)) Interpolationssuche: O(log(log(n))
 1 Datenzugriff im best case (sehr unwahrscheinlich) im Mittel (average case) n/2 Dateizugriffe. Lineare Suche: O(n) Die Binäre Suche funktioniert nur mit sortierten Daten: kann iterativ oder rekursiv implementiert werden. 1 Listenspaltung mehr für doppelte Länge. Binäre Suche: O(log(n)) Interpolationssuche: O(log(log(n))")
128
Exkurs Software Development

129
Wasserfallmodell Requirements Design Implementation Verification
Maintenance

130
Iterative Development
Design Implementation Testing Evaluation Planning Requirements Initial Idea Iteration Deployment

131
Test Driven Development
In Java: JUnit (s. cheatsheet) Design Implementation Testing (automated) Evaluation Planning Requirements (as Tests) run test and see if it fails write code to cover the test run again and see if it passes refactor add a test Initial Idea Deployment
 Design. Implementation. Testing. (automated) Evaluation. Planning. Requirements. (as Tests) run test and see if it fails. write code to cover the test. run again and see if it passes. refactor. add a test. Initial Idea. Deployment.")
132
Schlussfolgerungen: Mehrstufige Grobplanung
Detailüberlegungen nur für die gegenwärtige Stufe – nicht zu weit voraus planen Tests für alles, was nicht trivial ist Tests als erstes Formulierung der Anforderungen, explizite Zielvorstellung Jeweils nur an einem Problem arbeiten – auch hier helfen Tests, nacheinander abarbeiten Keine Angst vor refactoring/überarbeiten – Werkzeuge benutzen

133
Sortieren & Komplexität
Algorithmik Sortieren & Komplexität

134
Konzepte Beispiele bubblesort insertionsort selectionsort quicksort
Sortieralgorithmen (Laufzeit-)Komplexität Komplexitätsklassen O-Notation Divide & Conquer Iteration Rekursion bubblesort insertionsort selectionsort quicksort mergesort
Komplexität. Komplexitätsklassen. O-Notation. Divide & Conquer. Iteration. Rekursion. bubblesort. insertionsort. selectionsort. quicksort. mergesort.")
135
Einfache Sortierverfahren
AB_EinfacheSortierverfahren.pdf

136
Komplexität (Zeitkomplexität)
Unter der Zeitkomplexität eines Problems versteht man die Anzahl der Rechenschritte, die ein optimaler Algorithmus zur Lösung dieses Problems benötigt, in Abhängigkeit von der Länge der Eingabe. Man spricht hier auch von der asymptotischen Laufzeit und meint damit, in Anlehnung an eine Asymptote, das Zeitverhalten des Algorithmus für eine potenziell unendlich große Eingabemenge. Es interessiert also nicht der Zeitaufwand eines konkreten Programms auf einem bestimmten Computer, sondern viel mehr, wie der Zeitbedarf wächst, wenn mehr Daten zu verarbeiten sind, also z.B. ob sich der Aufwand für die doppelte Datenmenge verdoppelt oder quadriert (Skalierbarkeit).
.")
137
Machbarkeitsüberlegungen
Angenommen: Im Test zeigt sich, dass ein Programm für 10 Datenwerte 1 sec benötigt Wenn der Algorithmus Komplexität O(f(n)) hat, wie viele Eingabedaten kann er in 1 Tag, 1 Jahr, 10 Jahren, 1000 Jahren verarbeiten?
) hat, wie viele Eingabedaten kann er in 1 Tag, 1 Jahr, 10 Jahren, 1000 Jahren verarbeiten")
138
Laufzeitabschätzung Wir betrachten, wie viele Schritte im Algorithmus abgearbeitet werden müssen - abhängig von der Menge der Eingabedaten. Kerim Alexandra Lorenz Julian Samuel Niruban Aymar Joël Slavko Manuel Nathanael Anselm Niko Beispiel 1: Wir haben eine Namensliste und wollen wissen, ob ein bestimmter Name darin vorkommt. und jetzt?

139
Laufzeitabschätzung Lösung (Algorithmus) finden
Für den ungünstigsten Fall (worst case) durchspielen Laufzeit abschätzen (O-Notation) Kerim Alexandra Lorenz Julian Samuel Niruban Aymar Joël Slavko Manuel Nathanael Anselm Niko
 durchspielen. Laufzeit abschätzen (O-Notation) Kerim. Alexandra. Lorenz. Julian. Samuel. Niruban. Aymar. Joël. Slavko. Manuel. Nathanael. Anselm. Niko.")
140
O-Notation Wir betrachten, wie sich die Schrittanzahl im Algorithmus für eine sehr grosse Anzahl von Eingabedaten verhält („obere Schranke“ für Worst Case). Beispiel Namensliste: Für n Eingabedaten brauchen wir sicher nicht mehr als (n-1)+(n-2)+…+(1) = Schritte. (n-1)+(n-2)+…+(1) = n2 Schritte. …+ (n-1) Schreibweise: Laufzeit_Namensliste = O(n2)
. Beispiel Namensliste: Für n Eingabedaten brauchen wir sicher nicht mehr als. (n-1)+(n-2)+…+(1) = Schritte. (n-1)+(n-2)+…+(1) = n2 Schritte …+ (n-1) Schreibweise: Laufzeit_Namensliste = O(n2)")
141
O-Notation Vereinfachungsregeln:
Addition f(n) = n + 3 ⇒ O(n) f(n) = n2 + 3n ⇒ O(n2) Multiplikation f(n) = 3n ⇒ O(n) f(n) = n2 * 3n ⇒ O(n3) Konstante Summanden werden vernachlässigt Es zählt der Summand mit dem stärkeren Wachstum Konstante Faktoren werden vernachlässigt Es zählt die Summe der Exponenten
 = n + 3 ⇒ O(n) f(n) = n2 + 3n ⇒ O(n2) Multiplikation f(n) = 3n ⇒ O(n) f(n) = n2 * 3n ⇒ O(n3) Konstante Summanden werden vernachlässigt Es zählt der Summand mit dem stärkeren Wachstum Konstante Faktoren werden vernachlässigt Es zählt die Summe der Exponenten.")
142
Komplexitätsabschätzung
worst-case complexity die Betriebsmittel, die maximal zur Ausführung eines Algorithmus benötigt werden. average-case complexity durchschnittlicher Betriebsmittelbedarf für alle Eingaben. Dieser wird als Komplexität des Algorithmus im Durchschnittsfall bezeichnet. best-case complexity Betriebsmittelbedarf im günstigsten Fall

143
Komplexitätsklassen O(2n) : Klasse aller exponentiellen Algorithmen
Algorithmen, die ihre Lösung durch systematisches Ausprobieren finden Beispiel: Wie packt man möglichst viele verschieden große Quader in einen Waggon? Hoffnungslos ineffizient für große n O(nk) : Klasse aller polynomialen Algorithmen Gelten als „noch praktikable“ Algorithmen O(n2) : Klasse aller quadratischen Algorithmen Einfache Sortieralgorithmen sind quadratisch (bubbleSort, insertionSort, selectionSort) O(n*log(n)) : loglineare Algorithmen Gute Sortieralgorithmen sind loglinear (quickSort ) O(n) : Klasse aller linearen Algorithman sehr gut behandelbare Algorithmen Beispiel: lineare Suche O(log(n)) : logarithmische Algorithmen Extrem effizient Beispiel: binäre Suche O(1) : Klasse aller konstanten Algorithmen Laufzeit unabhängig von Datengrösse
 : Klasse aller polynomialen Algorithmen. Gelten als „noch praktikable Algorithmen. O(n2) : Klasse aller quadratischen Algorithmen. Einfache Sortieralgorithmen sind quadratisch (bubbleSort, insertionSort, selectionSort) O(n*log(n)) : loglineare Algorithmen. Gute Sortieralgorithmen sind loglinear (quickSort ) O(n) : Klasse aller linearen Algorithman. sehr gut behandelbare Algorithmen. Beispiel: lineare Suche. O(log(n)) : logarithmische Algorithmen. Extrem effizient. Beispiel: binäre Suche. O(1) : Klasse aller konstanten Algorithmen. Laufzeit unabhängig von Datengrösse.")
144
Komplexitätsklassen

145
Komplexitätsklassen noch praktikabel nicht mehr praktikabel

146
Iteration Die Iteration (von lateinisch iterare, "wiederholen") ist ein Begriff aus der Mathematik und bezeichnet eine Methode, sich der Lösung eines Rechenproblems schrittweise, aber zielgerichtet anzunähern durch wiederholte Anwendung desselben Rechenverfahrens. In der Informatik wird auch von Iteration gesprochen, wenn man mit allen Elementen eines Arrays arbeiten will und sie dazu nacheinander anspricht, also (mithilfe einer Schleife) durch den Array „iteriert“
 ist ein Begriff aus der Mathematik und bezeichnet eine Methode, sich der Lösung eines Rechenproblems schrittweise, aber zielgerichtet anzunähern durch wiederholte Anwendung desselben Rechenverfahrens. In der Informatik wird auch von Iteration gesprochen, wenn man mit allen Elementen eines Arrays arbeiten will und sie dazu nacheinander anspricht, also (mithilfe einer Schleife) durch den Array „iteriert")
147
Iteration als Struktogramm
Die FOR-Schleife besteht aus einem Verarbeitungsteil und einem Steuerungsteil mit einer Bedingung. Die Bedingung bestimmt, ob bzw. wie häufig der Verarbeitungsteil ausgeführt wird, wenn das Programmkonstrukt durchlaufen wird.

148
Rekursion Rekursion, auch Rekurrenz oder Rekursivität, bedeutet Selbstbezüglichkeit (von lateinisch recurrere = „zurücklaufen“). Sie tritt immer dann auf, wenn etwas auf sich selbst verweist. Ein rekursives Element muss nicht immer direkt auf sich selbst verweisen (direkte Rekursion), eine Rekursion kann auch über mehrere Zwischenschritte entstehen. Rekursion kann dazu führen, dass merkwürdige Schleifen entstehen. So ist z.B. der Satz „Dieser Satz ist unwahr“ rekursiv, da er von sich selber spricht. Eine etwas subtilere Form der Rekursion (indirekte Rekursion) kann auftreten, wenn zwei Dinge gegenseitig aufeinander verweisen. Ein Beispiel sind die beiden Sätze: „Der folgende Satz ist wahr“ und „Der vorhergehende Satz ist nicht wahr“.
. Sie tritt immer dann auf, wenn etwas auf sich selbst verweist. Ein rekursives Element muss nicht immer direkt auf sich selbst verweisen (direkte Rekursion), eine Rekursion kann auch über mehrere Zwischenschritte entstehen. Rekursion kann dazu führen, dass merkwürdige Schleifen entstehen. So ist z.B. der Satz „Dieser Satz ist unwahr rekursiv, da er von sich selber spricht. Eine etwas subtilere Form der Rekursion (indirekte Rekursion) kann auftreten, wenn zwei Dinge gegenseitig aufeinander verweisen. Ein Beispiel sind die beiden Sätze: „Der folgende Satz ist wahr und „Der vorhergehende Satz ist nicht wahr .")
149
Rekursion zur Problemlösung
Als Rekursion bezeichnet man den Aufruf oder die Definition einer Funktion durch sich selbst. Ohne geeignete Abbruchbedingung geraten solche rückbezüglichen Aufrufe in einen so genannten infiniten Regress (umgangssprachlich Endlosschleife). In vielen Fällen ist die Rekursion eine von mehreren möglichen Problemlösungsstrategien, sie führt oft zu „eleganten“ mathematischen Lösungen.
. In vielen Fällen ist die Rekursion eine von mehreren möglichen Problemlösungsstrategien, sie führt oft zu „eleganten mathematischen Lösungen.")
150
Rekursion als Struktogramm
Unter Rekursion versteht man ein LÖSUNGSVERFAHREN, in der Mathematik und Informatik, bei dem ein Problem derart gelöst wird, dass man es auf das selbe, aber etwas vereinfachte Problem zurückführt. Ein Problem wird auf ein „kleineres“ Problem zurückgeführt, das wiederum nach demselben Verfahren bearbeitet wird. Die Lösung des Gesamtproblems kann sich aus mehreren Teilproblemen zusammenstellen Kann aber die Lösung eines Teilproblems sein. Für n=2 muss man sich vorstellen jede Puppe enthält 2 Puppen 150

151
Wesentliche Bestandteile einer Rekursion
Die Abbruchbedingung gibt an, welche Bedingung erfüllt sein muss, damit das Lösungsverfahren beendet wird. Die Reduktion gibt an, wie ein Problem auf ein gleichartiges, aber einfacheres Problem zurück zu führen ist. ABBRUCHBEDINGUNG REDUKTION Das Vorhanden sein der Abbruchbedingung garantiert nicht Abbruch. Zweck der Reduktion ist es, das Problem der Lösung bzw. Abbruchbedingung näher zu führen. SELBSTAUFRUF 151

152
Teile & Herrsche (divide & conquer)
Falls ein Problem für eine direkte Lösung zu umfangreich ist, dann: teile das Problem in mindestens zwei, ungefähr gleich grosse Teilprobleme (divide). löse die kleineren, einfacheren Teilprobleme (elementare Probleme) auf die gleiche Art (conquer). füge die Teillösungen zu einer Gesamtlösung zusammen (merge) Teile und herrsche“ ist eines der wichtigsten Prinzipien für effiziente Algorithmen. Dabei wird ausgenutzt, dass bei vielen Problemen der Lösungsaufwand sinkt, wenn man das Problem in kleinere Teilprobleme zerlegt ( reduzierte Komplexität). Dies lässt sich meist durch Rekursive Programmierung umsetzen.
. löse die kleineren, einfacheren Teilprobleme (elementare Probleme) auf die gleiche Art (conquer). füge die Teillösungen zu einer Gesamtlösung zusammen (merge) Teile und herrsche ist eines der wichtigsten Prinzipien für effiziente Algorithmen. Dabei wird ausgenutzt, dass bei vielen Problemen der Lösungsaufwand sinkt, wenn man das Problem in kleinere Teilprobleme zerlegt ( reduzierte Komplexität). Dies lässt sich meist durch Rekursive Programmierung umsetzen.")
153
Mergesort s. Mergesort.ppt Laufzeit?

154
Quicksort s. Farben-Quicksort.ppt Laufzeit?

155
Backtracking Suchen in Bäumen
![]()
156
Baumbegriffe Der Suchraum ist die Menge aller für ein Problem bestehenden Lösungskandidaten. Der Suchbaum erzeugt den Suchraum und ermöglicht eine Ordnung. Wurzel Kante Vater (innerer) Knoten Blatt Sohn
 Knoten. Blatt. Sohn.")
157
Suchraum für Mini-Sudoku
Hier: 4^3 = 64 Möglichkeiten Anzahl möglicher Sudokus? Mini (4er): Komplett (9er):
: Komplett (9er):")
158
Möglichkeiten für ein Tennismatch? (drei Gewinnsätze)
")
159
Triple Zeichnen Sie einen Suchbaum, der alle Möglichkeiten generiert, wie aus der Zahlenmenge M = {1, 2, 3, 4, 5, 6} Tripel (i, j, k) zusammengesetzt werden können, so dass jede Zahl um mindestens 2 grösser als ihr Vorgänger ist Beschreiben Sie zu beiden Bäumen einen Algorithmus (als Struktogramm), der die Kindknoten eines inneren Knotens generiert
 zusammengesetzt werden können, so dass jede Zahl um mindestens 2 grösser als ihr Vorgänger ist. Beschreiben Sie zu beiden Bäumen einen Algorithmus (als Struktogramm), der die Kindknoten eines inneren Knotens generiert.")
160
Permutationen a) Schreiben Sie ein Programm, das Ihnen alle vierstelligen Zahlen ausgibt, die mit den Ziffern 1,2,3 gebildet werden können. b) Wie kann das Programm erweitert werden, so dass es ohne grosse Änderung für n-stellige Zahlen (mit den gleichen Ziffern 1,2,3) funktioniert?
 Wie kann das Programm erweitert werden, so dass es ohne grosse Änderung für n-stellige Zahlen (mit den gleichen Ziffern 1,2,3) funktioniert")
161
Lösung a) int[] zahl = new int[4]; int i, j, k, l; for (i=1; i<=3; i++) { zahl[0]= i; for (j=1; j<=3; j++) { zahl[1] = j; for (k=1; k<=3; k++) { zahl[2] = k; for (l=1; l<=3; l++) { zahl[3] = l; // Ausgabe des Arrays println(join(nf(zahl, 0), ",␣")); } }
 { zahl[0]= i; for (j=1; j<=3; j++) { zahl[1] = j; for (k=1; k<=3; k++) { zahl[2] = k; for (l=1; l<=3; l++) { zahl[3] = l; // Ausgabe des Arrays println(join(nf(zahl, 0), ,␣ )); } }")
162
Lösung b) int[] zahl = new int[4]; // global definiert void setup() { generiereZiffernfolge(0); } void generiereZiffernfolge(int momTiefe) { int i; for(i=1; i<=3; i++) { // Ziffern von 1 bis 3 zahl[momTiefe] = i; if (momTiefe==3) { // sind bei zahl[3], also der vierten Stelle angelangt println(join(nf(zahl, 0), ",␣")); // Ausgabe des Arrays } else { generiereZiffernfolge(momTiefe+1); //rekursiver Aufruf
 { generiereZiffernfolge(0); } void generiereZiffernfolge(int momTiefe) { int i; for(i=1; i<=3; i++) { // Ziffern von 1 bis 3 zahl[momTiefe] = i; if (momTiefe==3) { // sind bei zahl[3], also der vierten Stelle angelangt println(join(nf(zahl, 0), ,␣ )); // Ausgabe des Arrays } else { generiereZiffernfolge(momTiefe+1); //rekursiver Aufruf")
163
Lösung b) int[] zahl = new int[n]; // global definiert void setup() { generiereZiffernfolge(0); } void generiereZiffernfolge(int momTiefe) { int i; for(i=1; i<=3; i++) { // Ziffern von 1 bis 3 zahl[momTiefe] = i; if (momTiefe==n-1) { // sind bei zahl[3], also der vierten Stelle angelangt println(join(nf(zahl, 0), ",␣")); // Ausgabe des Arrays } else { generiereZiffernfolge(momTiefe+1); //rekursiver Aufruf
 { generiereZiffernfolge(0); } void generiereZiffernfolge(int momTiefe) { int i; for(i=1; i<=3; i++) { // Ziffern von 1 bis 3 zahl[momTiefe] = i; if (momTiefe==n-1) { // sind bei zahl[3], also der vierten Stelle angelangt println(join(nf(zahl, 0), ,␣ )); // Ausgabe des Arrays } else { generiereZiffernfolge(momTiefe+1); //rekursiver Aufruf")
164
Suchbäume und Rekursion
Die rekursive Programmierung eignet sich gut, um eine Baumstruktur des Suchraums aufzubauen, da sie erlaubt, nur die Anweisungen für die Generierung der Kindknoten auf einer Tiefe anzugeben. Oft übergibt man dabei eine Variable (hier momTiefe), mit deren Hilfe man die Rekursion irgendwann abbricht Es ist jedoch durchaus möglich, den Suchbaum auch iterativ (statt rekursiv) aufzubauen.
, mit deren Hilfe man die Rekursion irgendwann abbricht. Es ist jedoch durchaus möglich, den Suchbaum auch iterativ (statt rekursiv) aufzubauen.")
165
Backtracking Häufig kann ein Baum nicht direkt so konstruiert werden, dass nur Lösungen entstehen. Wir generieren dann einen grösseren Baum aller in Frage kommenden Möglichkeiten und testen diese, ob sie auch wirklich Lösungen sind. Bemerken wir beim Generieren einer Teilmöglichkeiten, dass diese unter keinen Umständen zu einer vollen Lösung ausgebaut werden kann, verfolgen wir den entsprechenden Ast im Baum auch nicht mehr weiter.
![]()
166
Damenproblem Wie viele Möglichkeiten gibt es, 8 Damen auf einem Schachbrett so aufzustellen, dass keine Dame eine andere bedroht? Struktogramm für diesen Algorithmus (rekursiv?) Wie viele Möglichkeiten hätten wir uns mit Backtracking sparen können? Etwas überschaubarer: 4 Damen auf 4x4 Brett
 Wie viele Möglichkeiten hätten wir uns mit Backtracking sparen können Etwas überschaubarer: 4 Damen auf 4x4 Brett.")
167
Sudoku mit Backtracking
Zeichnen Sie ein (grobes) Struktogramm für einen Algorithmus, der mittels Backtracking beliebige Sudokus lösen kann. Lösungsansatz: Trage alle Singletons ein. Breche ab, wenn es für eine Zelle keine Kandidaten gibt. Trage in eine leere Zelle einen Probewert ein. Rufe das Programm rekursiv auf. Applet:
![]()
168
Arrays Array: typ[] name = {Werte} Regal mit gleichartigen Kisten: name[0] Inhalt der ersten Kiste Beispiel: int[] arr = {3, 5, 0, 17}; System.out.println(arr[3]); // 17 arr[1] = 11; // an 2. Stelle 11 statt 5 int x = arr[0]; // x ist 3 int l = arr.length; // l ist 4
![Arrays Array: typ[] name = {Werte} Regal mit gleichartigen Kisten: name[0] Inhalt der ersten Kiste](http://slideplayer.org/slide/1286726/3/images/168/Arrays+Array%3A+typ%5B%5D+name+%3D+%7BWerte%7D+Regal+mit+gleichartigen+Kisten%3A+name%5B0%5D+%EF%83%A0+Inhalt+der+ersten+Kiste.jpg "Beispiel: int[] arr = {3, 5, 0, 17}; System.out.println(arr[3]); // 17 arr[1] = 11; // an 2. Stelle 11 statt 5 int x = arr[0]; // x ist 3 int l = arr.length; // l ist 4.")
169
Asymmetrische Verschlüsselung
RSA

170
Primzahltest brute force Sieb des Erostrathes Euler

171
Grösster gemeinsamer Teiler
brute force Euler Euler erweitert

172
Symmetrische Verschlüsselung
x

173
Asymmetrische Verschlüsselung
x

175
Der Sender schickt die Geheimzahl g an den Empfänger
RSA-Kryptografie Sender Empfänger Der (künftige) Empfänger wählt zwei große Primzahlen p und q und berechnet die beiden Produkte n = p*q sowie phi = (p-1)*(q-1). Außerdem wählt der Empfänger eine Zahl e, 1 < e < phi, die teilerfremd zu phi ist. Der (künftige) Empfänger berechnet außerdem ein d mit der Eigenschaft, dass e*d und phi teilerfremd sind (die Existenz eines solchen d ist gesichert, wenn e und phi teilerfremd sind) Der Empfänger veröffentlicht nur das Zahlenpaar (n, e) als seinen öffentlichen Schlüssel Die übrigen Zahlen p, q, phi und d hält der Empfänger geheim; (n, d) ist sein privater Schlüssel. Der Sender besorgt sich den öffentlichen Schlüssel (n, e) des Empfängers Der Sender verschlüsselt seine Zahl k (Klartext), indem er g = ke % n berechnet. Achtung: Damit später eine (eindeutige) Entschlüsselung möglich ist, muss k < n sein. Größere Zahlen müssen ggf. in kleinere Blöcke zerlegt und stückweise verschlüsselt werden. Der Sender schickt die Geheimzahl g an den Empfänger Der Empfänger entschlüsselt die Nachricht, indem er k = gd % n berechnet.
 Empfänger wählt zwei große Primzahlen p und q und berechnet die beiden Produkte n = p*q sowie phi = (p-1)*(q-1). Außerdem wählt der Empfänger eine Zahl e, 1 < e < phi, die teilerfremd zu phi ist. Der (künftige) Empfänger berechnet außerdem ein d mit der Eigenschaft, dass e*d und phi teilerfremd sind (die Existenz eines solchen d ist gesichert, wenn e und phi teilerfremd sind) Der Empfänger veröffentlicht nur das Zahlenpaar (n, e) als seinen öffentlichen Schlüssel. Die übrigen Zahlen p, q, phi und d hält der Empfänger geheim; (n, d) ist sein privater Schlüssel. Der Sender besorgt sich den öffentlichen Schlüssel (n, e) des Empfängers. Der Sender verschlüsselt seine Zahl k (Klartext), indem er g = ke % n berechnet. Achtung: Damit später eine (eindeutige) Entschlüsselung möglich ist, muss k < n sein. Größere Zahlen müssen ggf. in kleinere Blöcke zerlegt und stückweise verschlüsselt werden. Der Sender schickt die Geheimzahl g an den Empfänger. Der Empfänger entschlüsselt die Nachricht, indem er k = gd % n berechnet.")
176
Das Primzahlsieb des Eratosthenes
Man notiert z.B. die ersten natürlichen Zahlen, also 1, 2, 3, 4, 5, ..., , Von diesen Zahlen wird zunächst die 1 gestrichen. Dann geht man zur nächsten ungestrichenen Zahl, erklärt diese zur Primzahl, lässt sie stehen, aber streicht alle ihre Vielfachen (Konkret: 2 bleibt stehen, aber 4, 6, 8, ..., also hier alle geraden Zahlen als Vielfache von 2 -- werden gestrichen). Dann kehrt man zur letztgefundenen Primzahl zurück und geht von dort zur nächstgrößeren ungestrichenen Zahl, erklärt diese zur nächsten Primzahl, lässt sie stehen und streicht wieder ihre Vielfachen. Dies Vorgehen wird bis zum Erreichen des Endes der notierten Zahlen wiederholt.
. Dann kehrt man zur letztgefundenen Primzahl zurück und geht von dort zur nächstgrößeren ungestrichenen Zahl, erklärt diese zur nächsten Primzahl, lässt sie stehen und streicht wieder ihre Vielfachen. Dies Vorgehen wird bis zum Erreichen des Endes der notierten Zahlen wiederholt.")
177
Euklid-Algorithmus zur Bestimmung des größten gemeinsamen Teilers
Will man etwa den größten gemeinsamen Teiler von 385 und 84, also ggT(385, 84) bestimmen, so kann man 385 % 84 = 49; 84 % 49 = 35; 49 % 35 = 14; 35 % 14 = 7 und 14 % 7 = 0 berechnen. Endet die Kette bei Null, so war der Rest vorher bzw. ist der letzte Divisor das größte gemeinsame Vielfache: hier also ggT(385, 84) = 7. Im Interesse einer einfachen Programmierung setzt der folgende Algorithmus positive a und b mit a > b voraus:
 bestimmen, so kann man 385 % 84 = 49; 84 % 49 = 35; 49 % 35 = 14; 35 % 14 = 7 und 14 % 7 = 0 berechnen. Endet die Kette bei Null, so war der Rest vorher bzw. ist der letzte Divisor das größte gemeinsame Vielfache: hier also ggT(385, 84) = 7. Im Interesse einer einfachen Programmierung setzt der folgende Algorithmus positive a und b mit a > b voraus:")
Ähnliche Präsentationen






















 via Internet WWW Server.>")
